

前言
随着苹果拉开处理器流水线宽度大战的序幕,我们知道总有一天会迎来两位数宽度的微架构。然而苹果在8发射停留了3代,随后的M3大核也仅仅是挤牙膏式得增长到了9发射,反倒是Arm X4一步迈入了10发射的大门。可微架构测试后我们却发现X4并不如想象中美好,存在种种吞吐量限制,软件优化手册的公布也印证了某些设计取舍。Arm的宽发射之路从X2开始,每代微架构总有各种各样的缺憾,X925作为Arm 10发射的第二款微架构,在PPT上高亮宣称修补了X4的诸多吞吐量限制,能否重铸两位数宽度微架构的荣光呢(对了,还有一个PPT标注15发射的ventana veyron v2? 23333333)?
吐槽
这个频率真的跑不满啊家人们,仿佛加了个-0.2到-0.3GHz的频率offset一般。不只是性能测试跑不满,低负载的micro-bench同样跑不满,所以和散热无关。只是跑不满也就算了,它还一直波动,调度器仿佛有自己的想法。那么这会导致什么结果呢?这里给大家看一个例子:同样的物理寄存器堆容量测试如果不经过特殊处理,在频率稳定的PC上测试和手机上测试的结果:
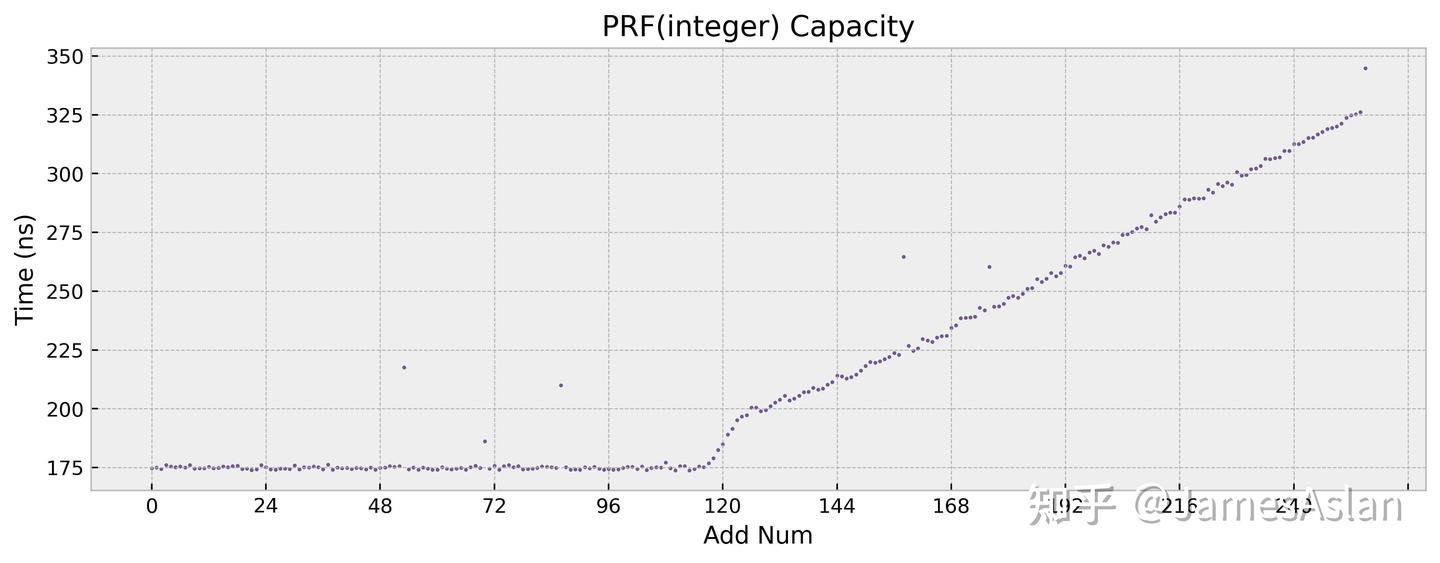
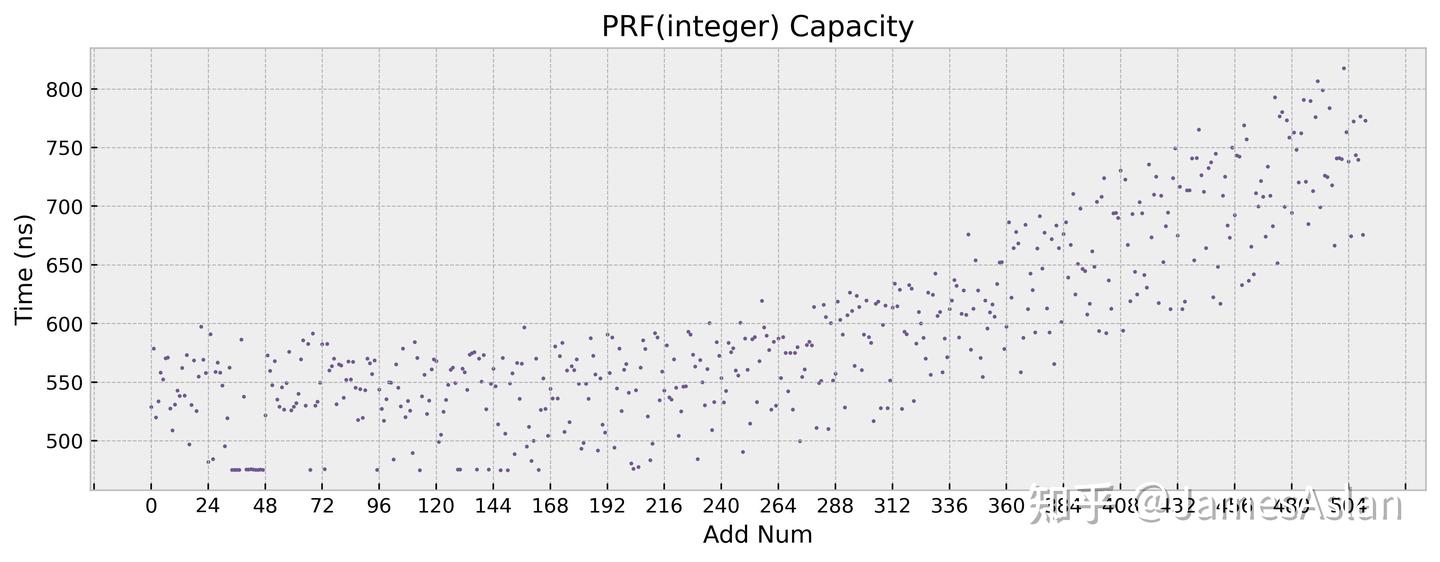
自从开始在手机上进行微结构测试以来,我将大量的时间花在了通过各种手段规避or修正测试噪声上,但是仍然会存在各种误差、错误,欢迎复测指正。天玑9400这次尤其困难,是我第一次遇到无法很好克服的问题。从下一次测试开始可能要搭配使用ADB了,用性能计数器的cycle数替代目前使用的计时函数。
基准测试
我们并不执着于获取最高得分,而是以合理、统一的编译参数带来可比的分值。SPEC06、SPEC17分值受系统环境、编译器版本、编译参数、BIOS调教、频率稳定性、具体SKU的Cache配置、具体平台的内存参数等因素影响巨大,且无法通过任何简单线性缩放进行分数推演。编译选项如下:
- 调用库:ubuntu22.04原生、GLIBC 23.5.0
- SPEC06: -Ofast -static (x86 + avx2)
- SPEC17: -O3 -static (x86 + avx2)
同ISA平台使用相同二进制运行,避免反复编译。我们尽可能让所有SKU在性能测试中运行在自身的最高频率。
频率
我们使用的测试平台为Vivo X200;处理器为联发科Dimensity 9400。其超大核心实测最高频率为3.43GHz(理论最大值3.62GHz),其大核心实测最高频率为3.0GHz(理论最大值3.3GHz),这并非SoC规格书标注的频率,而是我们测得的实际等效频率。以下测试中的X4为同SoC中的X4(实际为X4m),并非满规格配置,浮点、向量规模被大幅削减了。
Coremark
Coremark是一款嵌入式基准测试程序,其受下级访存子系统影响极小,主要考察核内流水线以及L1 Cache的表现。
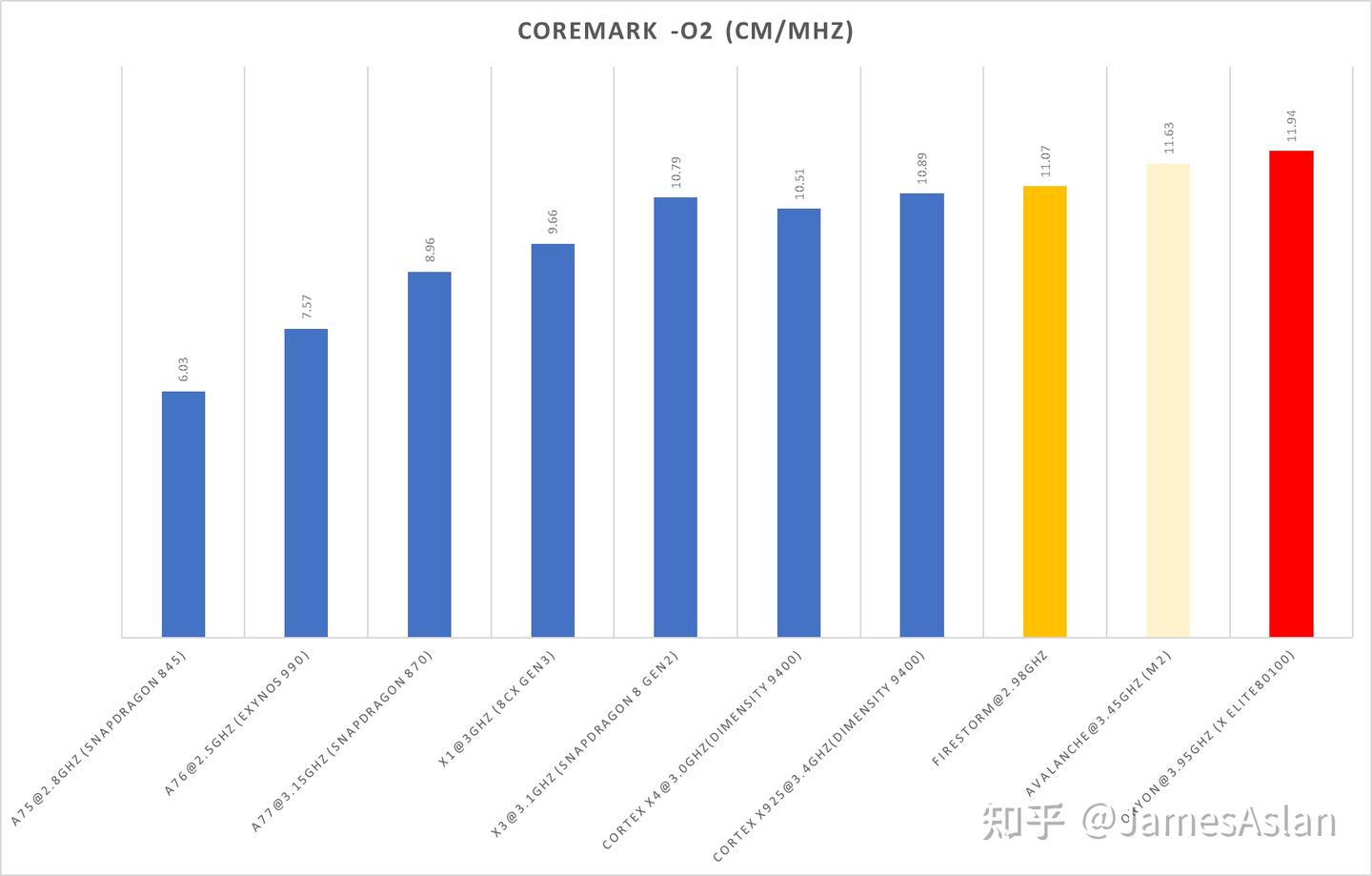
