

前言
鉴于许多人的询问和关心,我们提前放出了部分初步测试结果,用以详细刻画9000s使用的TSV new(?)微架构的技术细节。
大核中核规格对比
麒麟9000s的中核相较大核有一定程度的阉割降级。主要集中于最大频率、L2 Cache容量、浮点流水线规模、乱序队列规模方面。以下数据为初步probe结果,在手动细测后会有所变动,请注意。
从频率上来看,中核最大频率为~2GHz,大核最大频率为~2.61GHz。
| 流水级宽度 | TSV110 | TSV new(middle) | TSV new(big) | Cortex A78 |
|---|---|---|---|---|
| Fetch(ICache) | 4 | 6 | 6 | 4 |
| Fetch(mop Cache) | N/A | N/A | N/A | 6 |
| Decode | 4 | 6 | 6 | 4 |
| Rename | 4 | 6 | 6 | 6 |
从主流水线宽度上来看,大核中核是一致的,他们大概率是同源微架构。整个海思微架构家族没有使用mop cache的迹象,至少mop cache没有被用于提升供指带宽。
| 执行部件数量 | TSV110 | TSV new(middle) | TSV new(big) | Cortex A78 |
|---|---|---|---|---|
| ALU | 3 | 4 | 4 | 4 |
| BRU | 2 | 2 | 2 | 2 |
| MUL | 1 | 2 | 2 | 2 |
| AGU(ld+st) | 2 | 4 | 4 | 3 |
| AGU(ld) | 2 | 2 | 2 | 3 |
| AGU(st) | 1 | 2 | 2 | 2 |
| FPU | 2 | 2 | 4 | 2 |
| FADD | 2 | 2 | 2 | 2 |
| FMUL | 2 | 2 | 4 | 2 |
| FMA | 2 | 2 | 2 | 2 |
从执行单元规格上来看,中核阉割了浮点侧规格,属于意料之中。TSV new展现出了与前作TSV110完全不同的单元配置,整数侧ALU、MUL单元有所增长;浮点侧的宽度大幅增加,延迟大幅降低。TSV new也与A78完全不同,其AGU风格为intel式的load、store全分离,而非ARM惯用的组合式。
| Cache容量 | TSV new(middle) | TSV new(big) |
|---|---|---|
| L1I | 64KB | 64KB |
| L1D | 64KB | 64KB |
| L2 | 512KB | 1MB |
| L3 (shared) | 4MB | 4MB |
