

ZEM Algorithm
EM(Expectation maximization)算法,也即期望最大化算法,作为“隐变量”(属性变量不可知)估计的利器在自然语言处理(如HMM中的Baum-Welch算法)、高斯混合聚类、心理学、定量遗传学等含有隐变量的概率模型参数极大似然估计中有着十分广泛的应用。EM算法于1977年由Arthur Dempster, Nan Laird和Donald Rubin总结提出,其主要通过E步(exceptation),M步(maximization)反复迭代直至似然函数收敛至局部最优解。由于其方法简洁、操作有效,EM算法曾入选“数据挖掘十大算法”,可谓是机器学习经典算法之一。
Introduction
EM算法推导一
对于概率模型,当模型中的变量均为观测变量时,我们可以直接使用给定数据通过最大似然估计(频率学派)或贝叶斯估计(贝叶斯学派)这两种方法求解。然而当我们的模型中存在隐变量时,我们将无法使用最大似然估计直接求解,这时即导出EM算法。
假设一个概率模型中同时存在隐变量 和可观测变量
,我们学习的目标是极大化观测变量
关于模型参数
的对数似然,即:
式(1)中我们假设直接优化是很困难的,但是优化完整数据的似然函数
相对容易,同时利用概率乘法公式将
展开。然而由于未观测变量
的存在,上式仍求解困难,因此我们通过迭代逐步最大对数似然
,这里假设第
次迭代后
的估计值为
。根据要求,我们希望新估计的参数
使
增加,即
,且逐步使
达到最大,因此考虑两者之差:
这里我们根据Jensen(琴生)不等式: ,其中
有:
同时由于 ,式(3)可进一步写为:
因此有:
因此, 即为
的下界。故当
增大时
也将同时增加,为使
取得最大,则我们必须在
次迭代时选择的
为使第
次迭代
取得最大的
,即:
这里记,
由于在上一轮迭代中 已知,故在上式的求解中我们略去了对求解
极大化而言的常数项
和
。
因此在EM算法的每一迭代中,我们均需求解使得 取得最大值的
,使得下一不迭代的
,这样如此反复提高最大似然
的下界,直至逼近