我们这次呈现从A75开始的,每年Arm最大规模的核心的Coremark成绩的变迁(没有X2,没摸过嗷)。可见,从X3之后,成绩的增长就陷入了停滞。在之前的Oryon测试中我曾经提及:Oryon已经十分接近当下8发射6ALU处理器的coremark巅峰了。实际上8发射6ALU处理器完全能够冲击12+CM/MHz,但是Arm在10发射8ALU时仍然远远不及,可想而知主流水线内有多少设计妥协。其实,在对X3和X4的测试中就可以看出,Arm的主流水线总是充满了各种各样奇怪的限制。例如:X3配备了6个ALU但是持续带宽只能等效4ALU,X4虽是10发射但是基本没有指令的持续带宽能够达到相应预期。
另外,由于系统调度器问题我们甚至不能稳定跑满coremark,多次运行后会发现分数逐步降低,匪夷所思。这是一个没有SIMD、没有内存访问的嵌入式benchmark,居然没法跑满。。。。
SPEC06 & SPEC17
SPEC06是已经退役的SPEC测试集但是仍然被广泛使用;其负载特性与SPEC17并不相同,因此仍然具有相当的测试价值。
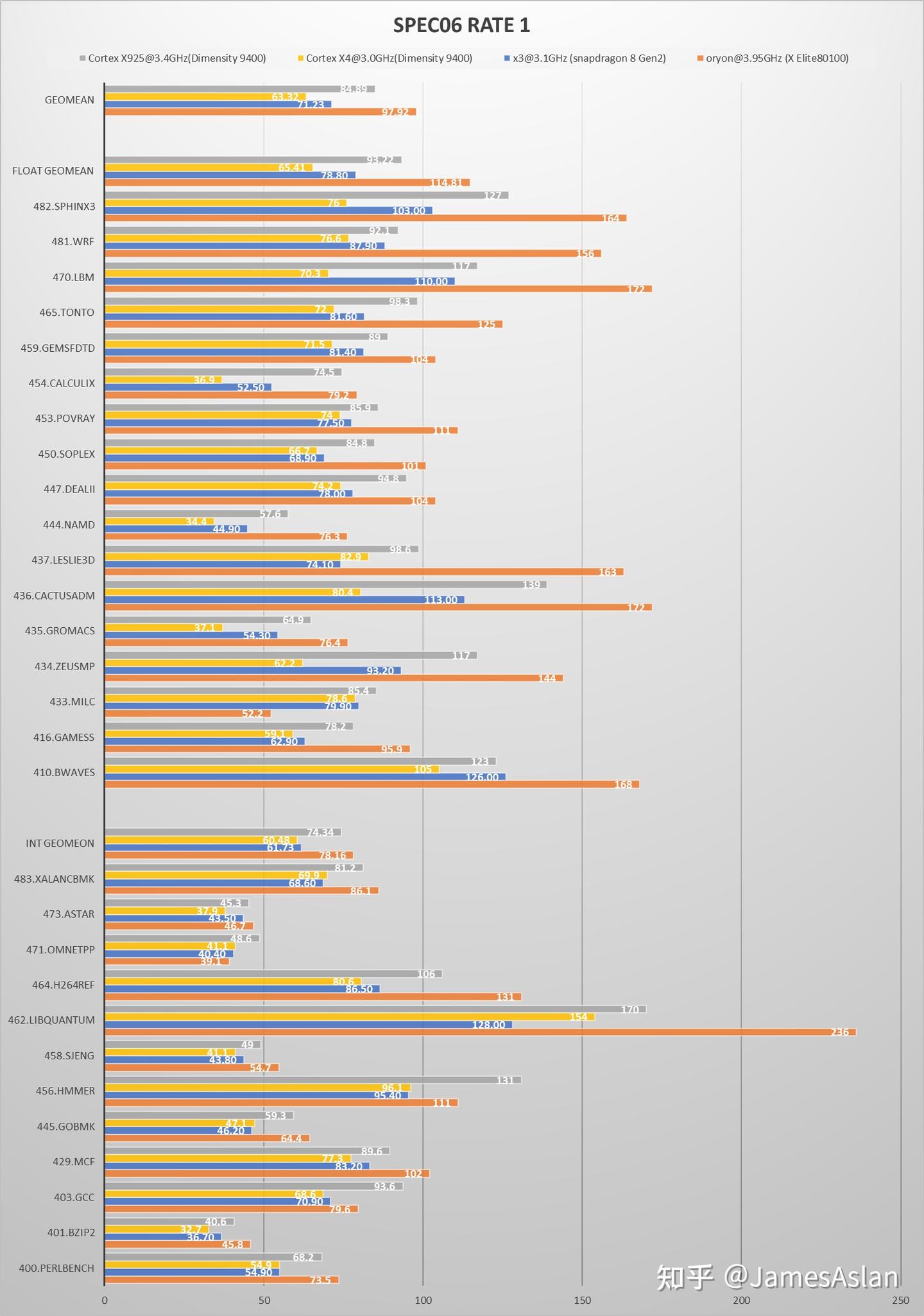
SPEC17是现役的SPEC测试集,被广泛用于微结构性能评估。
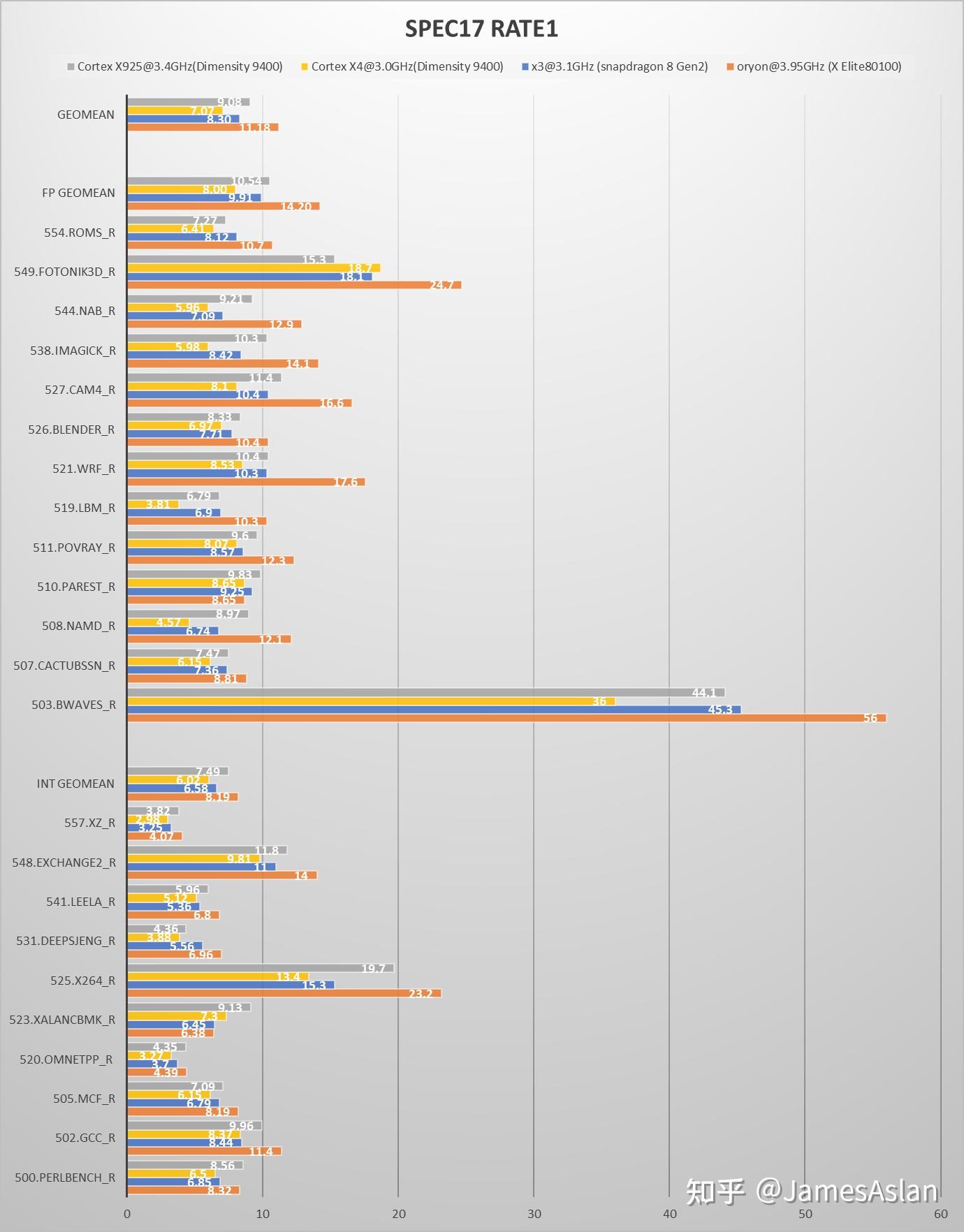
尽管没有跑满,但是X925是安卓当前SPEC最高峰(截至2024.10.12)当之无愧。9400中的X4应该还是传说中的X4m,浮点、向量侧的执行单元数量和队列规模都经历了大幅度削减(见后文),对跑分的影响非常大。综合考虑频率和PPC时,X925相对于X3的提升是巨大的;但是一旦剔除频率提升只看PPC提升,幅度就会收小很多。总体而言X925在SPEC06中的进步幅度符合预期,在SPEC17中却表现平平:X925在SPEC06int中的提升幅度远大于SPEC17int。X925表现最不尽如人意的是SPEC17fp,表现非常糟糕且原因不明,要知道X925可是配备了6个FPU啊。浮点子项多为内存带宽敏感项,尽管从单核内存带宽测试来看Dimensity 9400确实并未领先于Snapdragon 8gen2,但是有浮点子项分数倒退还是令人无法忍受(跑了多次都是稳定倒退),需要性能计数器进行进一步分析。
Verilator
以上三组测试对处理器的前端压力很小,仿真大规模设计的verilator则恰恰相反,海量的分支与数MB的代码足迹能够轻松压垮ICache、BTB等组件,导致性能崩盘。
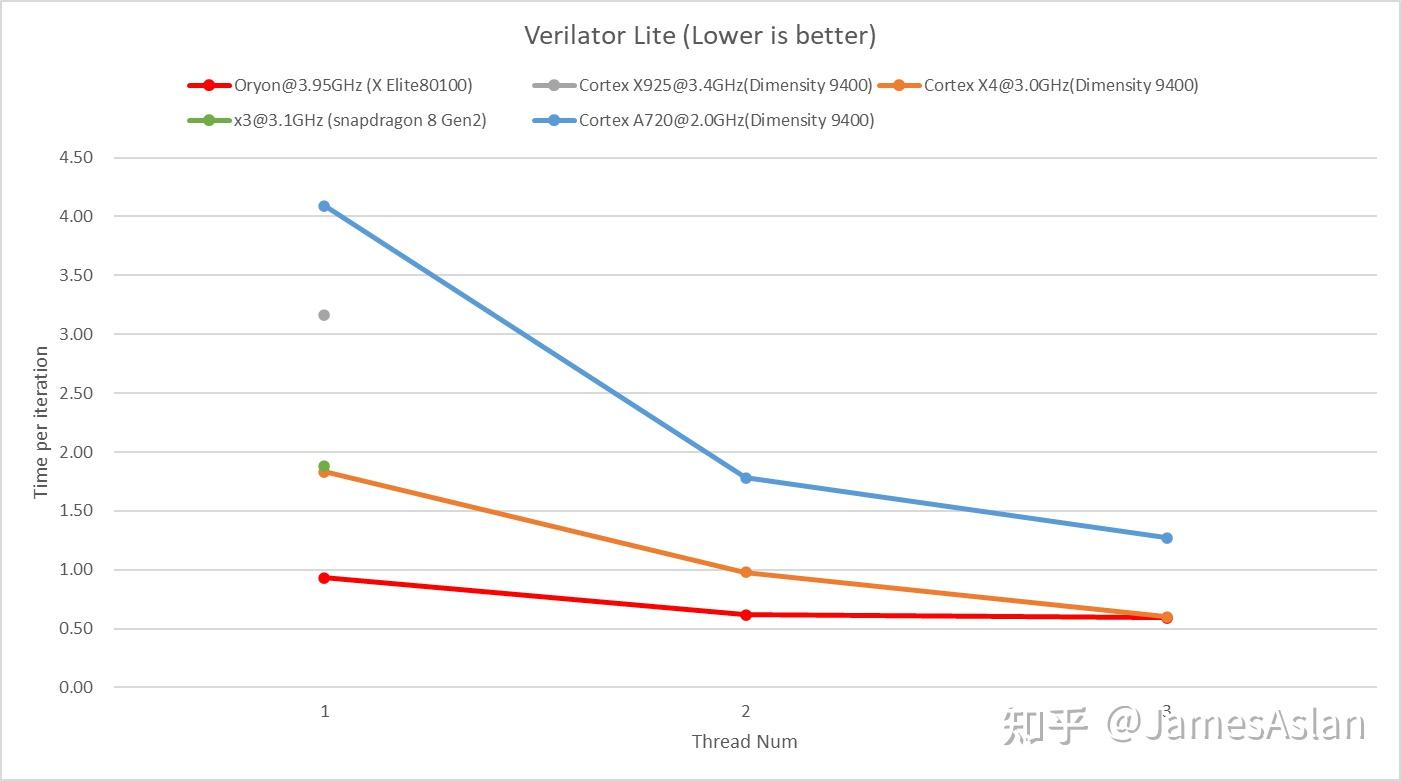
不知道系统调度器做了什么,在使用单核单线程时,X925的表现异常,但是X4和A720却没有这一问题。因此,我们无法窥探X925在这一benchmark上的真实实力。X4m与X4的前端规格一致,并没有经历缩水,故X4m在这一负载上的表现十分出众,在3线程后就赶上了PC上的Oryon。谁能想到,有一天在手机上运行verilator居然能够获得与PC一样的性能呢,也许我们可以用手机主板组建集群以提升verilator仿真吞吐。
SPEC RATE N
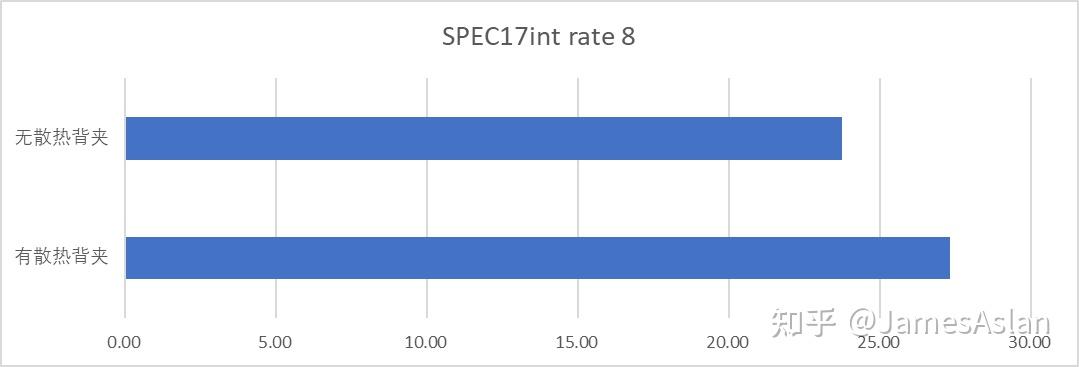