| SLC (shared) | 4MB | 4MB |
从Cache规格上来看,中核缩小L2容量情理之中。9000s的L3容量过小是一大遗憾,会严重影响整数侧的性能表现,限制了TSV new发挥其全部潜力。
| TSV110 | TSV new (middle) | TSV new (big) | Cortex A78 | Cortex X1 | |
|---|---|---|---|---|---|
| ROB | ~92*n(coalesced ROB) | ~224 | ~240 | ~160 | ~216 |
| PRF(integer) | ~140 | ~160 | ~192 | ~160 | ~184 |
| PRF(float) | ~96 | ~160 | ~192 | ~92 | ~152 |
| DispatchQ+IssueQ(fix) | ~36 | ~64 | ~72 | ~56 | ~64 |
| DispatchQ+IssueQ(float) | ~28 | ~56 | ~56 | ~48 | ~56 |
| LDQ | ~48 | ~78 | ~128 | ~64 | ~80 |
| STQ | ~32 | ~54 | ~72 | ~48 | ~60 |
从乱序队列规模上来看,中核有所缩减。不过TSV new相较前代有了大幅增长,规模更接近Cortex X系列。不过较为遗憾的是,TSV110上coalesced ROB的设计巧思似乎没有延续。由于暂时没有去探究TSV new是否真实启用了SMT以及SMT的具体策略,此处容量存在误差,仅供参考。LDQ与STQ容量均未减去相关发射队列容量。ISQ容量测试时默认使用了非intel风格的probe模式。话说回来,TSV new的LDQ容量大得惊人,可能使用了什么特殊的优化提升了等效容量。受限于本人精力,各种队列的准确容量和分布方式我们就留到以后再去探究吧。
性能预览
在这一部分我们使用SPEC06、SPEC17、Coremark以及Verilator对处理器进行测试。注意,我们并不执着于fine-tune以获得某一微架构的最高分数;而是以合理、统一的编译参数带来可比的分值数据。SPEC06、SPEC17等的分值受系统环境、编译器版本、编译参数、BIOS调教、频率稳定性、具体SKU的Cache配置、具体平台的内存参数等因素影响巨大,且无法通过任何简单线性缩放进行分数推演。
我们首先总览TSV new在各种微架构中的位置:
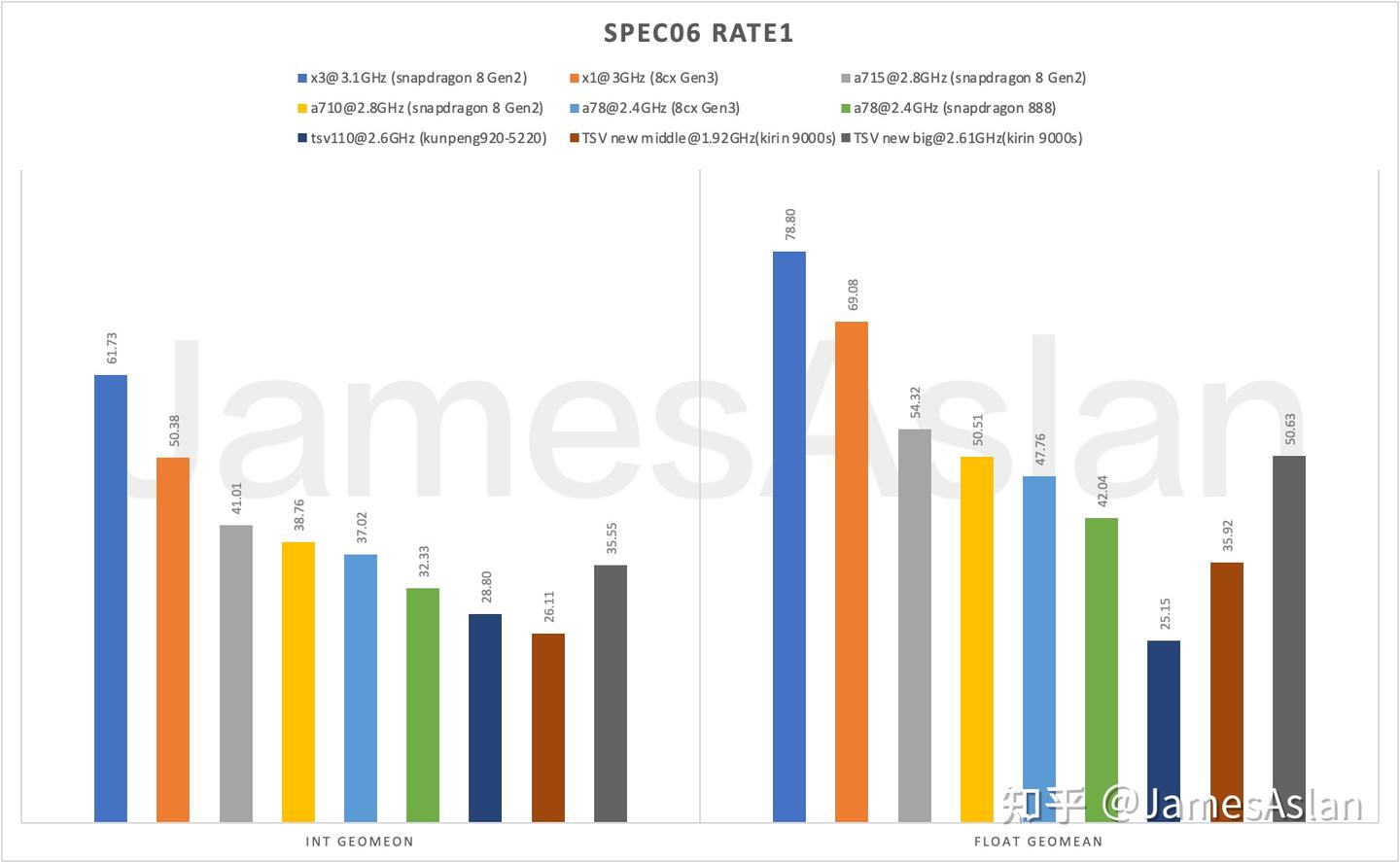
SPEC06
SPEC06是已经退役的SPEC测试集但是仍然被广泛使用;其负载特性与SPEC17并不相同,因此仍然具有相当的测试价值。
