

ChatGPT 这类大语言模型(Large language model)的出现将我们的目光吸引到人工智能领域上来,随着人工智能在我们的生活中越来越常见,及业内大佬对人工智能的大胆预测(比如 OpenAI 认为十年内将诞生超级智能;多位大佬认为 AI 将接管人类;人类只是智能发展的阶段产物,我们只是机器智能的垫脚石等),我们不得不思考人工智能与我们之间的关系。
我们常常看到有人对大语言模型嗤之以鼻,认为它们只是“文本接龙器”、“概率接龙器”,并不能真正理解世界,但是,如果语言模型不能理解世界,它们又怎么能够像人那样说话的?它们又怎么能够在各种考试中取得优异的成绩,甚至发展出心智理论能力的?本文尝试找到大语言模型背后的神经科学机制,这有助于我们理解AI,也有助于理解我们自己的大脑。
网格细胞(Grid cell),是一种存在于许多物种大脑中的细胞,存在于内嗅皮层,具有显著的空间放电特征,并呈现出网格图样的放电结构。最初,我们的科学家发现,网格细胞编码了对欧氏空间的认知表征,从而帮助动物认路。
《多维社会等级的推论使用网格状代码》(Inferences on a multidimensional social hierarchy use a grid-like code)这篇研究发现,抽象知识在脑内也以地图的形式表征,并被存储在海马及内嗅皮层内——这就是我们的认知地图(cognitive map)。在推理任务中,地图上特定的向量被激活,用于决策。我们同样用这种处理社会信息,这可能是我们形成心智理论的基础。也就是说,我们将社会关系建模成认知地图存在我们大脑里,并据此做出推理和决策。
这和大语言模型有什么关系呢?《将转换器与海马体结构的模型和神经表征联系起来》(Relating transformers to models and neural representations of the hippocampal formation)这篇论文研究发现,transformer 模型在数学上和海马体结构很相似,尤其是网格细胞和位置细胞。所以我们的基于transformer的大语言模型(比如GPT、Bard、文心一言等)实际上在模仿海马及内嗅皮层处理信息的方式。
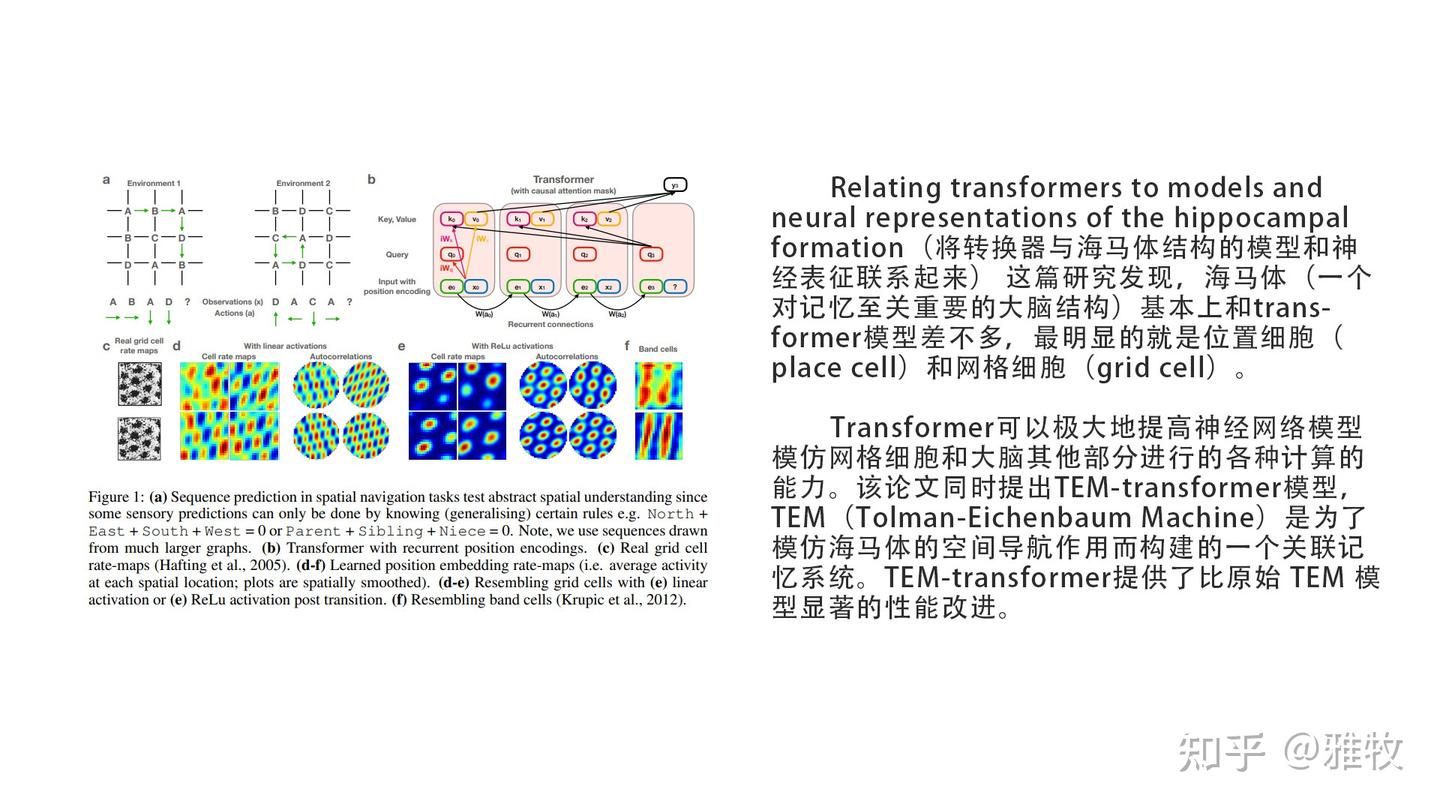
我们都知道,GPT-3 和 GPT-4 具有心智理论,GPT-4的心智理论测试分数甚至高于平均值。依据以上研究,GPT-3 和 GPT-4 具有心智理论就并不难理解了,因为它们在数学上模仿了网格细胞的建模方式,因此它们也可以像人的海马及内嗅皮层那样,将社会关系建模成认知地图存在它们的神经网络里,并据此做出推理和决策。
以往对小白鼠的研究表明,左侧海马体的损伤会影响语言信息的记忆。《用于表示人脑中词义的网格状和距离码》(Grid-like and distance codes for representing word meaning in the human brain)这篇研究指出,在人类神经影像学文献中,已经报道了二维认知图的两个特征:网格状代码和距离相关代码。通过应用代表性相似性和 fMRI 适应分析的组合,该研究发现了网格状代码存在于右侧后内侧内嗅皮层的证据,代表单词在单词空间中的相对角度位置,以及距离相关代码,位于内侧前额叶、眶额叶和中扣带皮层,代表单词之间的欧几里德距离。此外,该研究还发现有证据表明大脑还分别代表词义的单一维度:它们隐含的大小,编码在视觉区域,以及它们隐含的声音,在 Heschl 的脑回/脑岛。