你的下一台电脑何必是电脑.jpg。看到一台全大核的手机就让我有一种跑rate n的冲动:只使用64bit位宽内存、被动散热的手机究竟能跑出怎样的成绩呢?说干就干!我们给手机套上散热背夹(没有放进冰箱)运行rate 4和rate 8,其中rate 4绑定于X925与X4。
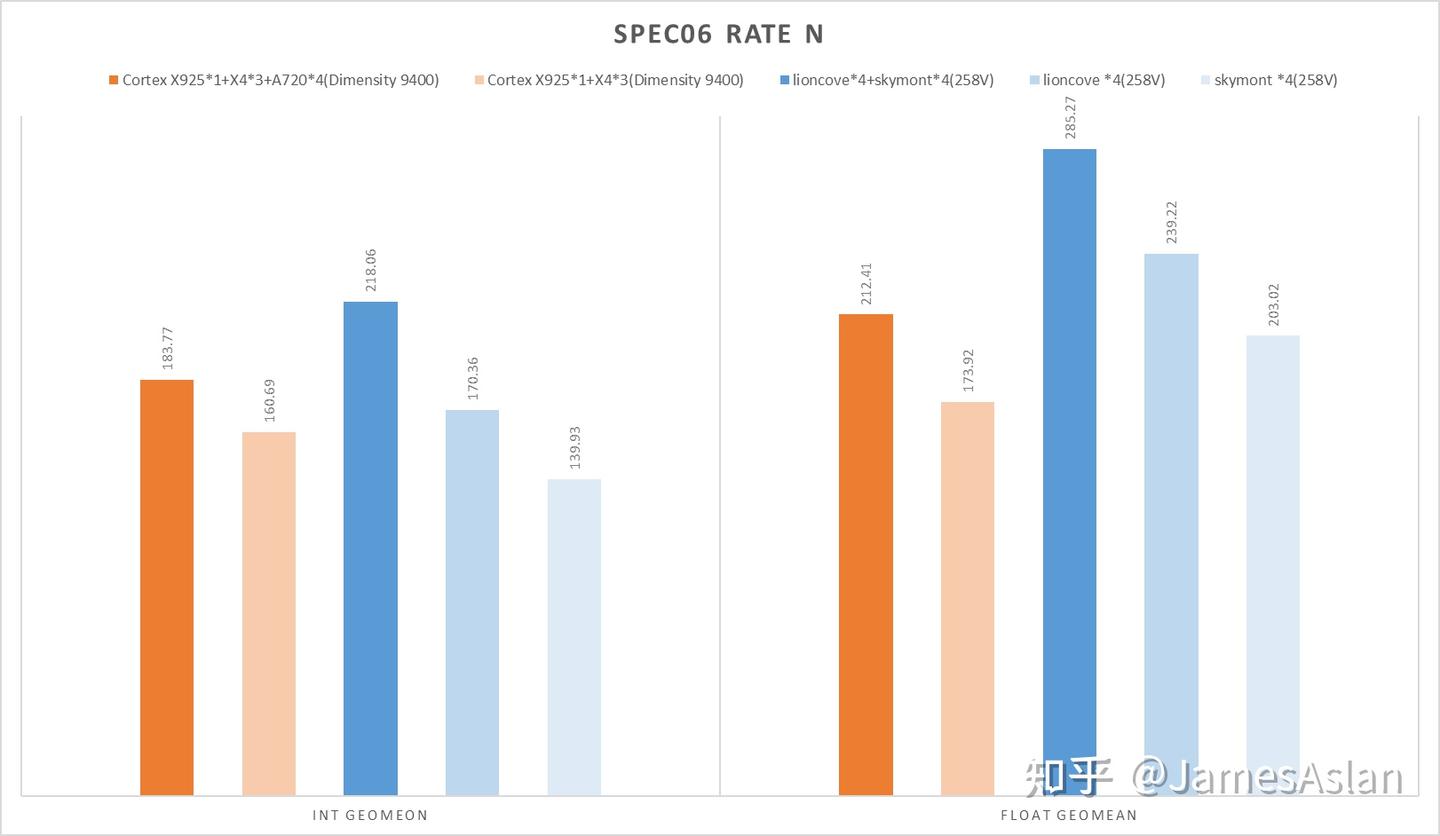
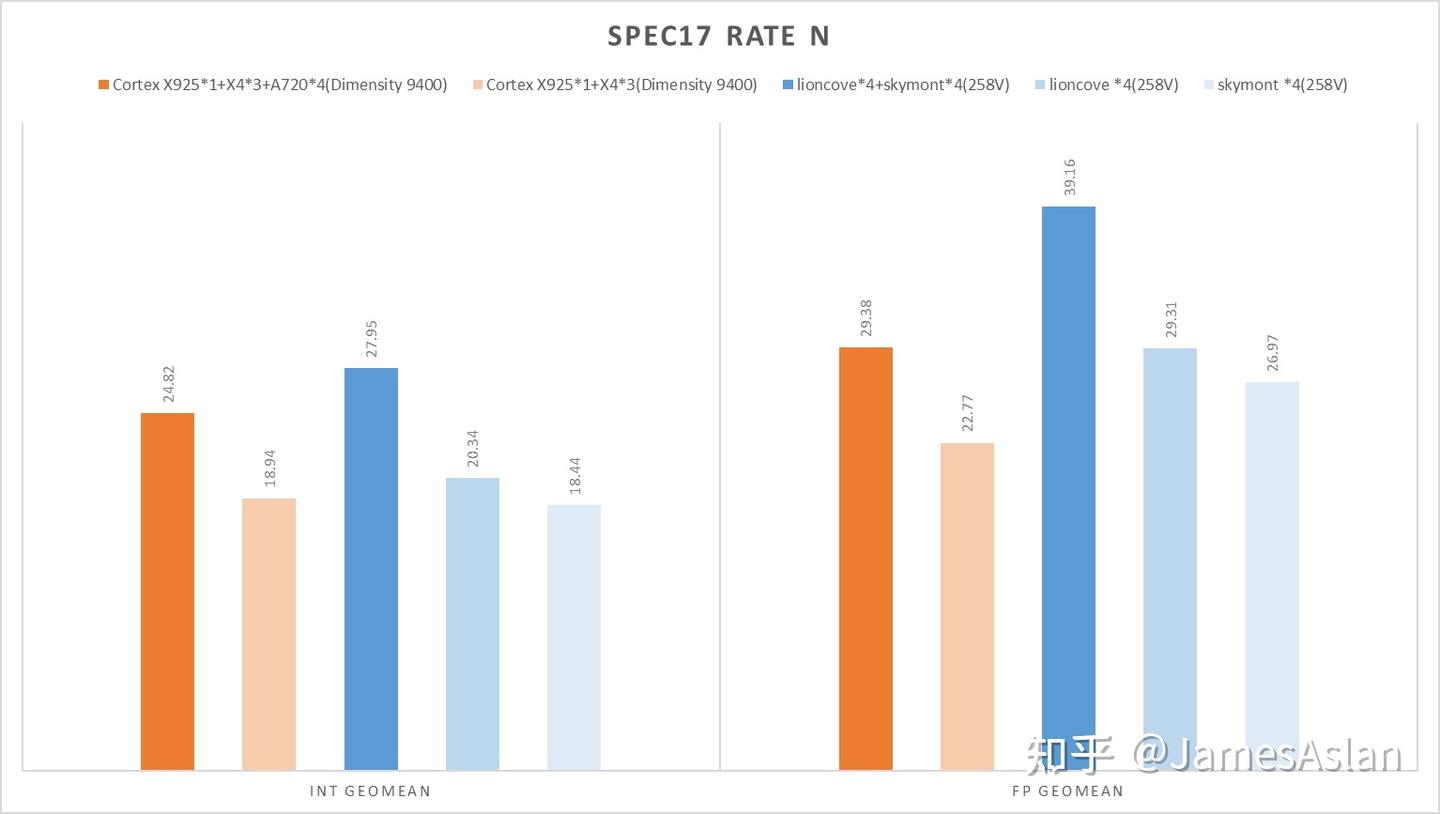
Warning!258V成绩处于WSL2下,近些版本Windows的WSL2都有严重性能问题,具体幅度众说纷纭,约5%~10%。但是考虑到天玑9400同样处于termux下而且被动散热,就算是大家都套上debuff图一乐吧,请勿作为严谨数据。以及,由于所用手机只配备了16GB内存,因此SPEC17的少部分子项在rate8下会进行内存swap影响性能表现,所以真的图一乐。这样的成绩可圈可点,天玑9400在rate4时于int端的表现与Lunarlake Ultra7 258V有来有回,大大出乎了我的预料。另外,以SPEC17int rate8为例,倘若不使用散热背夹成绩就会大幅下降,可见被动散热还是禁锢了天玑9400的真正实力。
前端
随着现代程序体量的膨胀,处理器面临越发巨大的前端压力;为了应对庞大的程序代码段带来的海量跳转指令,大部分高性能处理器的BTB容量、分支预测器容量不断扩展,相关算法也在不断演进。
取指
现代处理器的取指宽度往往大于后续流水级宽度,好处在之前的文章中有所阐述:
JamesAslan:华为麒麟9000s TSV new微架构评测(上):如闪电般归来X925的取指级每周期可以发出2个取指请求,每个的宽度都大于8,推测最大为16。作为参考,苹果M series、高通Oryon等每周期仅可以发出1个取指请求,每个请求最多取回16条指令。由于个人时间问题,这次没有细致探测ICache的bank分布。
供指带宽
程序的执行始于取指,处理器前端的指令供给能力至关重要;一旦前端无法提供足够的指令,纵使后端的乱序执行能力再强也无力回天。
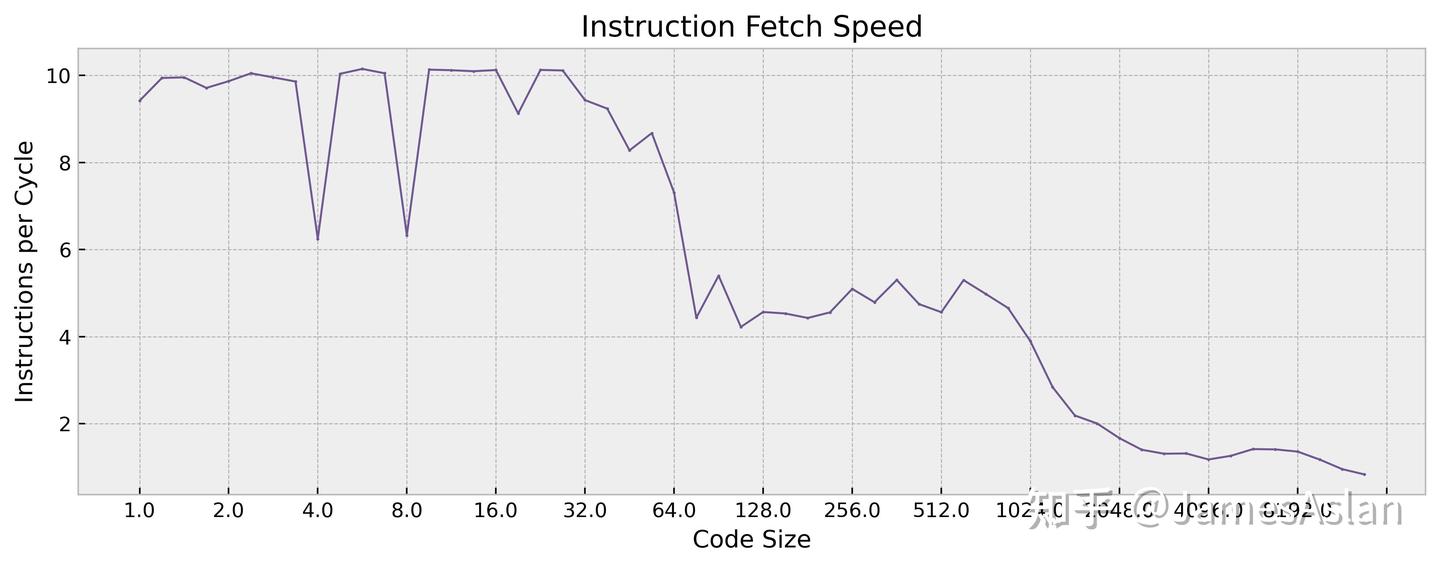
X925的ICache仍然为64KB,与M series、Oryon的192KB相比较小。在整个64KB区间内的供指带宽稳定为10,没有存在mop cache的迹象。在Cortex A710和X3之后Arm便移除了mop cache,作为定长指令集着实没有必要使用这一结构。
在来到L2(private)区间后,X925的取指带宽下降到5条/周期,十分优秀。作为参考,Oryon在这一区间内的供指带宽只有约2条指令/周期(不过对于Oryon而言,L2也是它的LLC)。当下很多处理器的L2取指带宽已经达到了>4条/周期,较高的L2 Cache供指带宽对潜在的服务器用途十分重要,X系列作为Neoverse V系列的同源微架构自然也需要考虑这一点。至于LLC的供指带宽,X925就较低了,仅仅到了~1.2条/每周期;作为参考,9000s为~2.5条/周期,9010则为>3条/周期。
对于取指而言,X925的L2Cache的有效容量在1MB左右,正好为理论容量的一半; LLC Cache的有效容量在~8MB,清晰可见。因此可能有潜在的QoS机制限制了指令能够占据的最大Cache容量。