编译环境:GCC12.0 -Ofast -static
GLIBC 23.5-0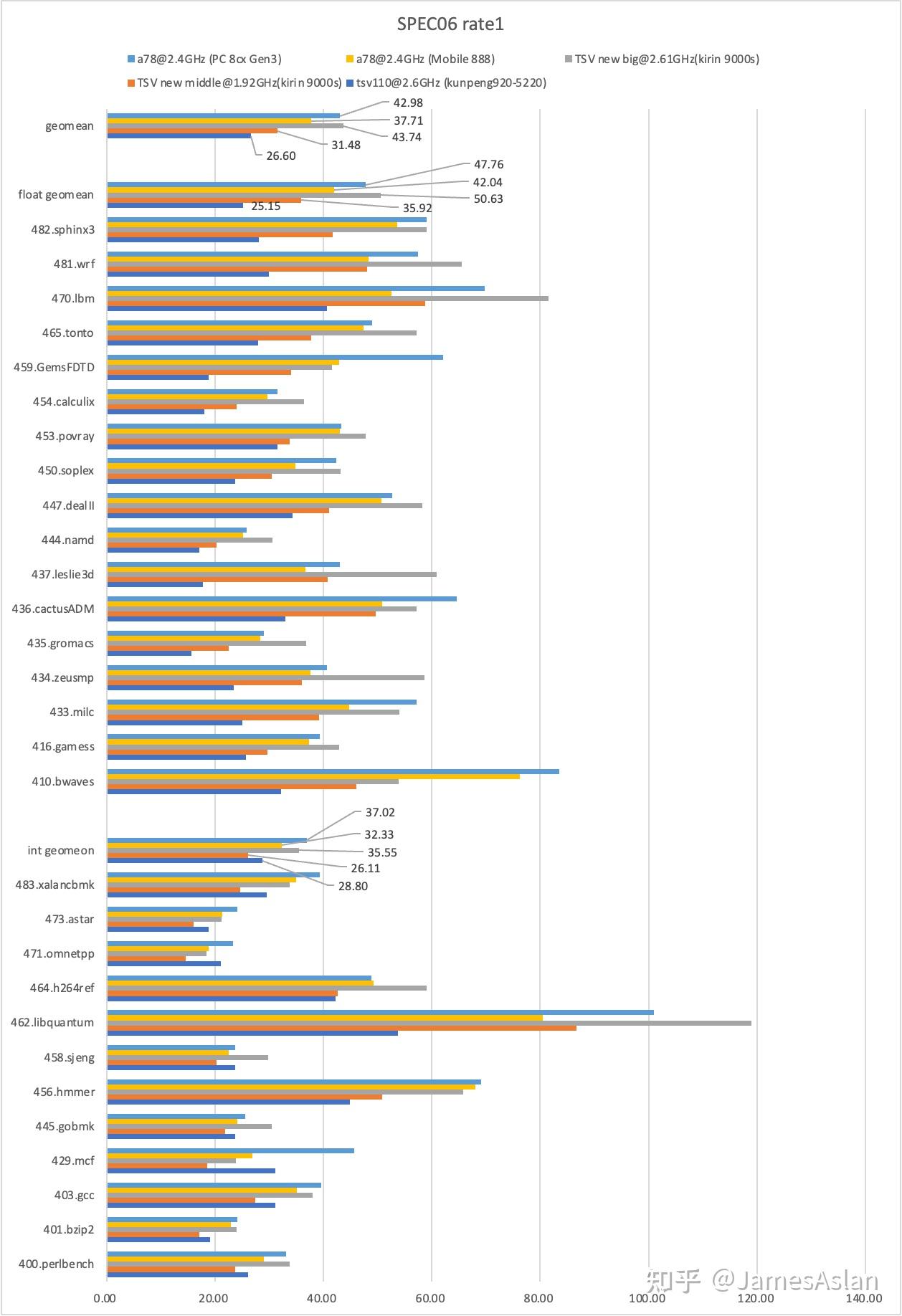
TSV new的fp成绩远高于int成绩。由于浮点程序访存行为较为容易预取,SPEC06int相较fp对L3容量更敏感,倘若能够增大L3 Cache(如16MB),个人估计同频下SPECint成绩能够提升15+%,其中受L3容量影响较大的子项应该是401、403、429、471、473、483。浮点侧受到的影响相对小,预计436、450、470、482受到了可观的负面影响。
TSV new在部分重访存代宽的子项中表现优秀,如462、410、433、434、437、447、450、459、470、481,表明了其配备了精细调节过的访存子系统(包括内存控制器和数据预取器等)。462.libquantum与470.lbm分数较高表明TSV new配备了较好的stream/stride预取器;而462.libquantum想要更进一步则需要更大的L3 Cache容量(如>20MB)。433.milc成绩离当前的第一梯队有一定距离,表明delta模式预取可能仍然存在进步空间。由于Cache容量过小,这些分析的噪声较大;如429.mcf受L3容量影响极大,我们无从剥离分析预取表现。