

BP(Back Propagation) Algorithm
(1)History
BP算法即误差后向传播算法应用于神经网络的思想最早是由Paul Werbos在1974年其博士论文中首次论证,然而当时由于人工智能正处于发展的低谷,这项工作并没有得到较大的重视。1983年加州理工学院的物理学家John Hopfield利用神经网络,通过电路模拟仿真的方法求解了旅行商这个NP难问题,在学术界引起的较大的轰动,这也推动了人工智能第二次的快速发展。然而Hopfield Network并没有采用BP的训练方法,其网络结构可以看做一个完整的无向图,最终的训练目标是通过不断地迭代修正权值是网络的整体能量达到最小,为无监督学习。1986年在Hinton和David E. Rumelhart等人的努力下,BP算法被再次发明,并广泛应用于升级网络的训练中。目前红的发紫的深度学习各种网络模型也均采用了86年提出的BP算法。
(2)Introduction
反向传播算法的motivation是期望通过在神经网络的训练过程中自适应的调整各神经元间的连接权值,以寻求最佳的输入输出间的映射函数,使得目标函数或损失函数达到最小,完成分类、回归等任务。
这里我们记目标函数为:
上式中,第一项即为经验风险,即各类损失函数。第二项即为正则化项。其中 ,为调整两者之间关系的系数。当
时,则表示无正则化项,
越大则表示对应正则化惩罚越大。
常见的损失函数主要包括:
- 绝对值损失函数:
,由于该损失函数存在绝对值,求导不易,故很少使用。
- 平方损失函数:
,广泛应用于回归问题中,如最小二乘、线性回归。
- 对数损失函数:
,一般用于做极大似然估计,其可以刻画分布间的相似程度。如Logistic回归。
- 交叉熵损失函数:
,交叉熵反映两函数分布的相似程度,其等价于KL散度(认为数据的信息熵固定不变,相对熵等于交叉熵减信息熵)。一般其会与Softmax函数配合使用,主要应用于多分类问题。
- 指数损失函数:
,主要用于集成学习中,如AdaBoost。
- 铰链损失函数:
,应该用于SVM支持向量机中。
对于统计机器学习算法一般为缓解过拟合现象的发生需要在进行正则化操作,通过正则化以偏差的增加换取方差的减小。最常见的方法即为在损失函数中引入矩阵范数,以对模型的复杂程度做出惩罚。
范数正则化:
,使网络权值分布于0值附近,呈高斯分布。