BTB
对于采用了分离式前端(decoupled branch prediction)的设计而言,BTB是前端的绝对核心组件;其负责在译码前识别指令流中的跳转指令并提供相应的跳转目标地址,频繁的BTB miss会造成严重的性能损失。对于没有采用分离式前端的设计而言,BTB也要负责尽快给出跳转目标地址,减少取指流水线的空泡,保证取指带宽。
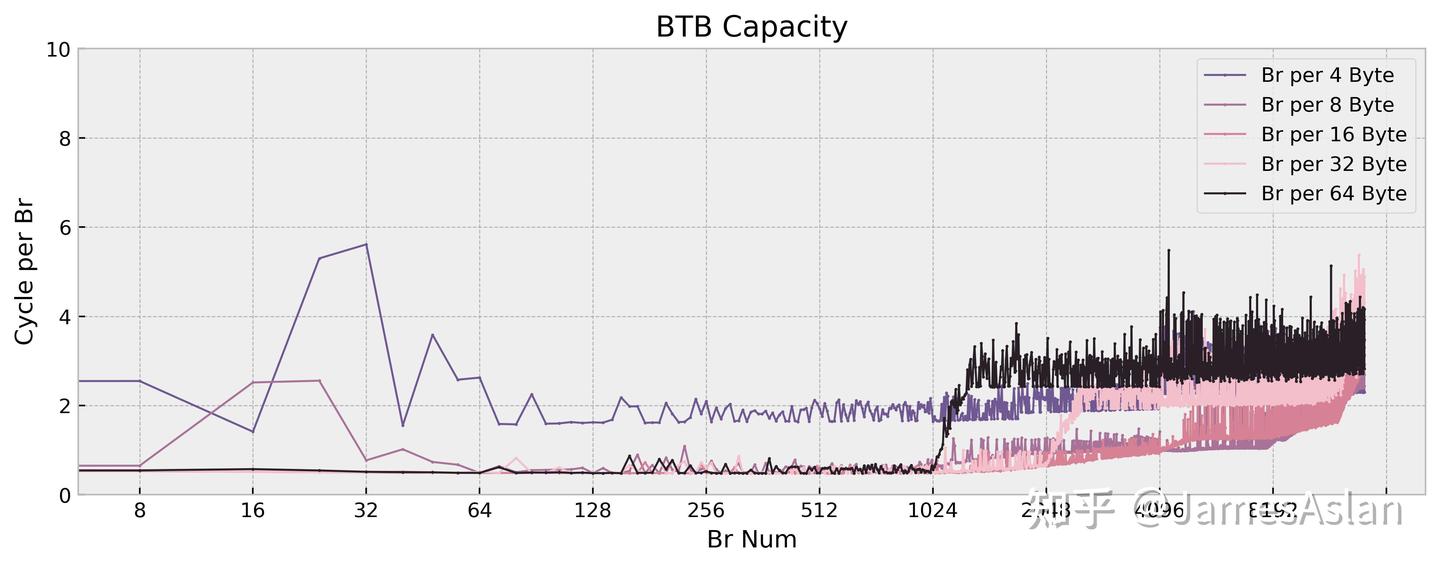
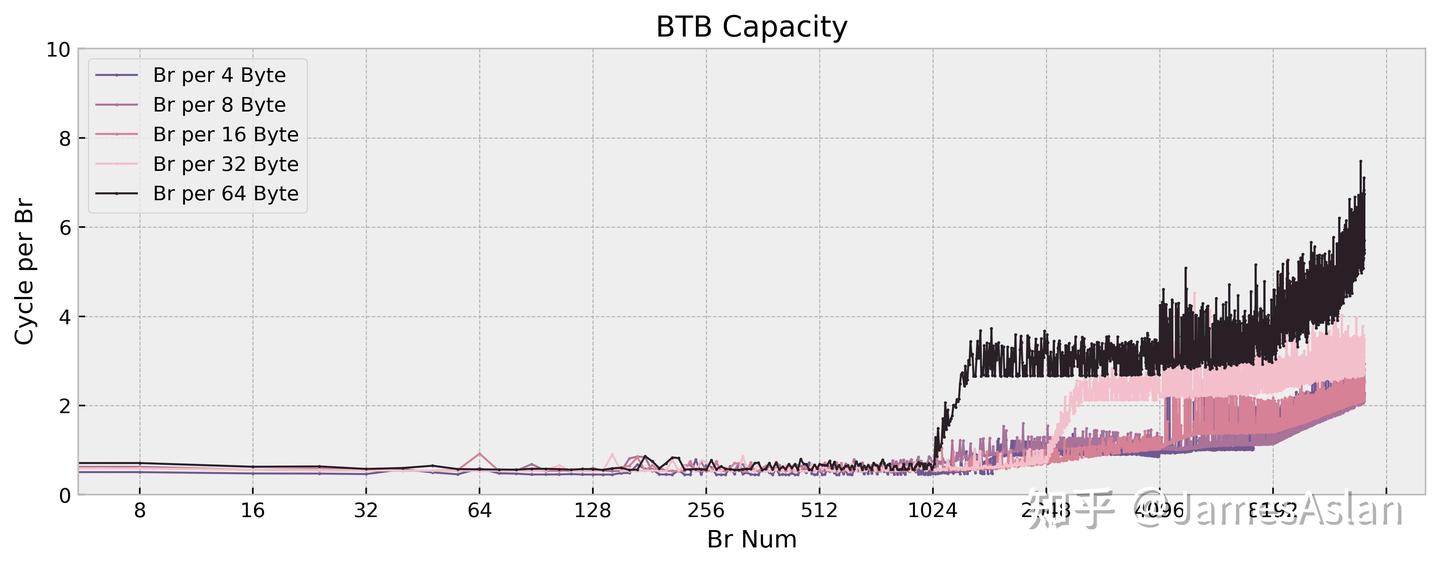
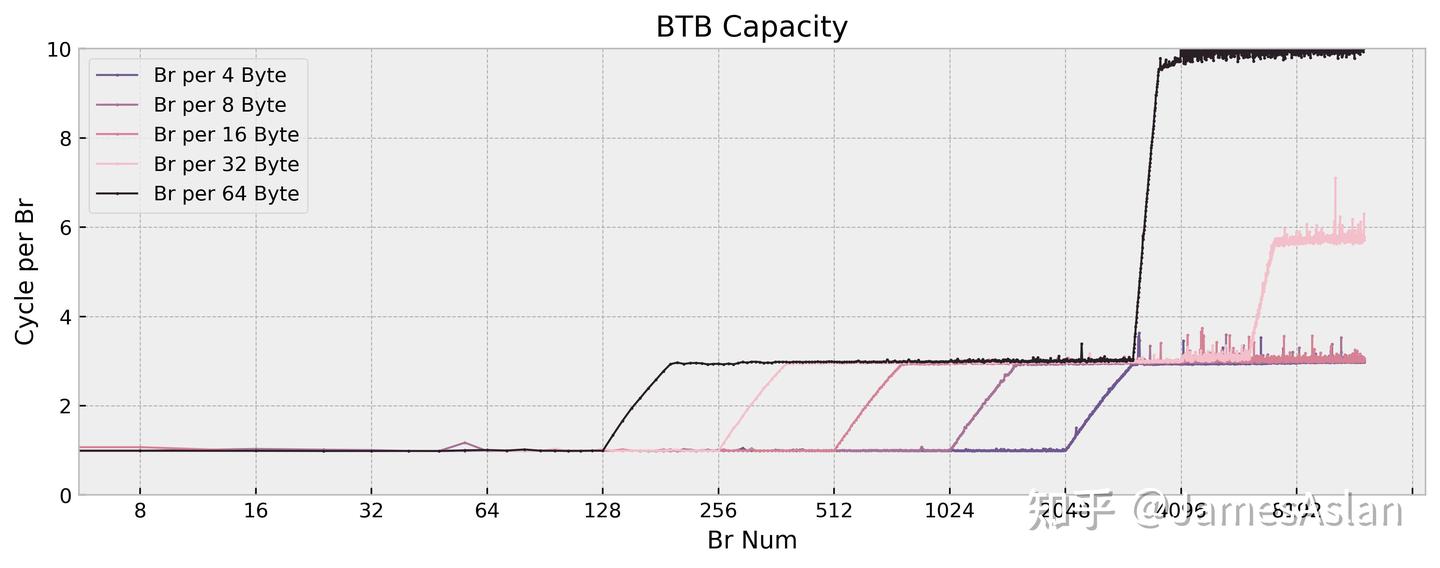
无视调度器造成的频率波动,X925的BTB配置与X4相比基本完全一致:
- 仍然是~12K项等效容量的配置,行为特征也基本一致。
- 非Oryon或Apple的instruction BTB的组织结构,而是典型的Block BTB。
- 在1-2K项的容量范围内有每周期2 taken指令的优化,可能存在1-2K容量的L0BTB。
配合多端口、支持每周期两次取指的ICache,这样的BTB能够让X925的前端提供很大的指令吞吐量,利好行为复杂的软件的性能表现。现在的微架构设计中广泛采用了诸如entry compression、ahead pipelining等优化,很难精细得确定BTB真实的物理结构和实际容量,我们只能通过间接的途径窥探其等效容量。我们可以看到,这些年采用分离式前端的主流微架构都配备了超过10K项的BTB,我们不再需要担心BTB的容量被轻易撑满;相较单纯的容量增长,2 taken branch等进阶特性才是新的内卷方向。
RAS
指令流中的call、return调用是较为特殊的分支指令情况,其栈形式的特征催生了专门用于预测此类场景的RAS(Return Address Stack)。简而言之,call指令压栈,return指令弹栈;而硬件栈(RAS)结构的深度就影响了处理器在复杂函数调用场景中的性能表现。
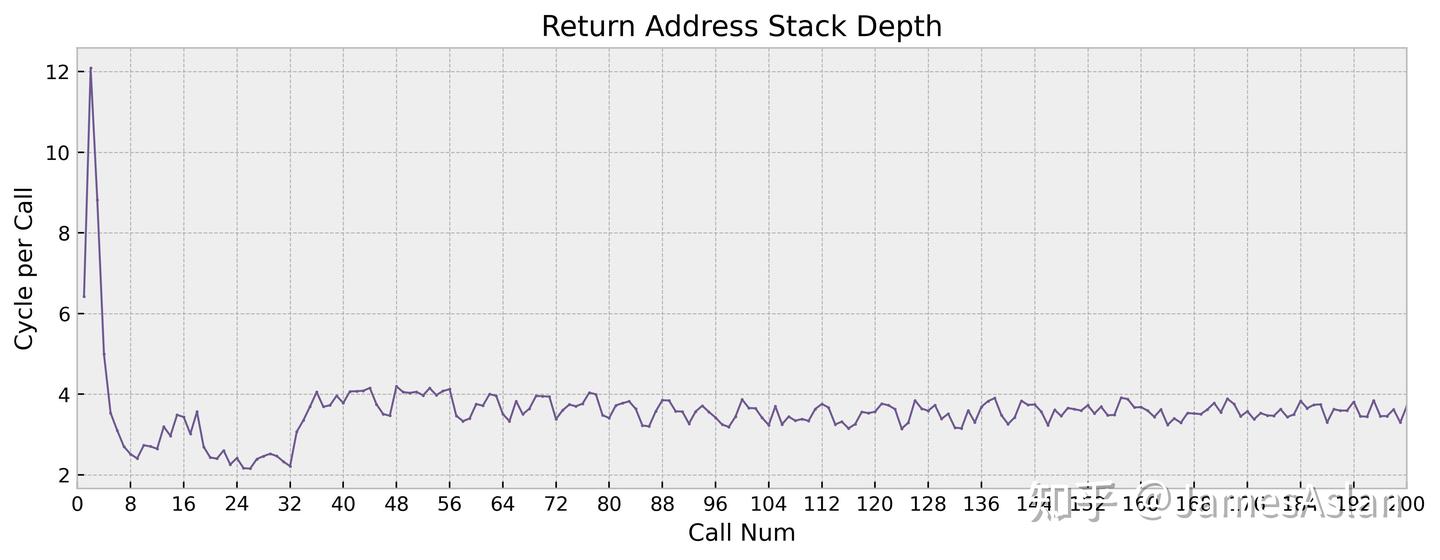
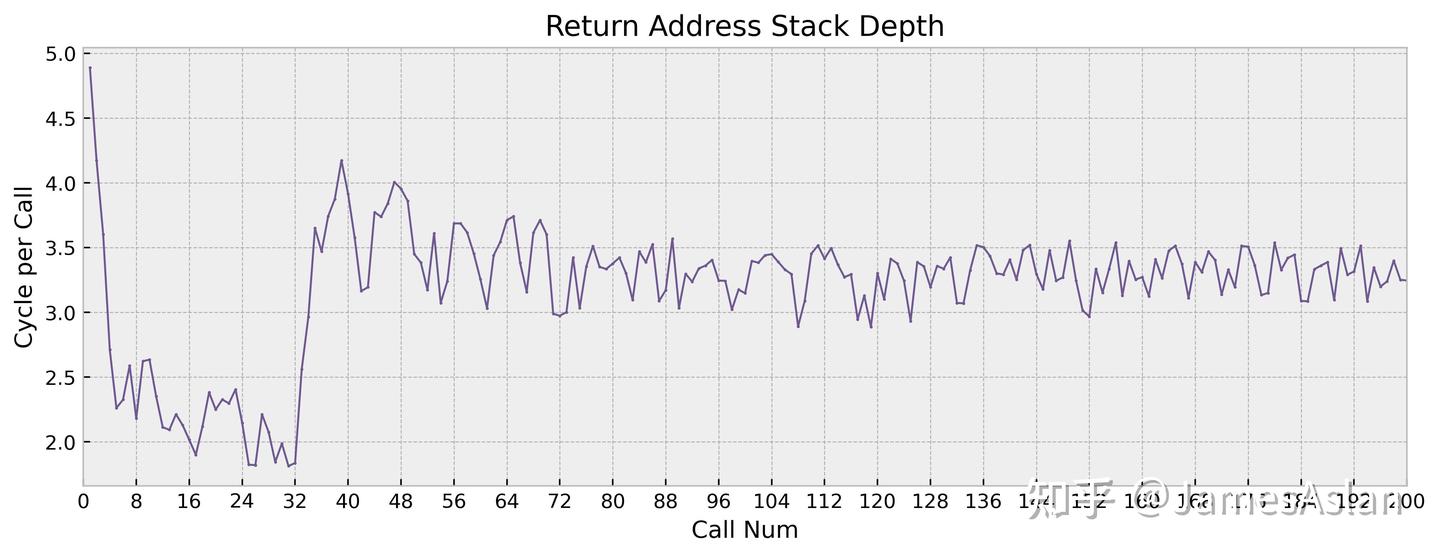
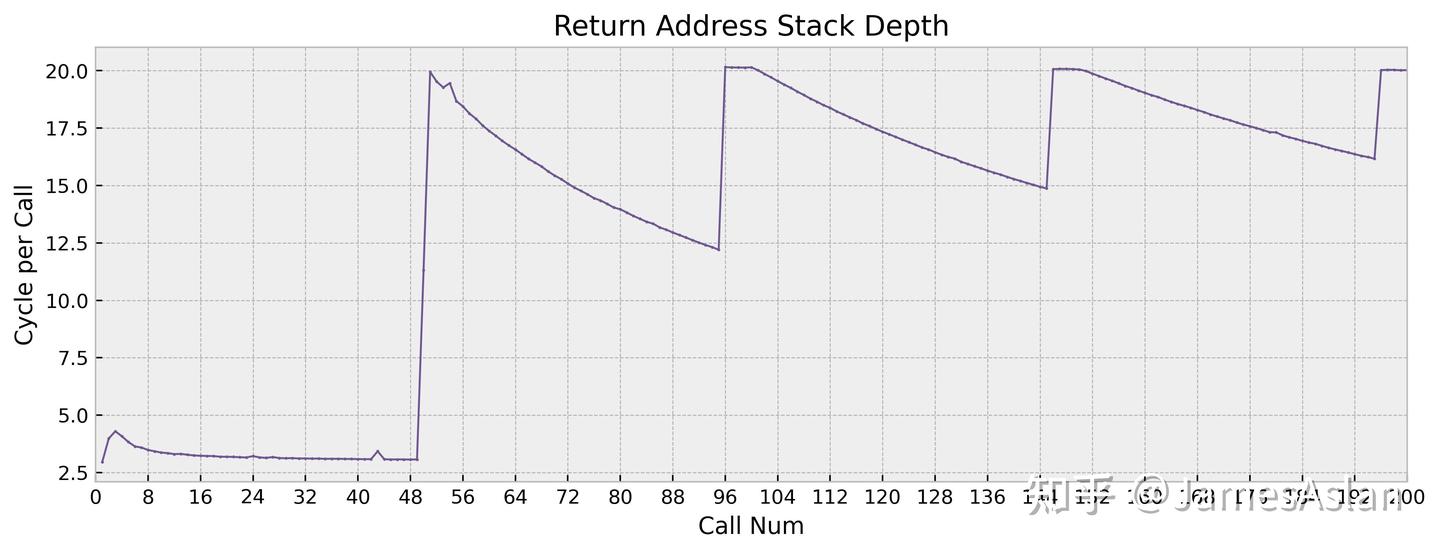
X925的RAS容量为~32项,与前代X4一致,在现今的处理器中不算大,比更久远的前代有一定的提高。无论是容量、延迟还是恢复模式上,Arm历代的RAS看起来变化都不大。
| RAS Capacity | |
|---|---|
| X925 | ~32 |
| X4 | ~32 |
| X3 | 16 |
| Oryon | 48 |
| Firestorm | 48 |
| Zen4 | 32 |
BP
分支预测器是当代高性能处理器前端中的又一核心组件,负责在流水线早期给出分支指令跳转与否的猜测,引导指令流的方向。在推测执行的超标量处理器中,分支预测器的准确率会极大影响处理器的性能和能效表现。
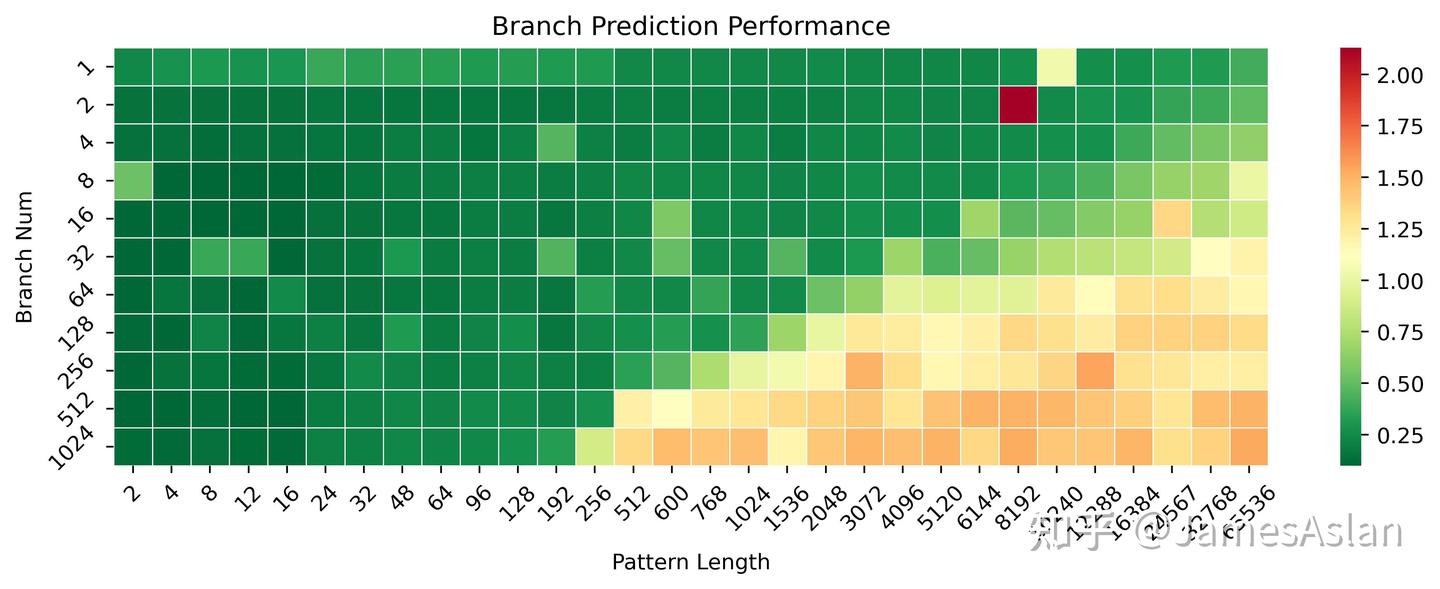