483.xalancbmk相较TSV110提升寥寥,很可能是L3 Cache过小的缘故,但同样不能排除面对短流时预取器的无效操作过多。471.omnetpp的表现似乎表明TSV new没能克服激进预取带来的污染和拥塞问题。
总体而言TSV new取得了长足的进步。在本节我们同时列出了手机、PC平台的A78的表现,可见平台对微架构的性能的影响;因此TSV new在可能的鲲鹏930上才能发挥出其全部实力。
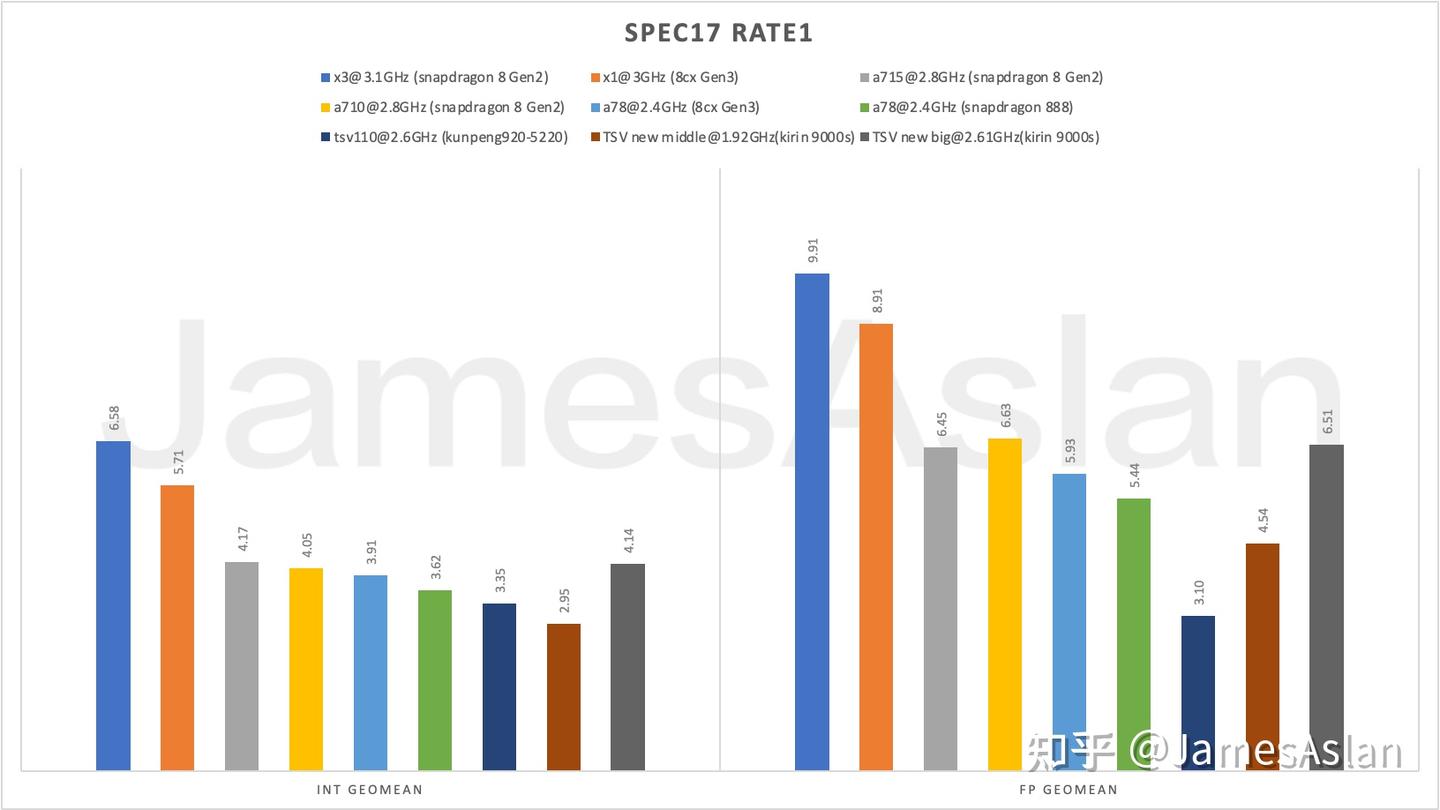
SPEC17
SPEC17是现役的SPEC测试集,被广泛用于微结构性能评估。
编译环境:GCC12.0 -O3 -static
GLIBC 23.5-0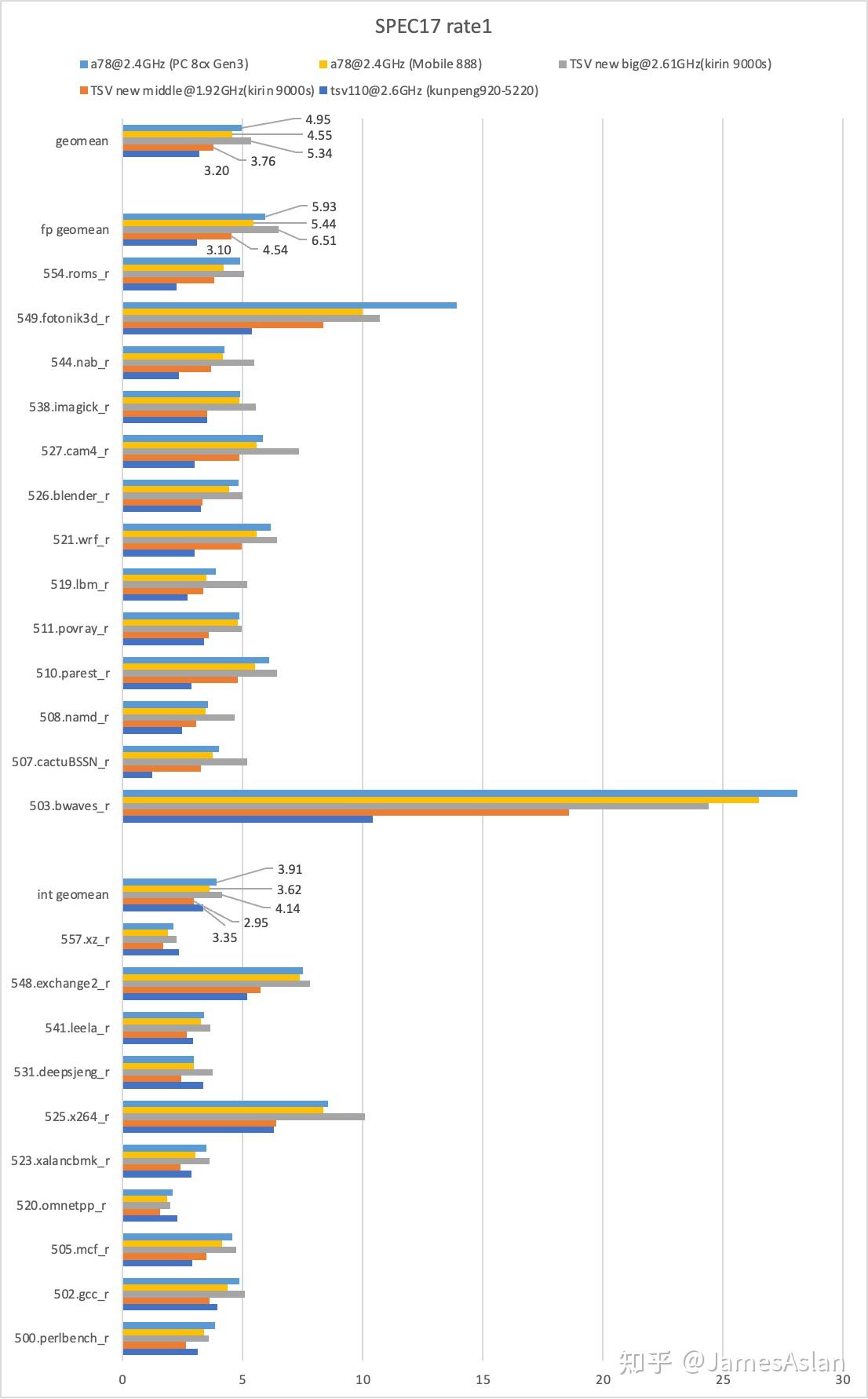
总体而言中核相较大核性能衰减较大,但是这主要来自于频率的大幅下降,倘若我们计算IPC性能会发现中核的缩水较为有限。尽管频率处于劣势,但是中核仍然在总性能中超越了前代产品TSV110;如果有更好的下级memory system支持,中核恐怕也能够超越全规格的TSV110。尽管受限于有限的memory system规格,TSV new仍然保持着对A78的性能优势,这让我更为期待可能的满血版本了。
Coremark