的最优解(最大值)。
EM算法推导二
这里我们采用变分的方法,假设隐变量服从任一分布为 ,则
。故对于
同样有:
记(1)为 ,(2)为
。其中
即为KL散度(相对熵),主要反映变量
分布的相似性,可以看出KL散度=交叉熵-信息熵,故交叉熵在某种意义上与KL散度等价。有:
由于 ,因此
即为对数似然函数
的下界。同理在每一次迭代中我们均需要最大化下界
,则在第
次迭代中即有:
式(9)中 为一常数
,故式(8)与式(6)等价。因此,综上可知,EM算法可描述为:
对于观测变量数据 和隐变量数据
,其联合分布为
,条件分布为
:
- Step1. 参数初始化
,开始迭代。
- Step2. E步:记
为第
次迭代的参数
的估计值,则在第
次迭代的E步中,有:
上式中, 即为给定观测数据
和当前估计参数
下隐变量数据
的条件概率分布。
函数为对数似然函数
关于在给定观测数据
和当前模型参数
下对未观测数据
的条件概率分布
的期望。
- Step3. M步:计算使
取得极大值的
,有:
- Step4. 迭代Step2,Step3直至收敛。其收敛条件一般为给定较小的正数
,若满足:
由于目标函数为非凸函数,因此EM算法并不能保证收敛至全局最小值,即EM算法的求解结果与初值的选择有较大关系,该算法对初值敏感。
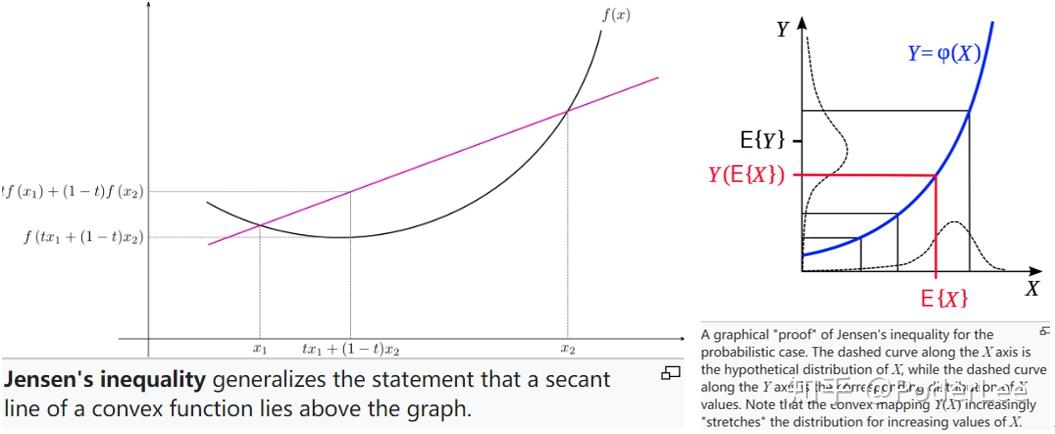
上述推导过程可由下图表示:
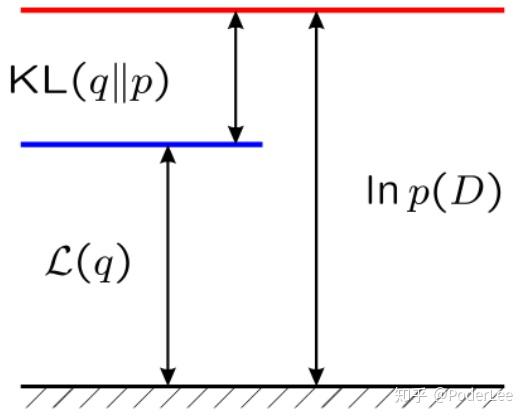
图1即对应式(8),可以看出 由
两部分组成。其中
即为
的下界。
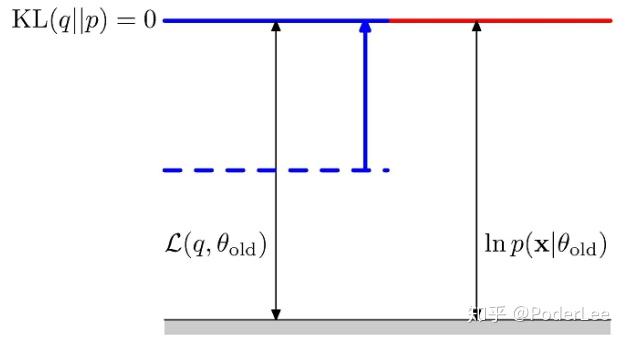
在M步中我们总期望最大化 ,即使得
的下界取得最大,也即最大化对数似然。故此时
取得最小值为0。求解最大化
函数,得到
次迭代变量的估计
。
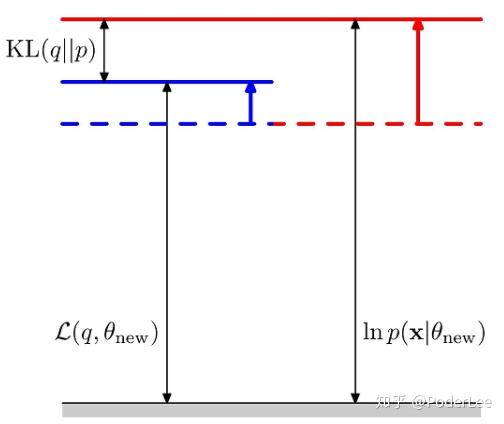
从图3中可以明显看出在 更新后,对数似然
的下界
和
均得到提高。此时在继续求解