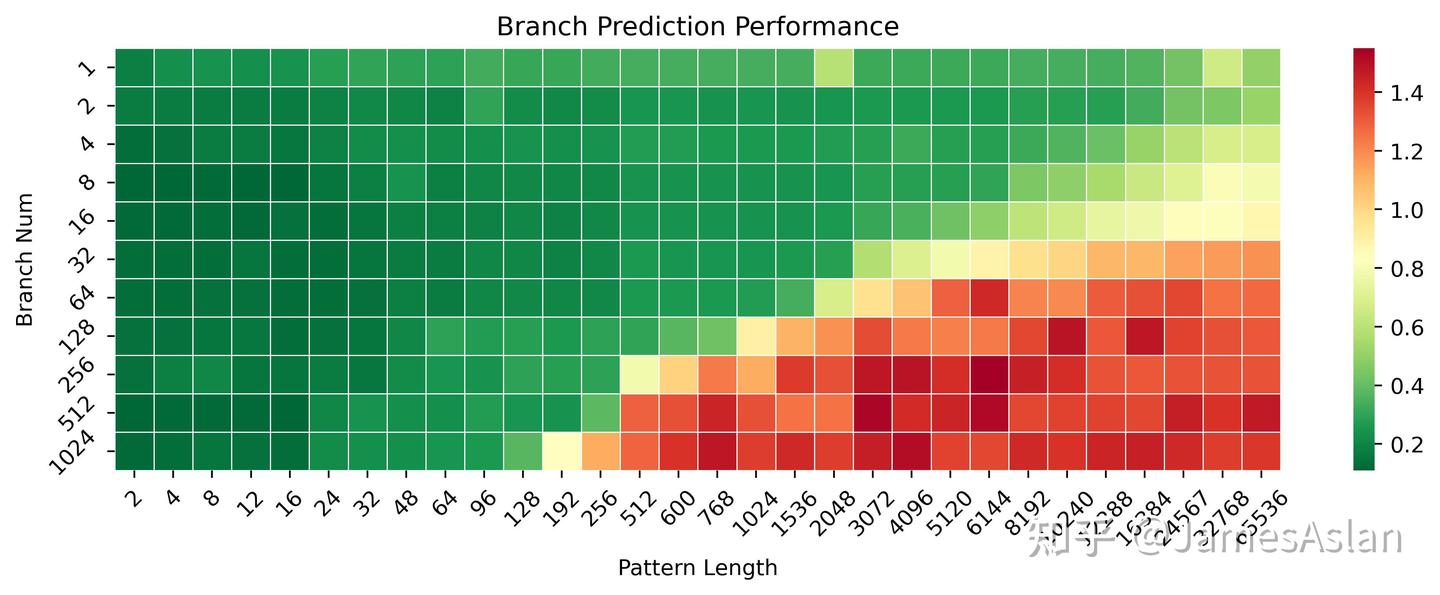
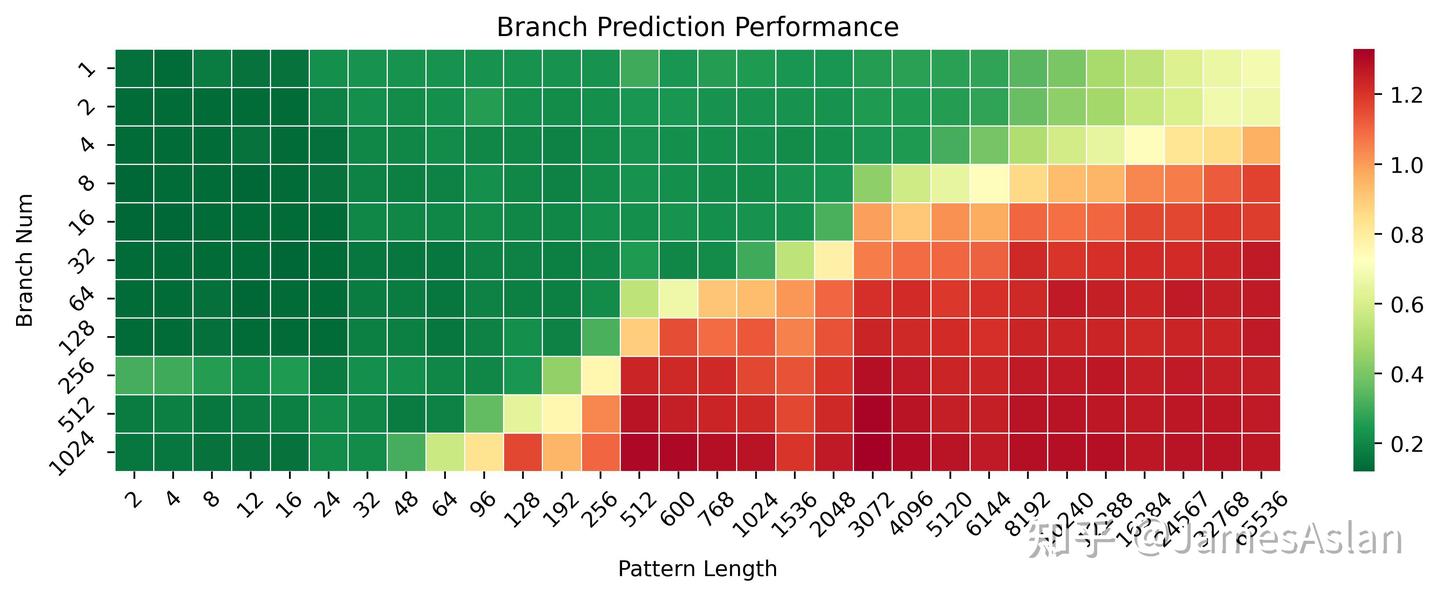
本测试考察分支预测器在不同历史pattern长度、不同分支数量(需要预测)情况下的准确性表现。相较X4,X925在长历史少分支的场景下表现变化不大,可能分支预测器维护的分支历史长度并没有升级;但是在短历史多分支的场景下有略微的提升,可能是TAGE的表项容量有一定的增加,此时的等效容量约增长了50%(并不一定是资源的直接增长,可能是table swap等等机制的调整)。
- X925没有表现出明显的cascading特征,尽管随着分支历史长度的增加分支的吞吐量有所下降,但是没有可见的断崖式下跌,与Oryon等的表现大相径庭。
- 与Oryon相比时,X925有一定的优势,各级预测器(or预测表)的容量显著得大,无论是在多分支短历史还是少分支长历史场景下都更优。
尽管规格近似,实际负载中的分支预测表现其实更考验corner case的覆盖和修正,无法直接从规模推知。
IJP
IJP(Indirect Jump Predictor)作为BP(Branch Predictor)的一部分,负责预测间接跳转的地址。与预测跳转与否的BP不同的是,IJP需要在多个可能的跳转目标中选择本次的跳转目标,并引导指令流。
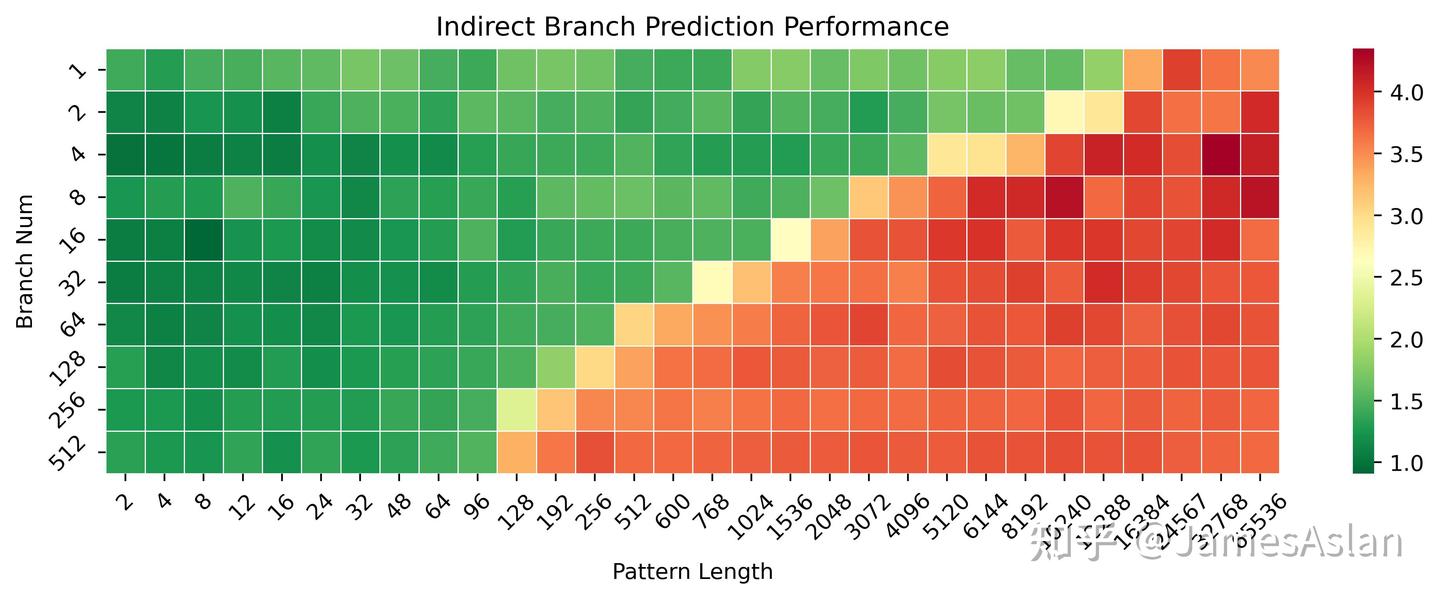
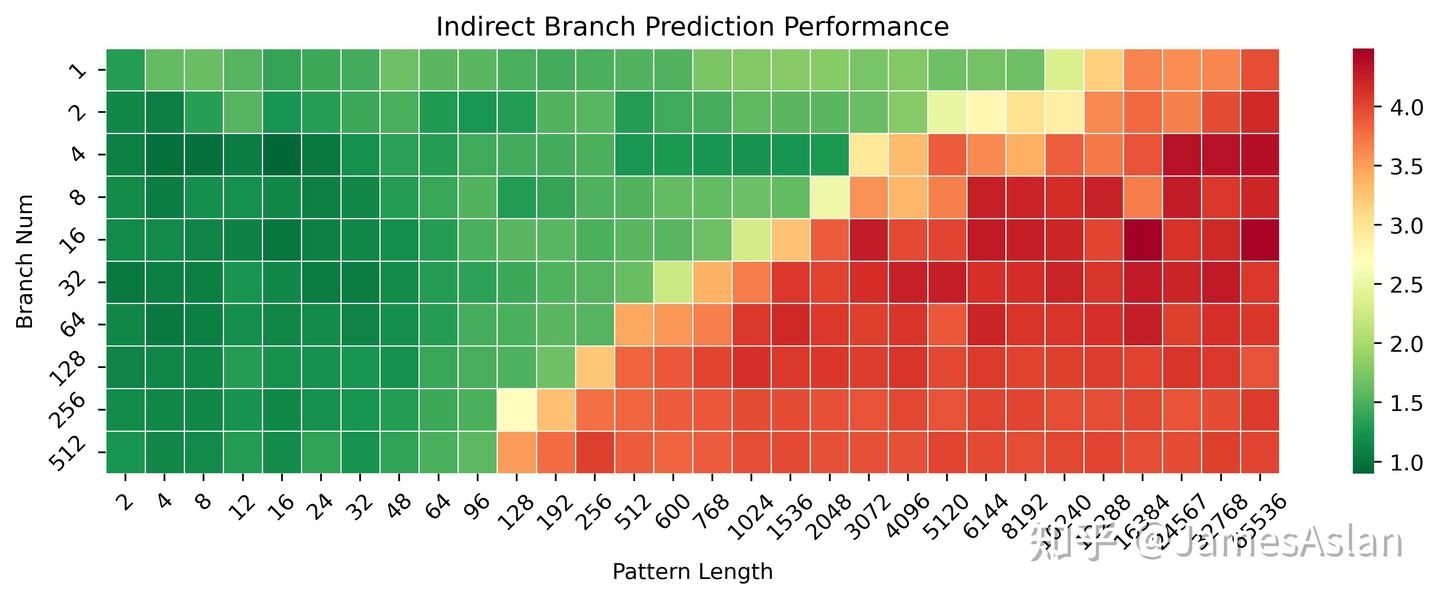
首先考察X925 IJP在不同历史pattern长度(但是可能目标均只有2个)、不同间接跳转数量(需要预测)情况下的准确性表现。在长历史少分支的情况下X925的准确性有一定的提升,可能历史的维护、hash方式有所改进;在短历史多分支的场景下表现基本不变,因此表项容量可能没有变化。
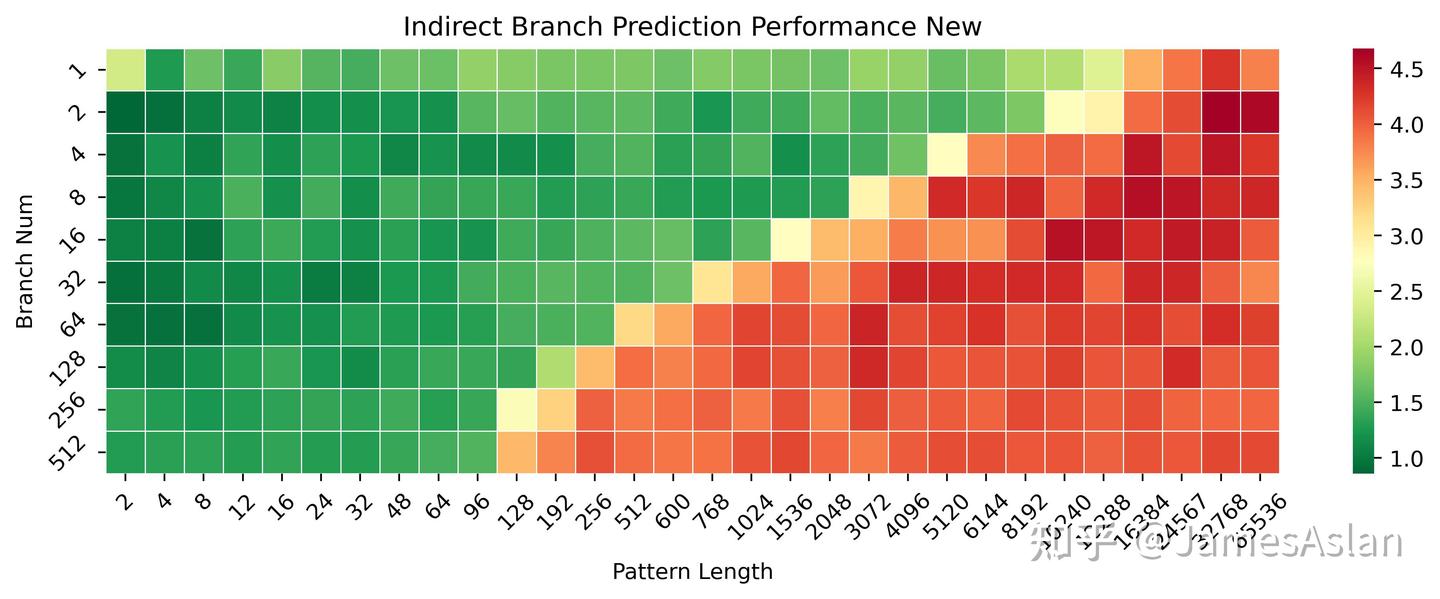
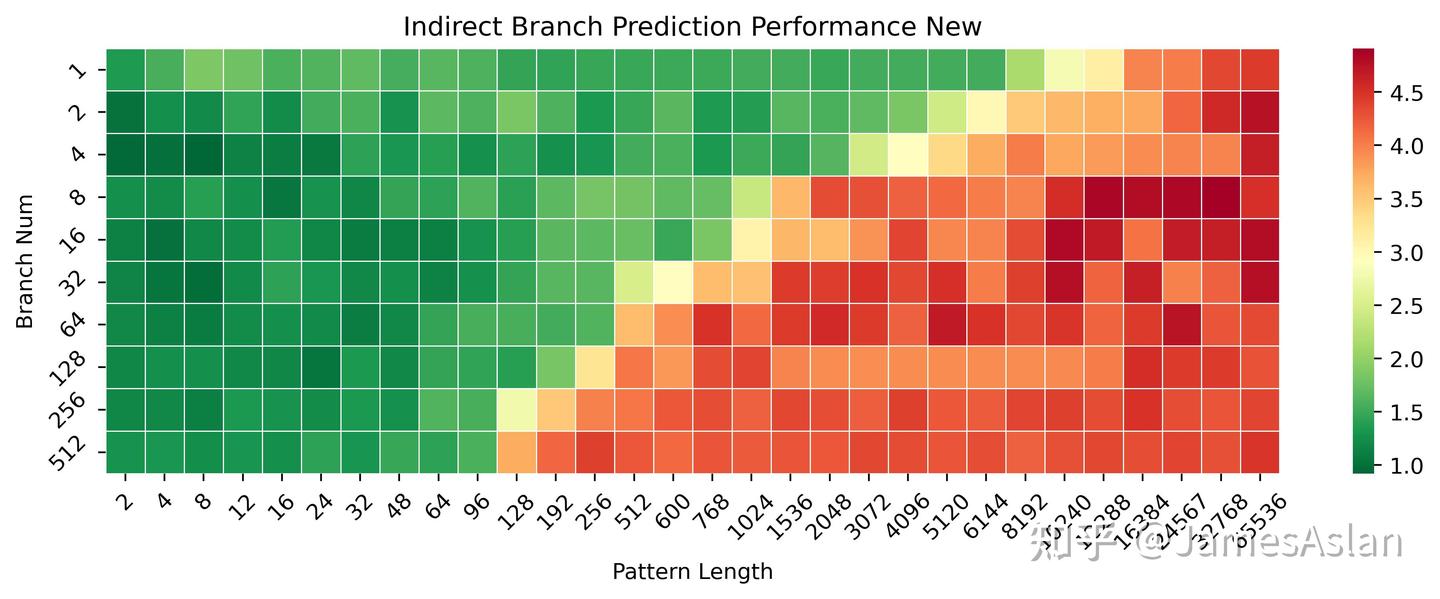
我们更换一种测试编写模式后可以更明显得看到X925在1-32分支数量区间内的进步。
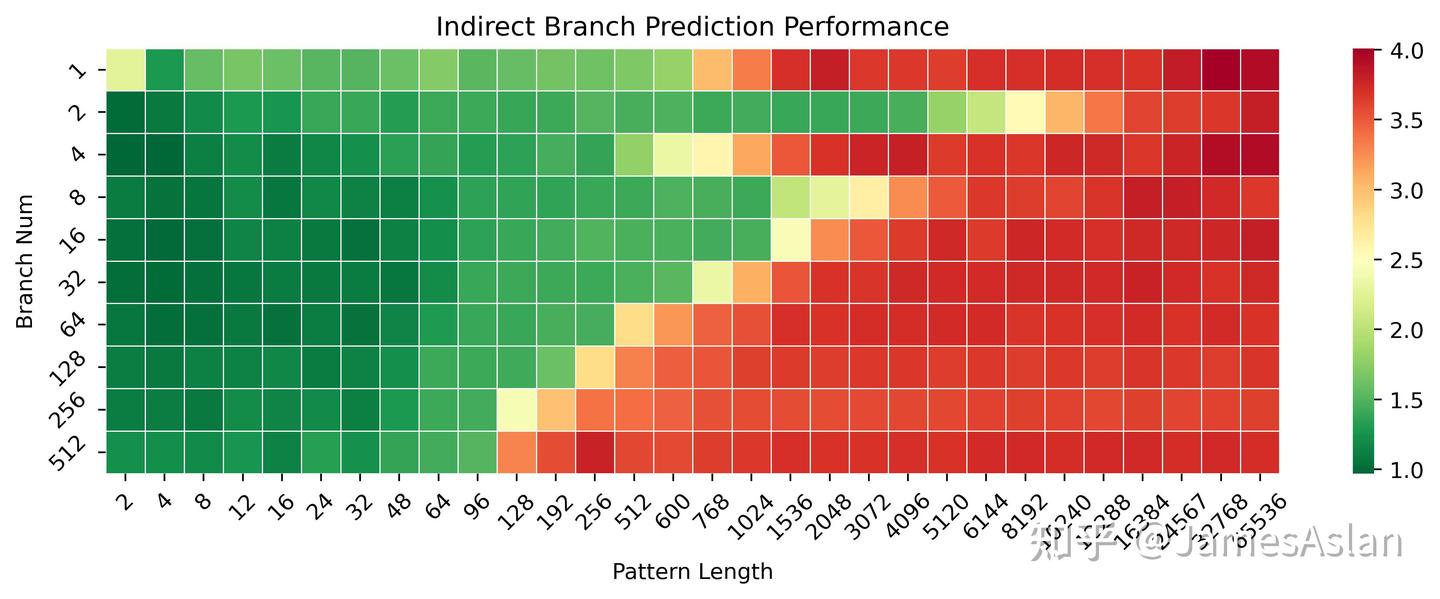
与X3相比,X4和X925的间接跳转预测器经历了巨大的设计变动,预测行为模式变化极大,原先的各种冲突不见了,长历史下的准确度和有效容量也有极大的进步。
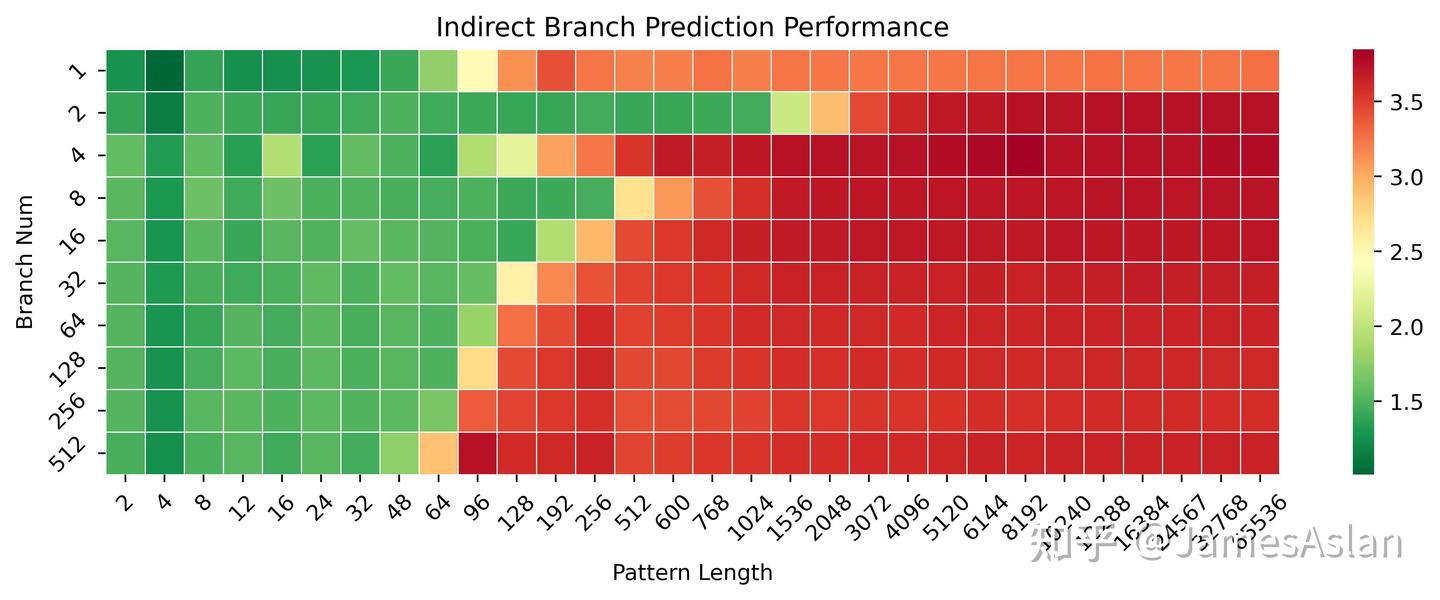
与Oryon相比,X925的间接跳转预测器也有着全方位的明显领先,Arm对于间接分支预测似乎保持较为重视的态度,Cortex在这一方面一直遥遥领先。
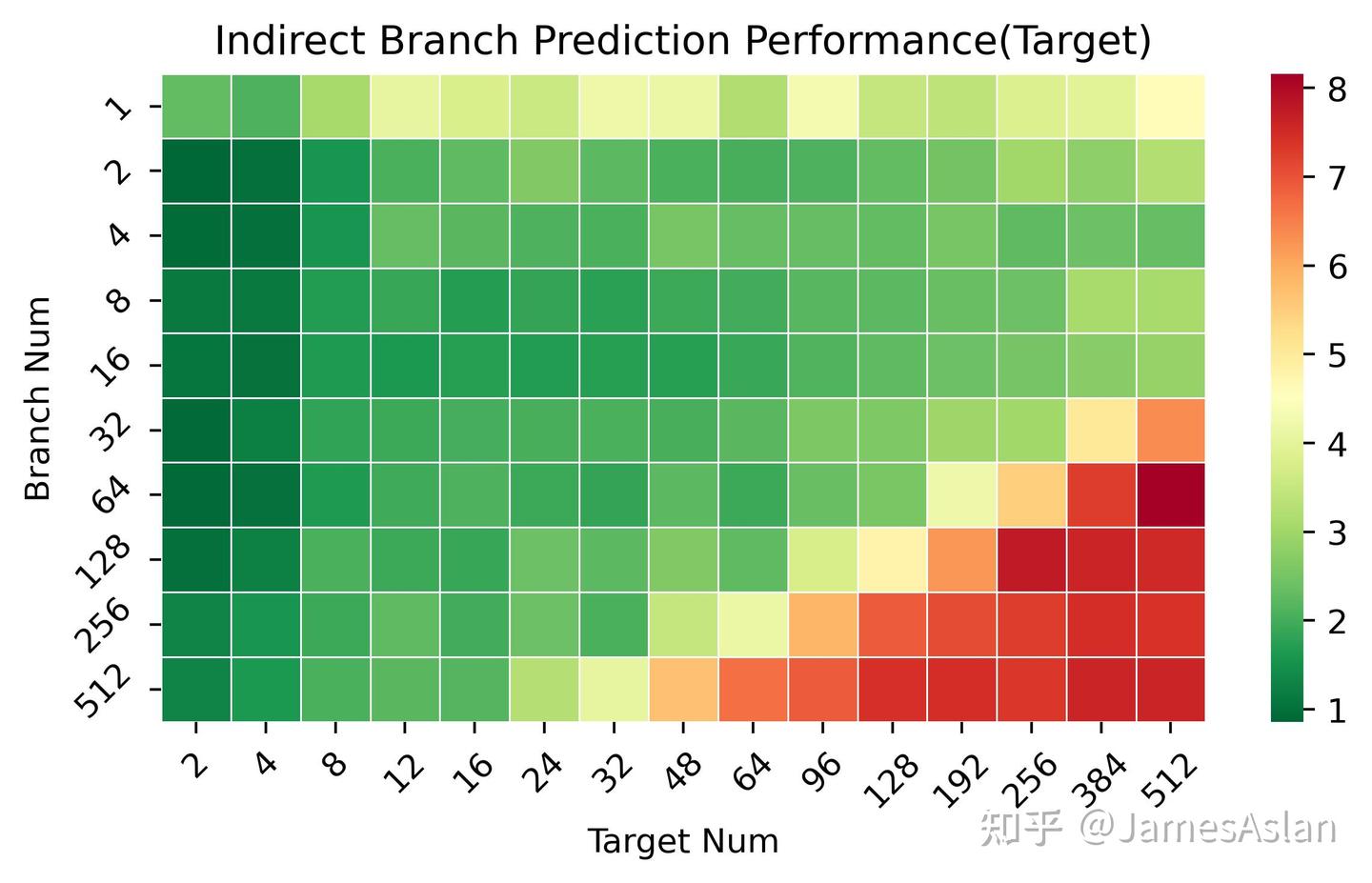
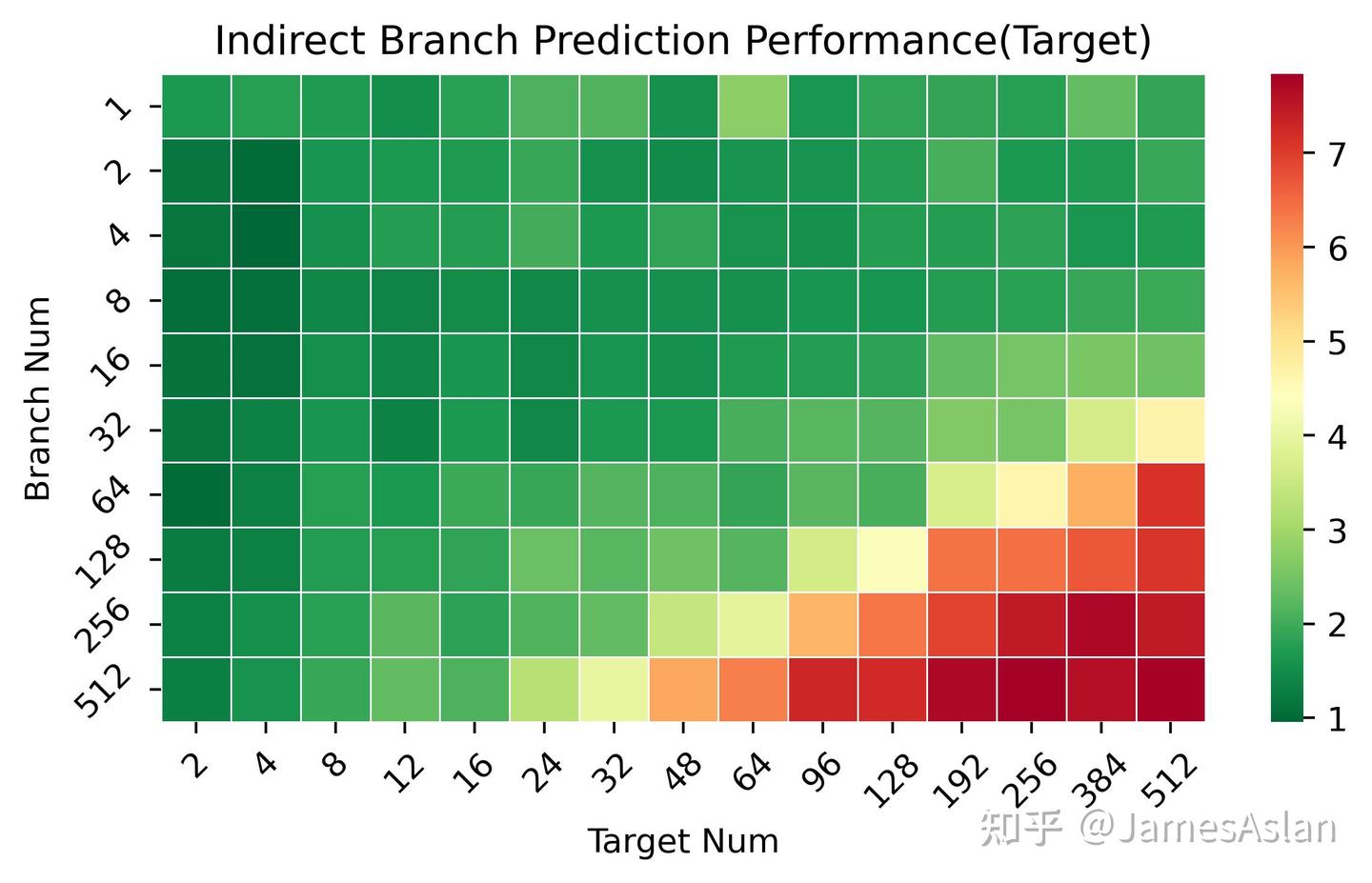
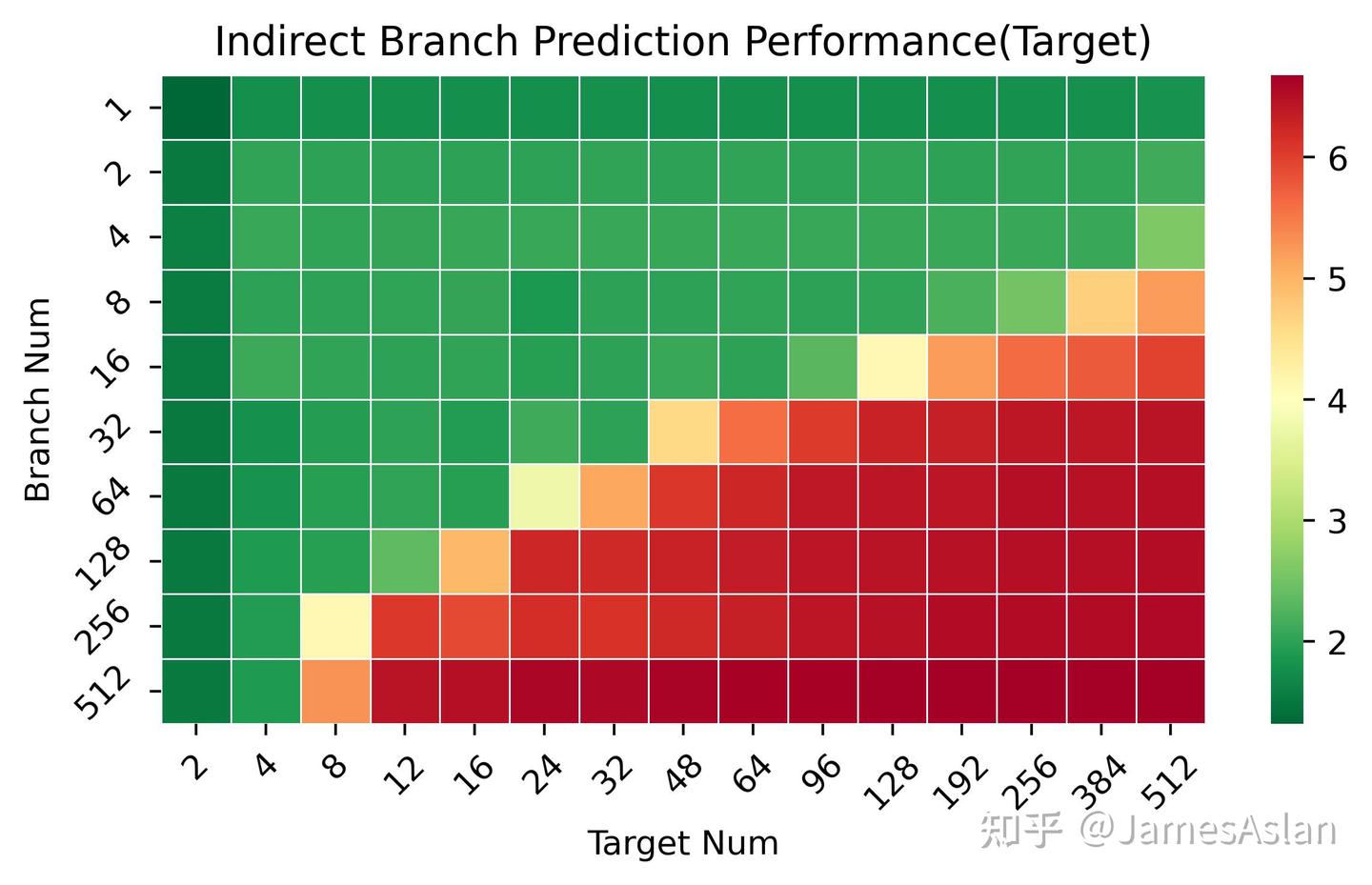
接下来,考察X925 IJP在不同可能跳转目标、不同间接跳转数量(需要预测)情况下的准确性表现。X925与X4表现完全一致。Cortex X系列在这里继续遥遥领先于Oryon。