由于其他测试耗时较长,我们首先放出coremark的成绩。Coremark是一款嵌入式基准测试程序,其受下级Cache子系统、内存等的影响极小,主要考察核内流水线以及L1 Cache的性能表现。
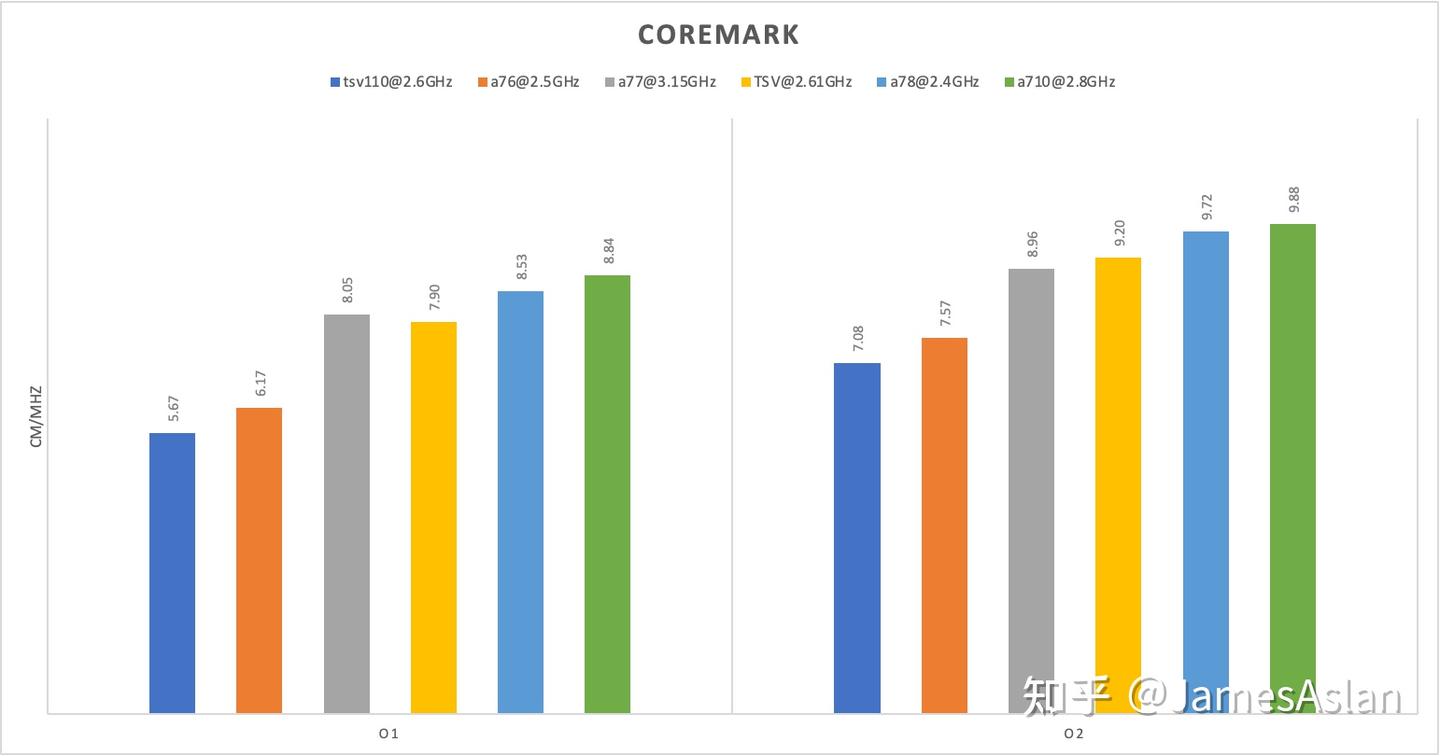
可见TSV new成功迈入了9分大关,符合我们对一款现代6发射处理器的基本期待,但是时至2023年,这样的成绩算不上优秀,6发射的上限远不止于此,期待后续产品的迭代。
Verilator
以上三款测试集对处理器的前端压力较小,仿真大规模设计的verilator则恰恰相反,海量的分支与数MB的代码足迹能够轻松压垮ICache、BTB等组件,导致巨大的性能下降。
由于手机环境的限制,我们完整仿真环境中的部分组件无法运行,裁切部分组件并削减仿真规模后得到了Verilator_lite测试。注意:
- Verilator_lite测试的成绩与Verilator测试的结果不能直接比较。
- 我们也会在桌面平台上运行Verilator_lite测试以提供参照,请留意图表标题是Verilator_lite还是Verilator。
- 在同一图表中仅会出现Verilator_lite或Verilator成绩中的一种,不会有数据混杂。
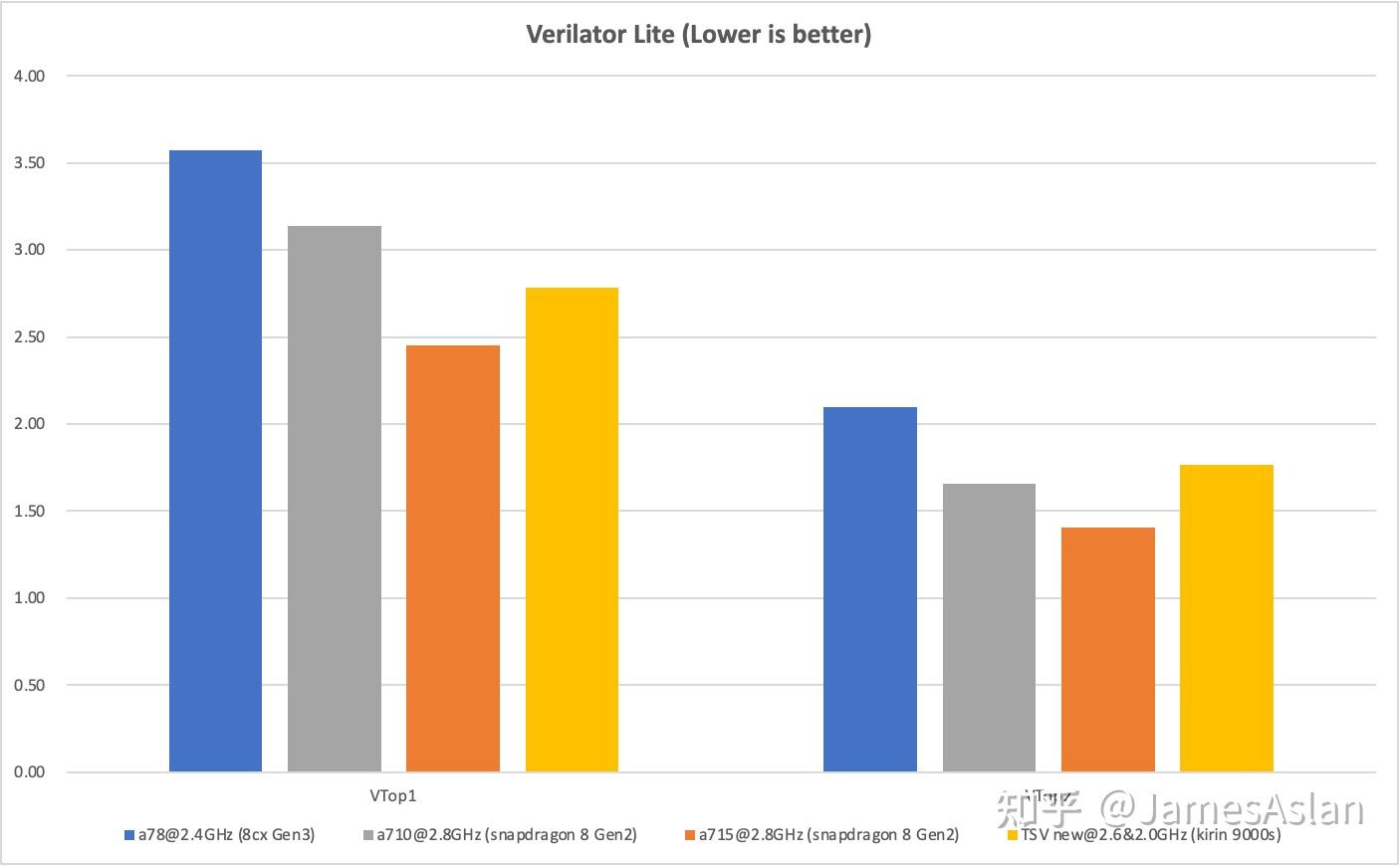