。如此反复迭代,通过不断提高的
下界,使得其取得局部最大值。
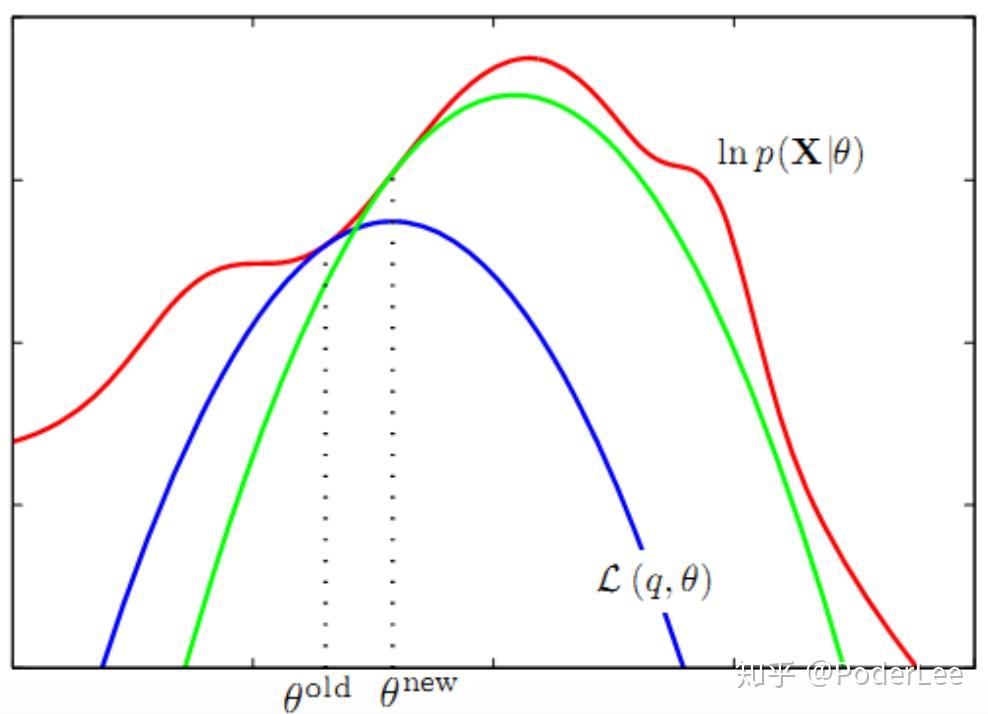
从图4中我们也能明显看出,通过 的反复迭代,我们不断提高对数似然的下界
使之最后收敛于对数似然的局部最大解。
由上文讨论我们已经知道,通过EM反复迭代,其对数似然的下界将不断提高,然而我们却还是要问对于这种启发式的方法,即下界不断增大的这种方法,其等价于求解对数似然的最大值吗?或者说通过不断优化下界,算法就一定会收敛到似然函数的最大值吗?我们对此能否给出理论证明呢?
EM算法收敛性的理论证明
这里我们分别给出两种方法的理论证明。
收敛性证明方法一
这里主要利用变分的思想,参照式(7)有:
由于 恒成立,且我们跟据第
次迭代参数
估计
有
。故式(10)即为:
故对于每一次的迭代均能保证 ,即可将EM算法理解为在变量坐标空间内,利用坐标下降法最大化对数似然下界的过程,故算法最终能够收敛至局部极小值点。
收敛性证明方法二
这里我们使用Jensen不等式进行证明,即对于凸函数 有
,故
(其中
为凸函数,只有为凸函数时琴生不等式才存在)。因此有:
同样跟据第 次迭代参数
估计
,则式(12)为:
故算法最终能够收敛至局部极小值点。
GMM
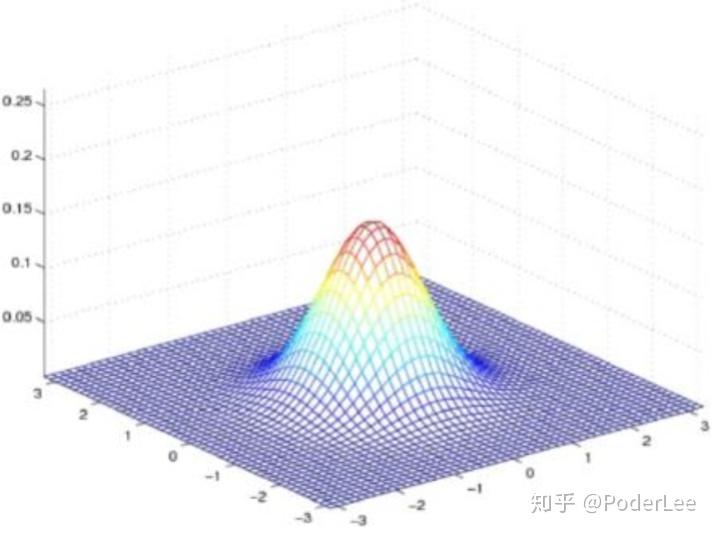
与K-Means聚类不同,高斯混合聚类采用概率模型来刻画每个样本的簇类,即为一种“软划分”方法。这里我们首先回忆多元高斯模型。
对于 维样本空间
中的随机向量
,
服从高斯分布
~
,其概率密度函数如下:
其中 为
维均值向量,
为
协方差矩阵。
则:
多元高斯分布如下图所示:
这里假设存在 个簇,且每一个簇均服从高斯分布。我们以概率
随机选择一个簇
,并从该簇的分布中采样样本点,如此得到观测数据
,则其似然函数为:
观察式(15)发现函数 由于
中有求和运算,所有参数均耦合在一起,故求导困难,因而梯度下降优化较为困难。因此我们有必要采用一种新的优化算法。
这里首先我们令 ,则有:
这里我们记 ,则
可以看为由参数
对应的观测变量
的后验概率,即
从属于第
个簇的一种估计,或权值或“解释”。同时对式(16)左右两边同时乘以
,并进行移项操作,有:
同理我们令 ,有:
其中 ,有关多元正态分布的极大似然估计中均值和协方差的偏导求解过程具体可以参考:
最后我们考虑混合系数即变量 ,同理最大化对数似然
。然而由式(15)知
需满足约束条件
,故这里我们引入拉格朗日乘子法,即最大化下式:
式(19)对 求偏导为0有:
上式两边同时乘以 ,有:
这里我们将 对
进行求和,即
,则有
,故:
这里需要注意的是由于 ,中仍存在隐变量
,并非为封闭解,故我们需要根据EM算法求解。具体如下:
- Step1. 初始化参数并计算对数似然;
- Step2. E步:依据当前模型参数,计算观测数据
属于簇
的概率(从属度):
- Step3. M步:基于当前参数最大化对数似然函数,即重新求解新一轮迭代参数(第
- Step4. 反复迭代直至收敛。
至此我们已经给出了EM算法求解GMM模型的具体方法。对比GMM与K-Means方法,我们可已看出由于概率的引入使得点到簇的从属关系为软分配,故其可以被用于非球形簇。
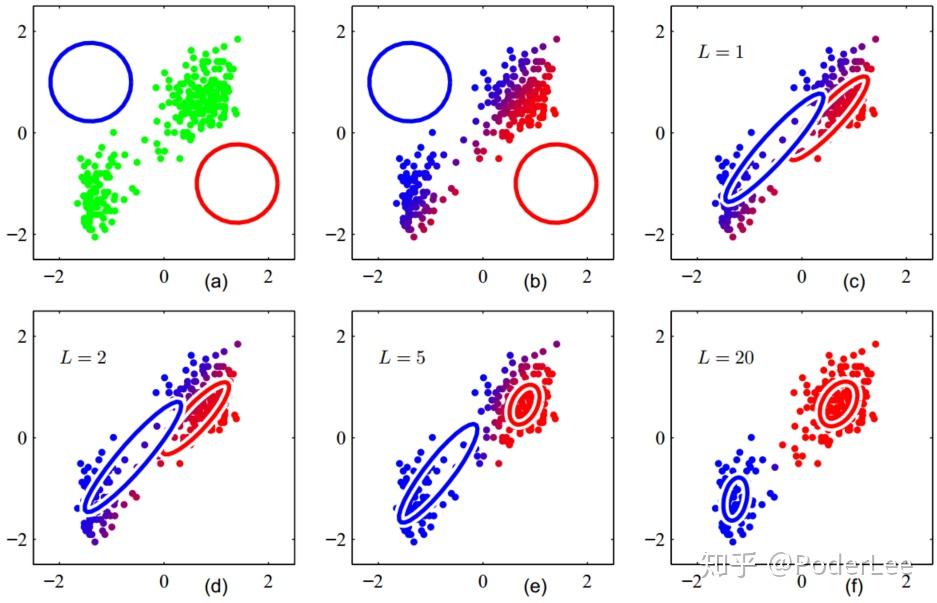
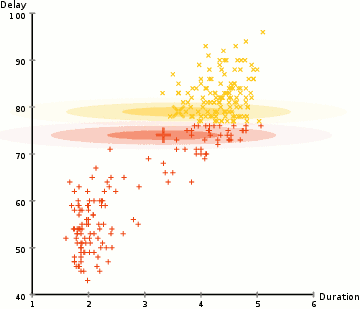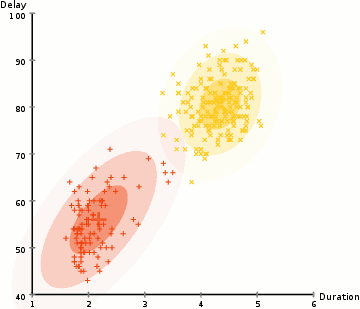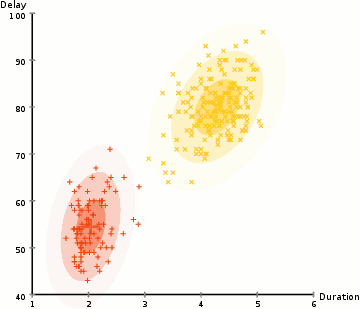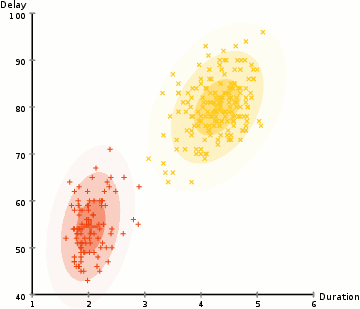
上图即为GMM算法的聚类过程。EM算法求解结果为局部最优解,其在隐变量的估计中应用广泛。
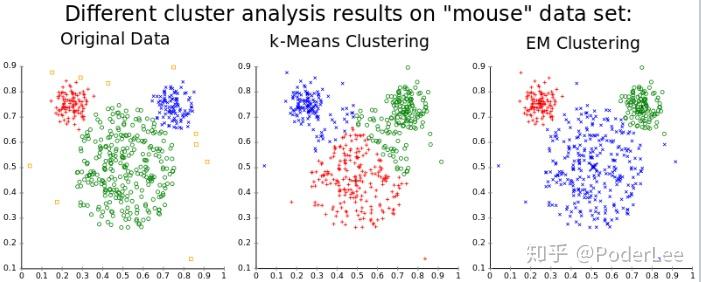
由上图可以明显看出GMM相较于K-Means聚类有更佳的效果。
Variants