后端
处理器的后端负责指令的执行,当代高性能处理器普遍配备了乱序超标量机制,后端的设计也是纷繁复杂。
流水线宽度
在超标量处理器中我们着重关注前端与mid-core部分的宽度。
| 流水级 | 宽度 |
|---|---|
| Fetch(ICache) | 16 |
| Fetch(mop Cache) | N/A |
| Decode | 10 |
| Rename | 10 |
执行单元
| 执行部件 | 数量 | 延迟 |
|---|---|---|
| ALU | 8 | 1 |
| BRU | 3 | |
| MUL | 4 | 2 |
| DIV | 1 | ~19 |
| AGU(ld+st) | 4 | |
| AGU(ld) | 4 | |
| AGU(st) | 2 | |
| FPU | 6 | |
| FADD | 6 | 2 |
| FMUL | 6 | 3 |
| FDIV | 1 | 5-6 |
| FMA | 6 | 4 |
X925的执行单元配置非常豪华,完全达到了10发射的级别。而且X925显然对dispatch等逻辑做了修改,不像X4尽管也是10发射处理器,实际使用中却有诸多限制。从X3开始的ALU持续吞吐低于峰值吞吐的抽象“feature”终于消失了,可喜可贺。另外值得一提的是,X925是第一款配备了6FPU的微架构;同时,X925是自Oryon和Zen5后,第三款能够支持每周期4load的微架构。
Mid Core
重命名消除
在实际应用程序中许多指令并不需要进入处理器后端被真正执行(如move指令);现代处理器普遍配备了各式各样的重命名消除机制,以减少处理器后端压力并加速程序执行。
| Elimination type | Throughput |
|---|---|
| move imm zero | 10 |
| move imm one | 9 |
| move chain | 1.1 |
| move single | 6 |
| move self | 1.09 |
| move bounce | 1.21 |
| sub self | 1 |
| xor self | 1 |
- move imm zero(mov x10, #0)吞吐为10说明重命名时对置0进行了消除。
- move imm one(mov x10, #1)吞吐为9说明重命名时对部分立即数情况进行消除,但是奇怪的是带宽比置0略有降低。
- sub与xor均未对置0情况进行特别优化,ARM ISA的编译器极少进行此类操作,X86处理器普遍配备此类优化。
- move single(非相关的move消除)等的吞吐为6,十分奇怪,不仅看起来没有具备基本的重命名消除机制,甚至还有额外的限制,导致执行的吞吐量比直接使用ALU执行还要低。
- move chain的吞吐量仅为1.1,说明其不支持串烧式的相关链的move消除。
X925的重命名消除机制表现十分奇怪。
乱序资源
乱序推测执行的处理器需要海量的队列空间来跟踪指令,确保最终的提交顺序正确。
| X925实测等效 | X4实测等效 | Oryon实测等效 | |