范数正则化:
,使网络权值大量取0,参数稀疏。
范数正则化在统计学中又称为Lasso回归。
范数正则化:
,
- Frobenius范数:
,矩阵的Frobenius范数就是将矩阵张成向量后的
对于范数的具体介绍可参加我的另一篇文章深度圣经网络(Deep Neural Networks)
对于目标函数最小值的求解,一般使用梯度下降法,寻求其局部极小值代替全局最小值(若目标函数为凸函数,则梯度下降法可找到全局最优解)。其原理主要来自于泰勒展开式,如下:
一阶泰勒展开式:
二阶泰勒展开:
上式中 为泰勒展开余项,其中常见的有:佩亚诺(Peano)余项、施勒米尔希-罗什(Schlomilch-Roche)余项、拉格朗日(Lagrange)余项、柯西(Cauchy)余项等。
对于梯度下降法,我们考虑泰勒一阶展开,(若考虑泰勒二阶展即为牛顿法,但是实际中由于矩阵求逆较为困难,因此对于不同的矩阵求逆的近似方法而派生出许多不同的拟牛顿法)则有:
故:
上式中, 为学习率。若学习率过大算法将越过局部极小值而震荡不收敛,若学习率过小,算法将收敛较慢,训练时间加长。如下图所示:
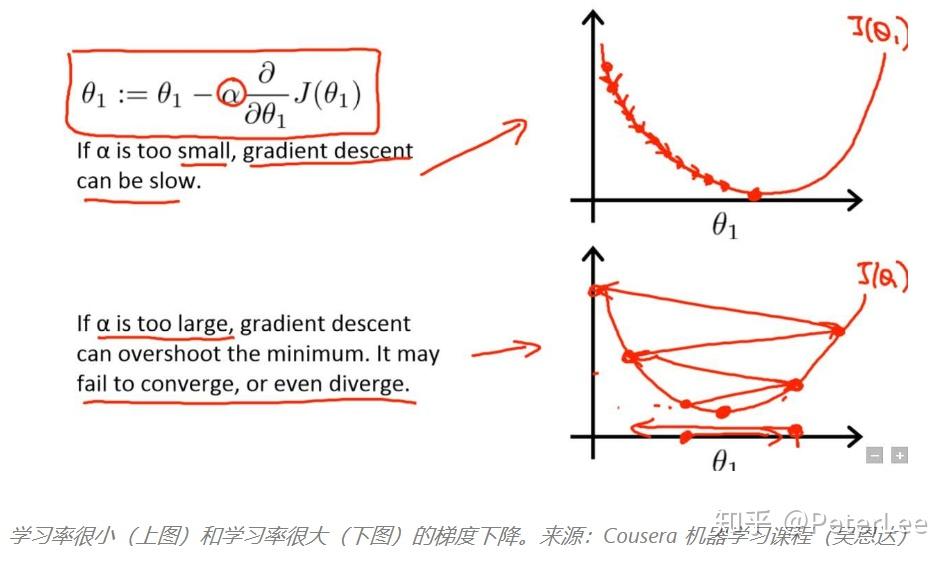
因此在网络的训练中,我们一般采用在训练开始的早期选用较大的学习率,以较快寻求极小值的大致取值。随着迭代次数的增加,学习率将逐渐减小,以更精细的搜索,寻求极小值。
这里我们简单介绍BP算法,如下所示:
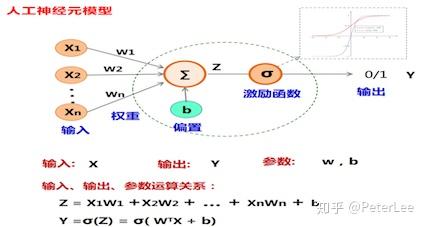
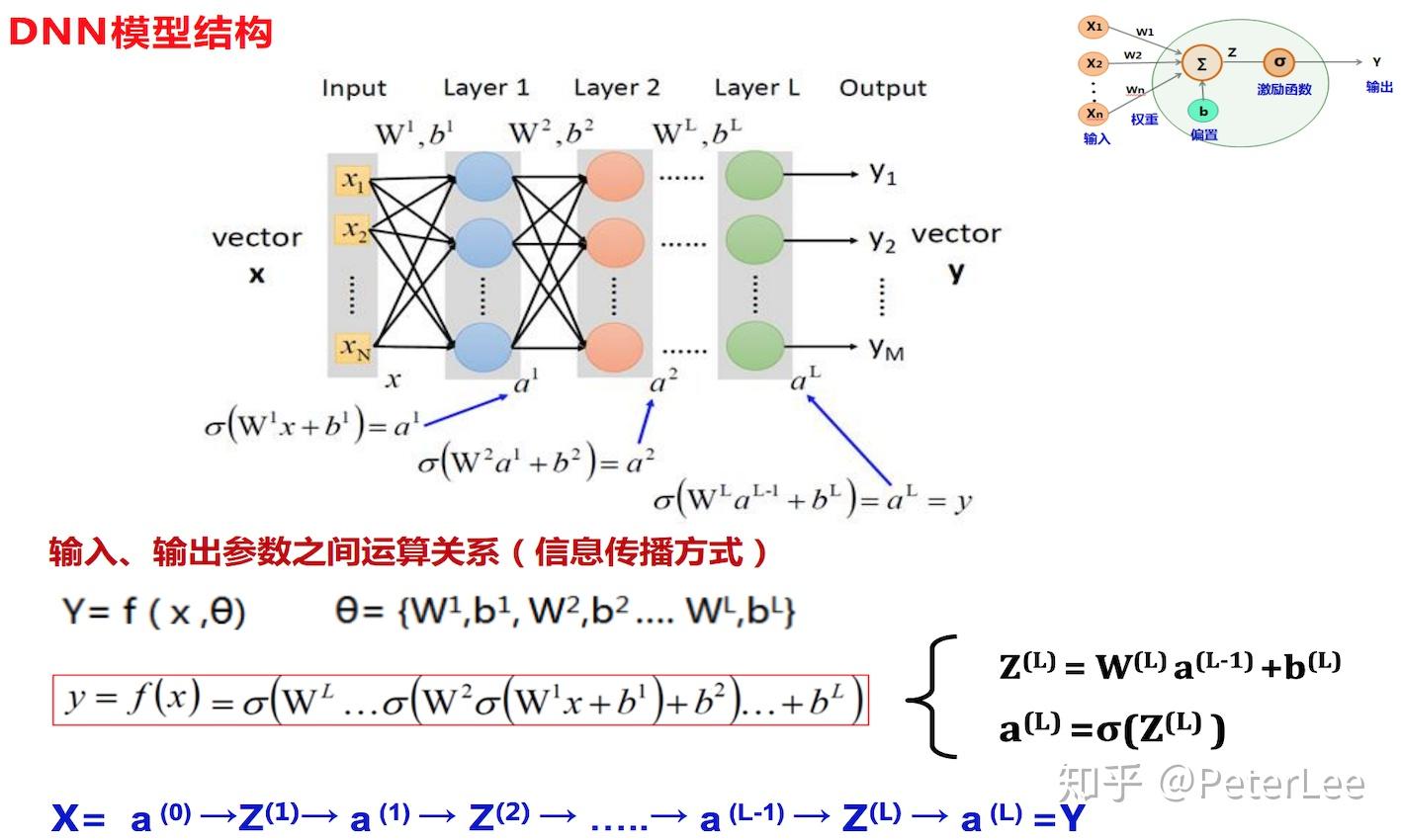
(1)前项传播过程;
记输入为 ,输出为
,则有:
输入层: 。
隐层:第j个神经元的输入为 ,即
。输出为
,即
。其中,
为输入
的权值;
为第j个神经元的偏置项;
为激活函数。
输出层:第 个神经元的输入为各个隐层神经元的输出,即
输出为 :
对于多分类问题其输出$y_i$一般还需经过Softmax函数 ,求得每一类的概率,最后在输入给交叉熵损失函数,或对数损失函数。而对于log softmax其相对于sigmoid函数,将不会出现饱和的现象,此外最大化log softmax 可以看成最大化分子最小化分母,即存在一定的奖惩机制,使得训练简单。