由于EM算法是只能收敛至局部极小值点,其对初值敏感。为克服这一缺陷,各种各样的启发式搜索算法如模拟退火法(其能较好的收敛至全局最优解)、随机重复爬山法等,通过多次随机的参数初始化或一定概率拒绝当前解从而使算法收敛至全局最优。此外卡尔曼滤波的思想同EM算法结合从而发展了Filtering and smoothing EM algorithms,以解决联合状态参数估计问题。共轭梯度与拟牛顿法也在EM中得到了应用。参数扩展期望最大化算法(PX-EM,parameter-expanded expectation maximization)通过协方差的调整引入额外的信息来修正M步中参数的估计以加速算法收敛。 由于不需要计算梯度或Hessi矩阵而使得算法收敛更快,同时也因而派生出了
算法。
Reference
[1] Dempster A P. Maximum likelihood estimation from incomplete data via the EM algorithm (with discussion[J]. Journal of the Royal Statistical Society, 1977, 39(1):1-38.(http://web.mit.edu/6.435/www/Dempster77.pdf)
[2] Jensen's inequality - Wikipedia
[3] Bishop C M, 박원석. Pattern Recognition and Machine Learning, 2006[M]. Academic Press, 2006.](http://users.isr.ist.utl.pt/~wurmd/Livros/school/Bishop%20-%20Pattern%20Recognition%20And%20Machine%20Learning%20-%20Springer%20%202006.pdf)
[4] Expectation–maximization algorithm - Wikipedia
专栏:ZH.Li的机器学习笔记
Machine Learning学习笔记