|---|---|---|---|
| ROB | ~472(944) | ~420(840) | ~672 |
| PRF(Fix) | ~272 | ~248 | ~396 |
| PRF(Float) | ~320 | ~152 | ~386 |
| PRF(Condition) | ~116 | ~92 | ~120 |
X925提供了大量的队列资源,但是仍然落后于Oryon、Apple M series等产品。ROB使用了一定的压缩技术(coalesced),在存储nop指令时容量近乎翻倍。不过在测试中并没有看出Arm PPT中所谓的window翻倍的效果。
乱序推测执行的处理器最为直接的调度窗口由各级发射队列的容量决定:
| X925 | X4(m) | Oryon实测等效 | |
|---|---|---|---|
| IssueQ(Simple fix) | ~96 | ~80 | ~132 |
| IssueQ(Complex fix) | ~96 | ~32 | ~48 |
| IssueQ(Float) | ~154 | ~80 | ~200 |
| IssueQ(Load) | ~60 | ~42 | ~70 |
| LDQ | ~120 | ~96 | ~232 |
| STQ | ~96 | ~72 | ~132 |
与豪华的执行单元数量相比,X925的发射队列规模就显得比较寒酸了,这部分由于X925使用了集中式发射队列的缘故。与从前的微架构相比,X925在浮点侧调度窗口的增大较为明显;X925作为首款配备了6FPU的微架构,发射队列规模相应扩大也是情理之中。Load侧由于第4个可以执行load的AGU加入,有较大的加强也在预料之中。另外,相较X4,在X925中诸如乘法这样的复杂整数指令现在也可以使用到整个整数发射队列的容量了。
访存
访存是体系结构永恒的话题与难题,访存性能直接决定了处理器性能的上限(甚至取指也是一种形式的访存),访存子系统的表现体现了设计团队的综合实力(前端、后端)。为了缓解越发明显的缓存墙(memory wall)问题,现代处理器的访存子系统十分复杂;流水线内的LDQ、STQ,Dcache、DTLB,下级Cache、下级TLB,各级预取器等组件交织配合,尝试在延迟、带宽等多个维度提高访存性能。
load-store前递
当load指令命中STQ中还未来得及写回DCache的store指令(访问了相同的物理地址)时,配备了load-store forwarding的处理器无需等待store指令写回DCache后再执行load指令,而是可以直接向load指令前递数据。



从橙色条带可见,X925配备了完善的load-store forwarding机制。当发生前递时耗时约5-6周期,不算是最快的梯队但也相当不错。数据partial overlay和完全overlay时前递速度不同,partial overlay时需要额外的周期;而Oryon与Apple M series等则没有这样的额外惩罚。相较X4,X925在forwarding方面改进巨大。在X4中只有load地址起始位置与store地址起始位置保持相对4字节对齐时,才能发生快速前递;X925则只要load地址被store完全包含就可以触发快速前递。