对于其激活函数一般要求连续可微,以满足求导需求。其次一般的激活函数还包括限幅的作用,且导数简单。常用的激活函数如下:
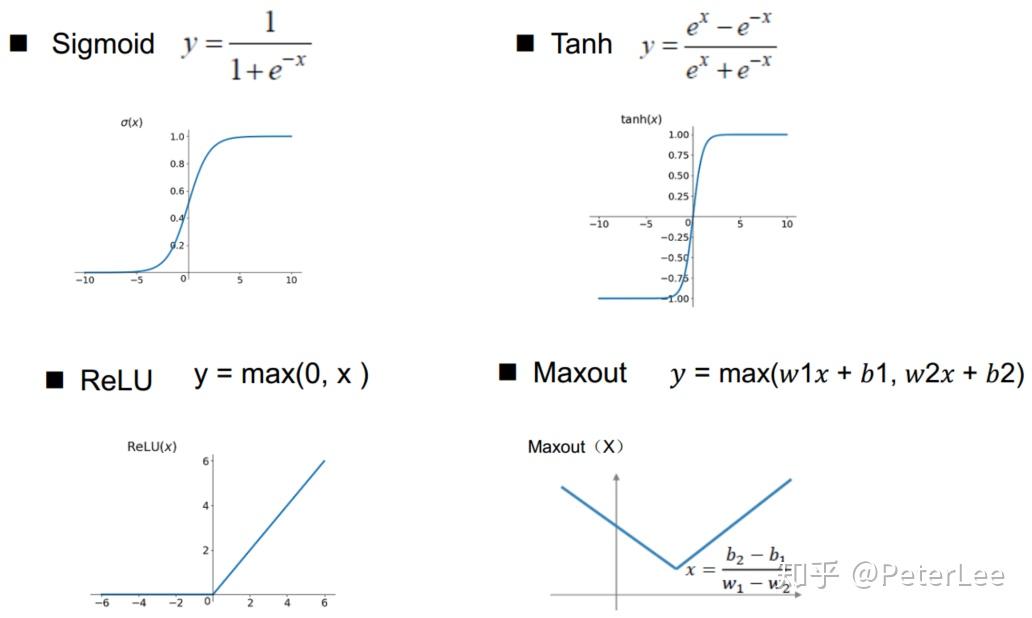
sigmoid激活函数由于其存在饱和区,因此在梯度反向传播时容易出现梯度消失的问题,因此在实际中我们通常选择ReLU激活函数,但是ReLU函数在输入小于0时其输出也为0,因此在网络训练时容易出现部分神经元“死亡”的现象,故有时我们也会使用Leak ReLU或Random ReLU。此外当我们必须使用Sigmoid激活函数时,也可以考虑使用tanh激活函数替代,以部分缓解梯度饱和现象。另外还需注意的是ReLU对学习率较为敏感。
(2)误差反向传播过程;
记损失函数为: ,利用梯度下降法及链式求导法则求解最优参数:
①输出层 ,
:
其中: ,
。
则式(4)即为:
记 ,则式(10)即为:
因此权值更新为:
同理,对于
偏置更新为:
②隐层 ,
:
同理,记
根据链式求导法有:
有①知: 。
故式(12)为:
故隐层权值 ,偏置
更新公式如下:
至此三层全连接神经网络的参数更新过程以推到完毕。
(3)Defects && Future
当隐层数目过多,即网络太深时,若使用Sigmoid激活函数将存在梯度消失的问题。这是由于sigmoid函数每求一次导数其参数值将衰减至原来的1\4,当网络层数过多,其参数将越乘越小,而无法达到参数训练的目的。在2012年Image Net竞赛中,AlexNet网络首次使用ReLu激活函数,代替Sigmoid函数解决梯度消失问题(其实LeCun组2010年的文章What is the best multi-stage architecture for object recognition?尝试了各种非线性激活函数,其中就包括ReLU的等价形式)。在此之后的深度网络中ReLu激活函数以成为解决梯度消失的首要选择。同时一些ReLu激活函数的变种也相继被提出,如Leaky ReLUs、PReLU、RReLU等。此外,我们还可以采用预训练的方法,即2006年Hinton等提出的训练深度网路的方法,用无监督数据作分层预训练,再用有监督数据fine-tune。或者利用辅助损失函数,如GoogLeNet中使用两个辅助损失函数,对浅层神经元直接传递梯度。或者使用Batch Normalization/Batch Re-Norm,逐层的尺度归一。或者借助ResNet,网络跨层连接等 由于尺度不平衡的初始化导致梯度爆炸的问题也同样存在,对此我们可以采用Xavier方差不变准则保持网络节点尺度不变。然而在权值训练过程中还存在一种更恶心的问题,即鞍点问题。