TSV110表现过差不予展示(各位自行脑补一个突破天际的柱子)。TSV new在前端供指方面取得了长足的进步,这是部分服务器负载十分看重的性能指标,因此对于可能的鲲鹏930十分重要。尽管频率极低,TSV new仍然能保持与ARM公版最新的产品接近的成绩。可以预计倘若配备了2颗2.8GHz的TSV new,在verilator中它们的表现将超过A715。不过本人还在纠结TSV new到底有没有使用decoupled frontend设计,有没有大神知道其中的真相呢23333。
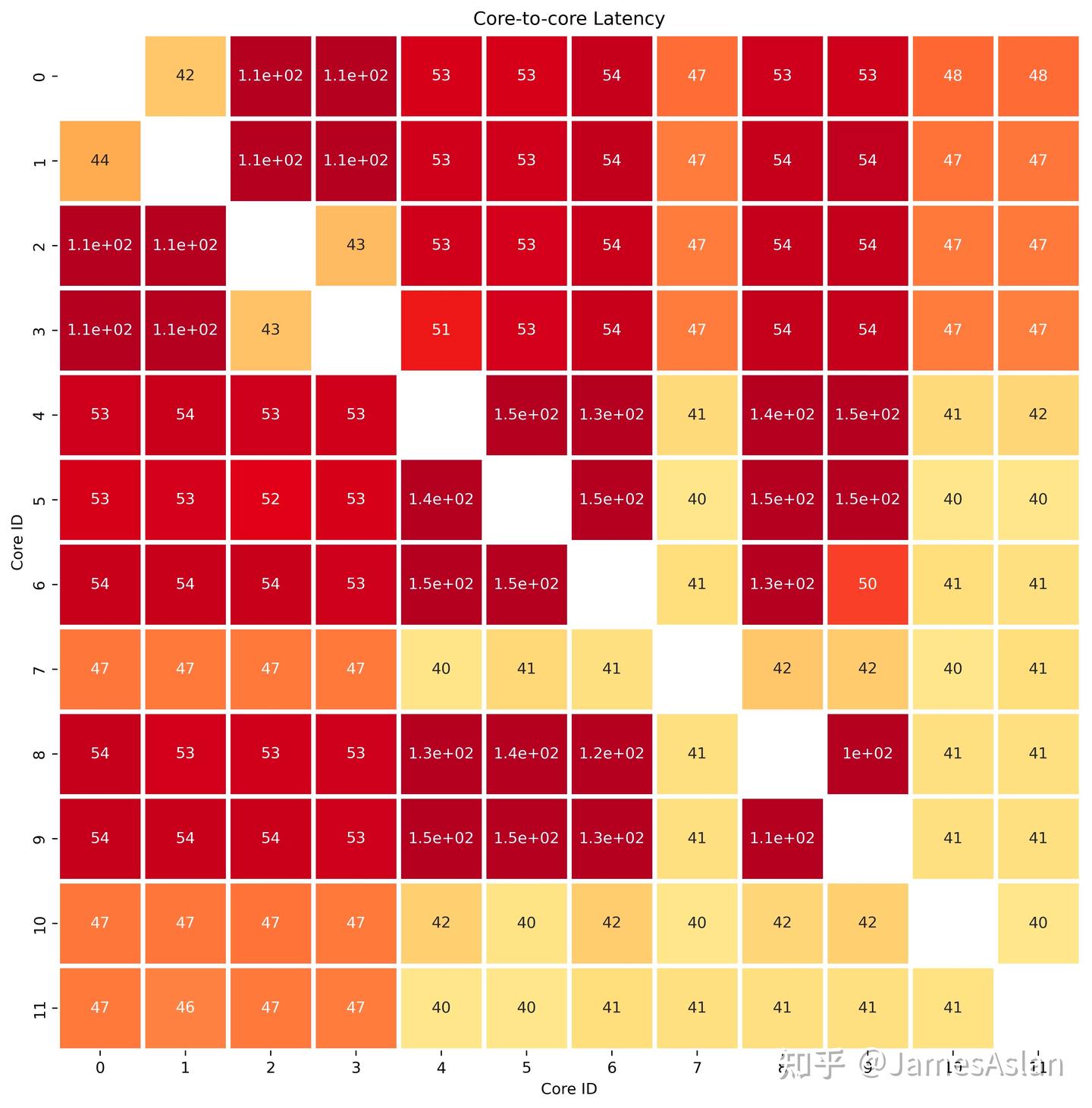
超线程(SMT)
在ubuntu中虽然我们可以调用额外的线程号,但是从core-to-core latency的测试来看并没有超线程迹象。这里有两种可能:
- 我们使用的ubuntu中的API没有真正成功绑定8-11号核,导致我们仍然在0-7号核上执行,致使没有观测到sibbling核间超低的脏数据交换延迟。那么我们只能等待其他大佬真正适配SMT了。
- TSV new使用了特殊的设计,保证了sibbling线程间更强的数据一致性,使得所有数据交换都下探到了L3层级。
测试平台
Mate60Pro 12+512G版本。
好漂亮的手机555,就是好贵,我的A7C2副机灰飞烟灭了啊。

分析与测试:lyz、lxy