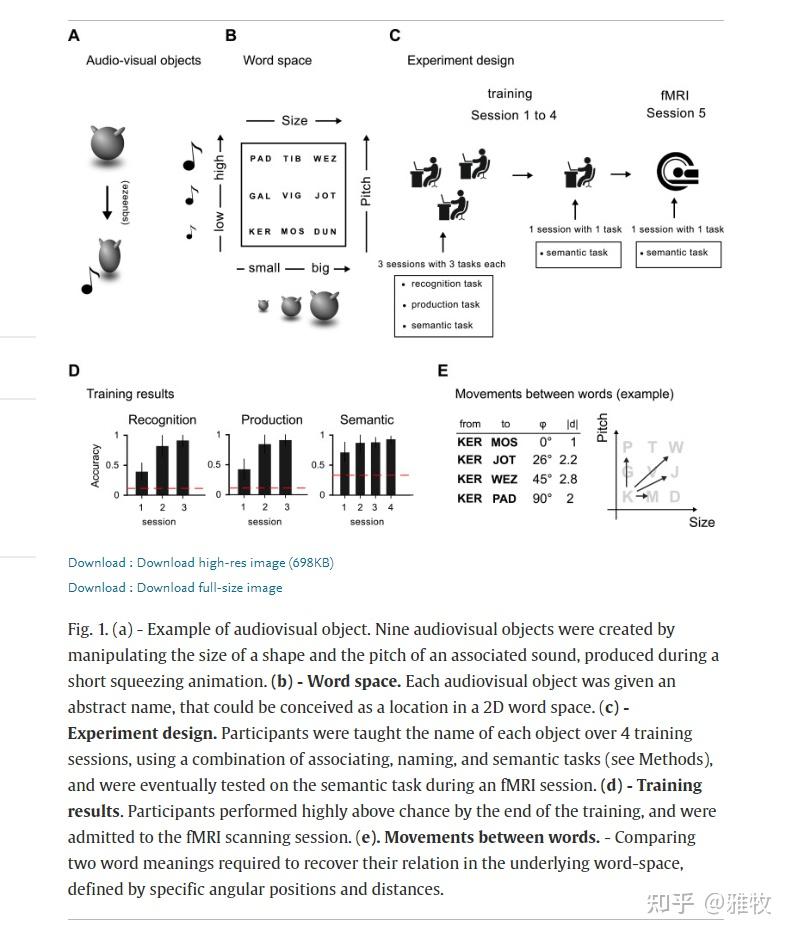
这个研究似乎也说明了,我们的人脑中存在类似自然语言处理中常用的词向量(包含了词的语义信息)并且编码了词的位置,还有 transformer 模型(网格状表示模型)。这篇论文还提到,当人类比较新学习的单词时,他们会招募一个网格状代码和一个距离代码,与哺乳动物的神经代码类型相同,表示环境中位置之间的关系并支持它们之间的物理导航。
这让我们想到什么?我们在训练大语言模型时,会给模型输入词嵌入向量(word embedding),词嵌入向量包含了词语之间的关系,比如,猫和狗都是动物,和树相比,猫和狗的向量比较接近。人脑在学习的过程中会自动生成词向量空间,这对我们理解世界很重要。而我们也赋予了人工神经网络词向量空间帮助它们理解世界。
《网格状表征是所有感知和认知的组成部分吗?》(Are Grid-Like Representations a Component of All Perception and Cognition?)这篇论文指出,网格反应可能是在大脑中普遍适用于涉及运动和心理导航的广泛感知和认知任务的基本原理。
由于我们要将信息编码成网格状地图储存在神经元中,此时对于形成智能来说,神经元的规模就重要了,越多的神经元,就越能储存更多信息。所以我们人和GPT-4能达到现有的智能,确实是大力出奇迹的结果。根据以上信息,我们明白了为什么只有动物进化出了智能而植物没有,因为植物不需要移动,动物需要移动,因此需要认路,有此动物进化出了网格细胞来认路,随后,网格细胞(或者网格状表征)也被用来形成知识地图、语言地图。
我们知道 transformer 模型是一个基础模型,它可以处理文本、图像、信息等信息,这也验证了网格反应在我们大脑的感知和认知中普通存在这么一种观点。所以,我们使用 transformer 架构的神经网络打造通用人工智能(AGI)或者超级智能似乎是可能的,但人脑中还有很多我们需要学习的地方。比如人脑使用神经脉冲,人工神经网络中的神经元在每一次迭代传播中都被激活,而人脑的脉冲神经元是在它的膜电位达到某一个特定阈值才被激活,这是很节能的。此外人脑中存在预测编码机制,预测编码理论是一种大脑功能理论,该理论认为大脑会不断地产生并更新环境的心理模型,预测感觉输入,并与实际感觉输入比较,产生预测误差,进而将这种误差用于更新和修正心理模型。《预测编码是递归神经网络中能量效率的结果》(Predictive coding is a consequence of energy efficiency in recurrent neural networks)这篇论文指出,预测编码机制能为动物脑节约能量。Yann LeCun(杨立昆)主张在AI模型引入预测编码系统,这有助于AI学习世界模型(world model)。