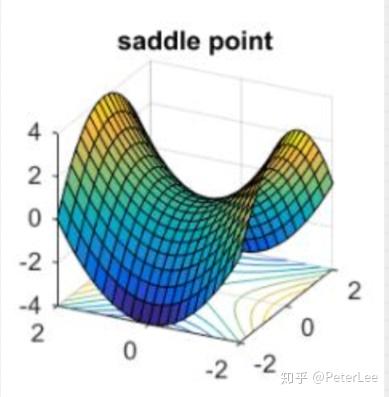
某些点在函数的某一方向上是极小值点,然而在另一方向却是极大值点。如函数 ,点(0,0)为鞍点。对于Hessian矩阵,其特征值同时存在正值和负值,即存在鞍点。实际上,高度非凸的深度网络优化难点并不是所谓的局部最小值点,而是无处不在的鞍点。然而对于这类问题简单的随机梯度下降(SGD)却能取得较好的效果,有一种解释是认为随机梯度下降能引入部分的随机噪声,其有一定的正则化效果,故能有效避免陷入鞍点。
此外,对于BP算法其本质上也存在一些缺点,如当目标函数非凸时,其无法搜索到全局最小值。而且使用BP算法的前提即存在目标函数,也即需要衡量学习的数据分布与真实的数据分布间的差异,这也意味着我们需要拥有样本标签,并采用有监督的学习方式。无监督的学习仍是目前研究的难点和热点。其实对于无监督学习在,某种程度上可以将其理解为一种元学习,其实质上仍然存在一定程度的监督,只不过在学习算法中更加隐晦。如生成对抗网络(GAN),GAN包括两个网络:生成器和鉴别器。生成器生成大量伪造数据逼近现实,鉴别器用以判别真时数据和伪造数据,即它可以用真时数据验证内部生成器网络,鉴别器可看做使用目标函数的神经网络。两个网络“相互竞争,共同进步”。GAN网络使用反向传播,执行无监督学习。
虽然距BP算法提出以超过30年,并且该算法广泛应用于神经网络的训练中,然而最近Hinton大爷却不止一次在媒体和会议上对这种方法表示质疑,并期待寻求新的更好的方法代替或改进BP算法,如胶囊神经网络。这里也希望奋斗在Ai领域的给位专家学者们能带来更多的突破。
[5] Sabour S, Frosst N, Hinton G E. Dynamic Routing Between Capsules[J]. 2017.
[6] Why we should be Deeply Suspicious of BackPropagation
专栏:ZH.Li的机器学习笔记
Machine Learning学习笔记