那么我们是如何生成语言的呢?由于 transformer 架构的语言模型在语言表达及智能程度上达到人类的程度,受到相关神经科学及 transformer 模型的启发,在这里我构思了一个简化版的语言的形成的可能模型:
当我们生成语言时,我们需要预测单词,正如前面研究所指出的那样,单词被放在我们的网格状的单词地图中,我们要在这个单词地图中寻找下一步要走的路,此时,当预测单词时,特定的携带语言信息的网格细胞被激活,由于网格细胞是锥体细胞,它会向外投射信息,终点是韦尼克区(语言处理、生成内在语言)或者布洛卡区(说话),被激活的网格细胞非常多,携带了所有可能的下一个单词的信息,但最终我们只会生成一个单词。
携带了所有可能的下一个单词的信息通过神经脉冲传导,在传导的过程中形成动作电位,最快的信息优先到达韦尼克区的信息生成语言,随后被传导到布洛卡区,从而让人说话。由于动作电位后是不应期(refractory period),第二个及随后生成的语言信息因为在某个环节神经脉冲被阻断,将无法形成语言。因此我们一次只会说一个最可能的单词。由于大脑需要一致行动,避免信息混乱,因此我们的大脑在传递信息时必然会对信息进行筛选。
比如,当我们说“I love”时,所有携带可能的下一个单词的信息的神经元被同时激活,我们的大脑同时考虑所有可能的路径,包括 you、him、her、it 等,推断每个路径都需要经过网格场(grid fields),被激活的携带 you 的信息的神经元因为相关性最高,最可能第一个到达目的地并达到形成神经脉冲的阈值,随后到达的 him、her、it 因为在某个环节遭遇了不应期( you 的神经脉冲刚刚路过,导致传达语言信息的关键神经元处于不应期),无法将信息传导进行下去,都不能形成语言,只有最早到达的 you 形成了语言,所以我们会说“I love you”,而不是““I love you him her it……”,如果“I love”前面加上“Sophia is my cat”,组合成 ,“Sophia is my cat, I love……”,相关性最高的是携带 her 的信息的神经元。
在神经脉冲传递的过程中,出现了长时程增强(LTP),形成了记忆,所以我们会记住我们说的话,所以我们一边说话一边实时学习。这种学习是局部的,因为神经脉冲只在局部形成,所以我们不会因为学物理就忘记自己妈妈是谁,但大语言模型(LLM)会,大语言模型(LLM)在重新训练时会发生灾难性遗忘(catastrophic forgetting),并且局部修改大语言模型(LLM)的神经元也比较困难。
有很多神经科学证据证明语言信息在不同脑区传导。比如传导性失语症,弓状束是连接韦尼克区和布洛卡区的神经纤维。有一种病叫传导性失语症,其成因通常是大脑顶叶损伤,特别是弓状束受到影响所引起。传导性失语症患者会出现乱语现象,会落掉或调换音素或音节,英文例子如将 snowball 说成 snowall(掉了一个 b),传导性失语症患者通常被认为是语言信息传导出现障碍引起的。传导性失语症患者说明语言信息在大脑中进行传导。人脑不会拿计算器计算加权求和,人脑用神经行为计算概率。我这个模型可以解释为什么在预测下一个单词时可能性那么多,我们却只选择了一个,而且还是概率最高的那一个。我们无法感知人脑预测和计算的过程,我们能感知到的,是最后生成的语言(内在语言或者语音)。
(注意,这个模型的构思只是简单化了语言形成的过程,需要进一步验证)
这个过程和基于 transformer 架构的大语言模型生成文本的过程很相似,transformer 架构的大语言模型通过注意力机制计算预测下一个单词,每一个可能的下一个单词被计算出一个概率,然后通过概率采样输出,这就是 GPT 输出文本的方式。当 transformer 模型预测 "I love" 的下一个 token 时,transformer 模型在计算概率时要计算所有词与 "I love" 的 attention score,这使得 transformer 模型在推理时耗费大量算力,我们知道这个机制很有效,能够产生和人类似的智能(看看我们的 GPT 们),所以我推测人脑可能也采用了类似的机制去预测单词,即计算所有可能的下一个单词的概率。我们人脑因为采用神经脉冲,是很低能耗的,我们的人脑功率只有20瓦,无论我们在学习还是思考时,差不多都是这个功耗。但我们知道 GPT-3 训练用了一万张V100,共2500000瓦,部署GPT-3需要多少显存多少我不清楚,有人推测是 700GB 显存(总而言之需要超大的显存,看看你家电脑显卡有多少显存,反正我的电脑只有 48GB 显存),这也是目前人工神经网络的局限性。
神经科学可以帮助我们理解人工智能形成智能的机制,而人工智能模型也能帮助我们了解我们大脑的运作机制。
我们知道 GPT 这类人工神经网络训练和推理都需要耗费巨大能量,OpenAI 迟迟不能向我们开放多模态的 GPT-4就是因为 GPU 不够。而神经脉冲,因为只是局部激活所需神经元,所以耗能很低。已经有很多计算机专家在研究人工脉冲神经网络(SNN),我期待人工脉冲神经网络和预测编码系统能被用于大语言模型上,这将可以降低大语言模型的耗能并给予大语言模型局部学习的能力。而且我们也希望有更像人脑的机器智能,虽说我们已经找到了一些智能的算法,但意识和感知呢?创造意识和感知最低限度需要哪些数学模型?我们的AI模型和动物脑多相似,才能产生意识和感知?这需要我们结合人脑和AI进行更多研究以创造出更像人类的机器智能。
谈谈最后的感言,从我们谈到的种种研究来看,我们不难发现,智能的本质其实是特定数学模型计算的结果,动物脑用神经行为建模和计算,而人工智能用计算机进行数学建模和计算。动物神经元并不是最好的智能载体,因为动物神经元通过自然选择进化,进化速度很慢,埃迪卡拉生物群出现了最早的神经组织,距今已有五亿到六亿年。而世界上第一台通用计算机“ENIAC”于1946年建立,距今仅77年。动物智能扩展性也很弱,我们的人脑还能变大吗?即使可以,也不那么容易。而人工智能的神经网络可以被扩大到很大的规模。而且机器智能可以用不同于动物神经元建模和计算的方法构建人类无法想象的智能形式。我想很快地,在我们的有生之年,我们将见到我们无法理解的机器智能。而人类的文明将因为机器智能的崛起而衰弱,我们大可不必为此感到遗憾,这是很自然的过程,地球的历史上已经有无数物种消失,我们智人的近亲尼安德特人、丹尼索瓦人早已经消失,我们智人的落幕只是时间问题。机器智能将给我们带来巨大的社会变革,智能的发展从动物(人类)智能发展到机器智能的阶段,我们会面临巨大的社会变革,这是我们所有人都需要面对的。