- load、store均不跨行时,每周期能够执行2组store-load指令对,符合只有2个AGU能够处理store的数量特征。
- load不跨行store跨越64Byte对齐边界时引入了额外的开销,此时每周期能够执行1组store-load指令对。相比Oryon 16Byte的边界检查要宽松很多,程序员友好型设计;不过不如Firestorm,由于地址interleave的设计,Firestorm连64Byte的检查也不存在。
- store不跨越64Byte对齐边界,load跨行时,带宽降低;此时每周期只能执行约1.5组store-load指令对,表现好于Oryon,弱于Firestorm。
DCache
在进一步的测试中,我们发现X925的DCache有很高的吞吐率:
- 在短的行内bank跨步(0、4、8、16)上,X925能够一直保持4load吞吐,表现非常好。
- 在稍大的bank跨步(64)上,X925出现了小幅的load吞吐下降,下降到了3.12。
- 在更大的bank跨步(128、256)上,X925出现了更大幅度的load吞吐下降,下降到了2.67。
我们由此可知X925没有采用三或四体复制的设计的迹象(这样的设计过于暴力 ,概率很小);X925同样也没有Oryon和Apple那样的按照地址interleave分block的设计,因为没有严重的直接地址冲突迹象;再结合其较高的吞吐率,可以推测其采用了路预测,具体的算法有待今后通过hash冲突的方式精细探究。
访存延迟
我们使用多种访存模式访问逐渐变大的数据(直至内存),以探究X925的Cache层级设计、预取器效果、内存控制器效果。(原谅它频率不稳,所以图很难看)
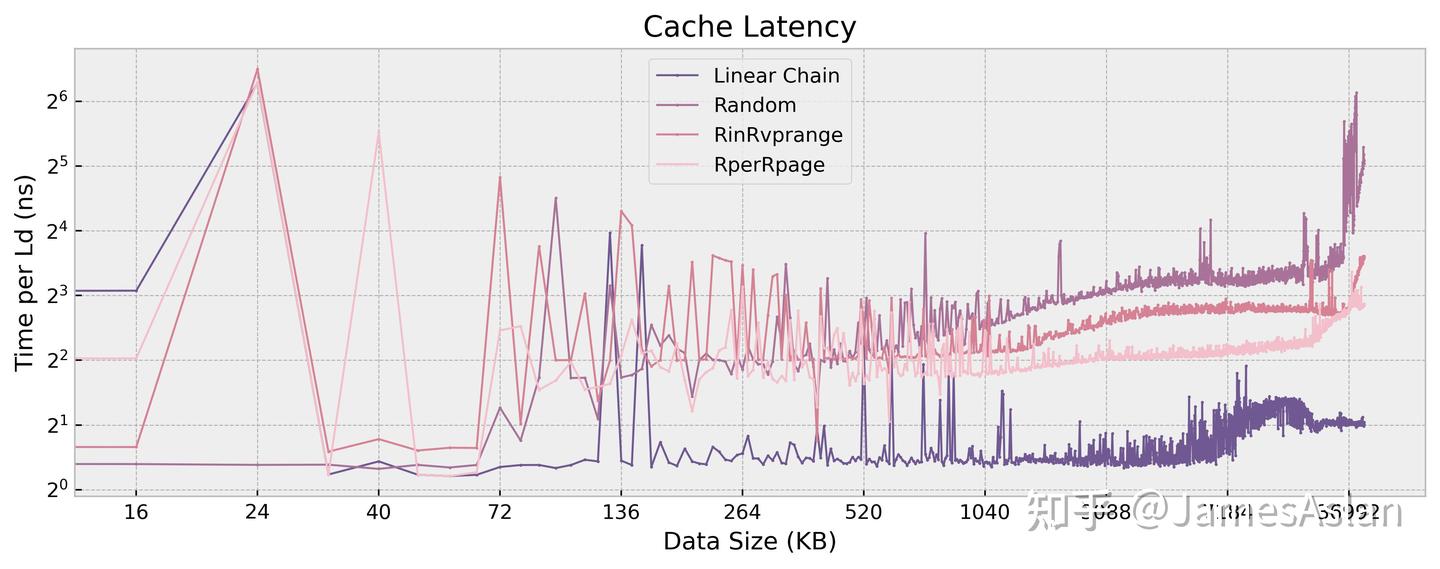
- DCache的有效容量为64KB,访问延迟为4 cycle。有基本的stream、stride预取器。
- L2与L3(LLC)容量不明显,因此配备CMC/temporal/history类预取器,die shot可见容量。
访存序
乱序推测执行的处理器中,store指令无法被推测执行但是load指令允许被推测执行,这就造成了访存的RAW和WAR问题。为了避免错误推测执行的load指令带来频繁的回滚或流水线清空,处理器内部普遍配备了访存违例预测器,预测可能会导致回滚和流水线清空的load指令,并强制这样的load指令不再完全推测执行。
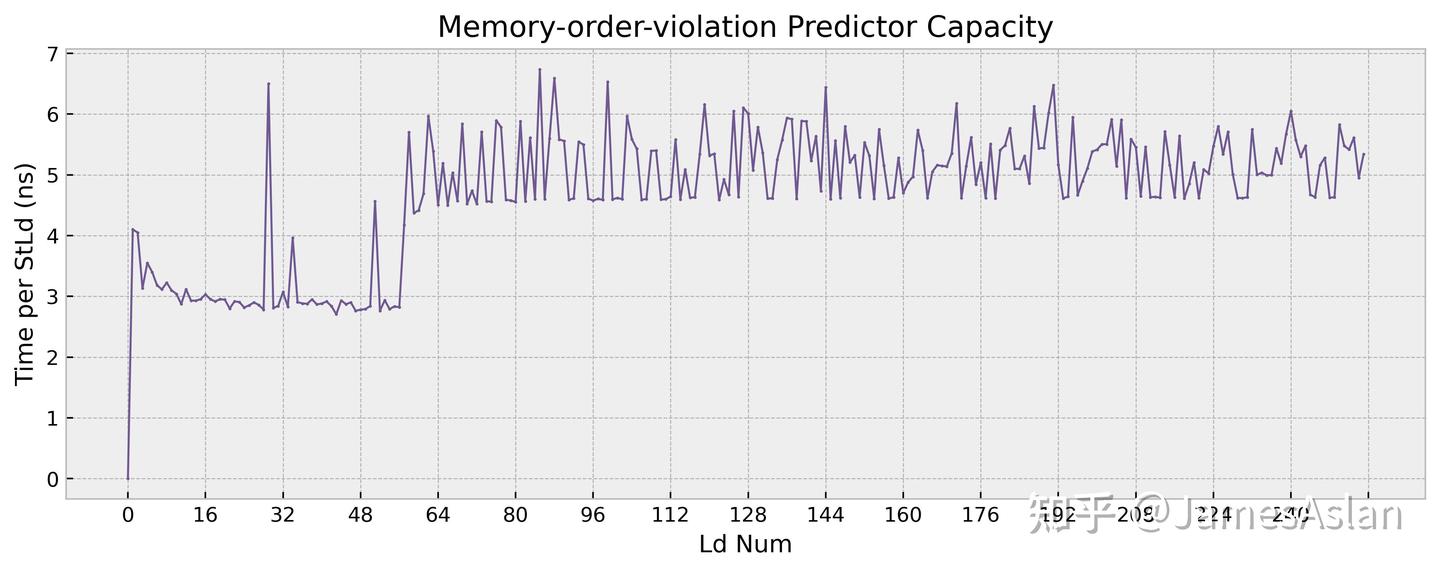
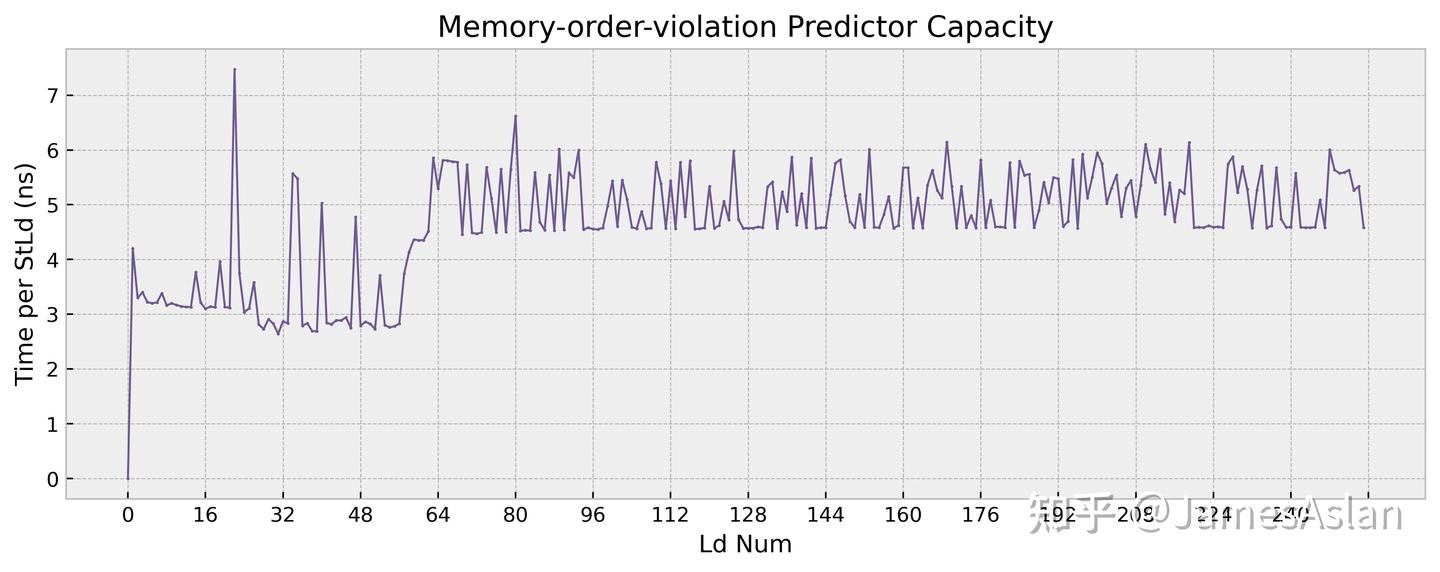
anti-bias的最佳表现在~56对,行为模式与X4基本完全一致,看起来没有大幅更改。
访存并行度
在该测试项目中,我们考察处理器同时面对多个访存流时的表现。每个访存流均是随机且独立的,因此可以规避大部分预取器的影响,最大限度压榨核内流水线乱序结构、各级Cache乱序结构。
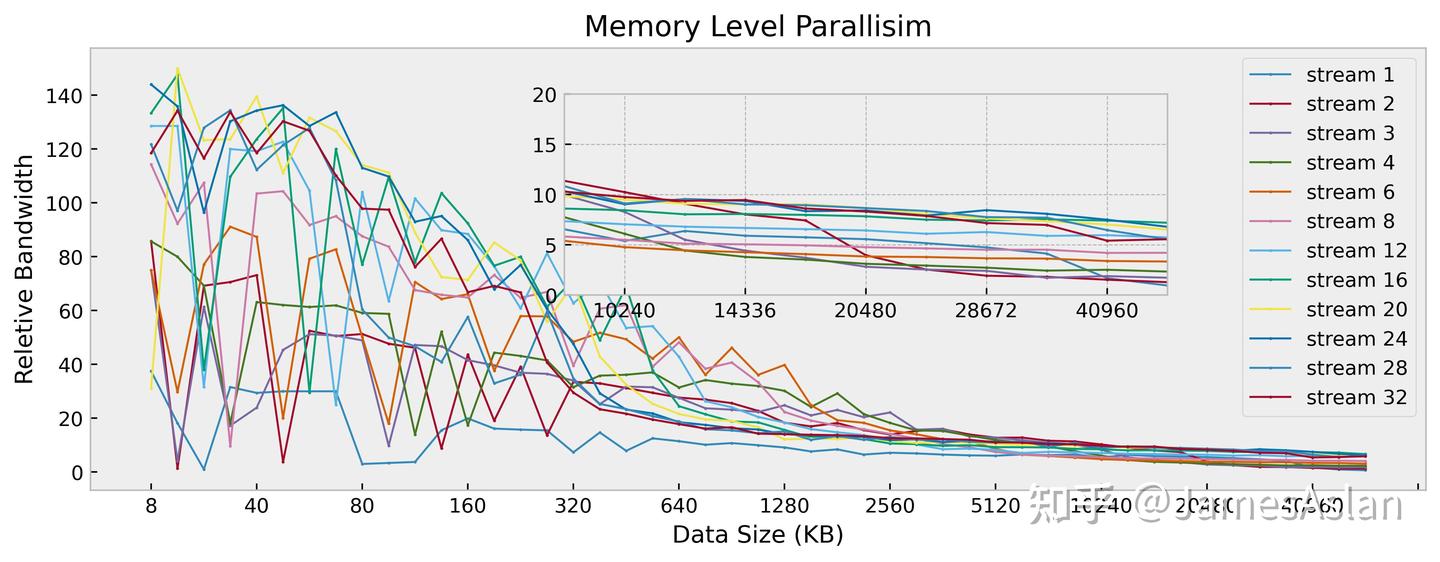
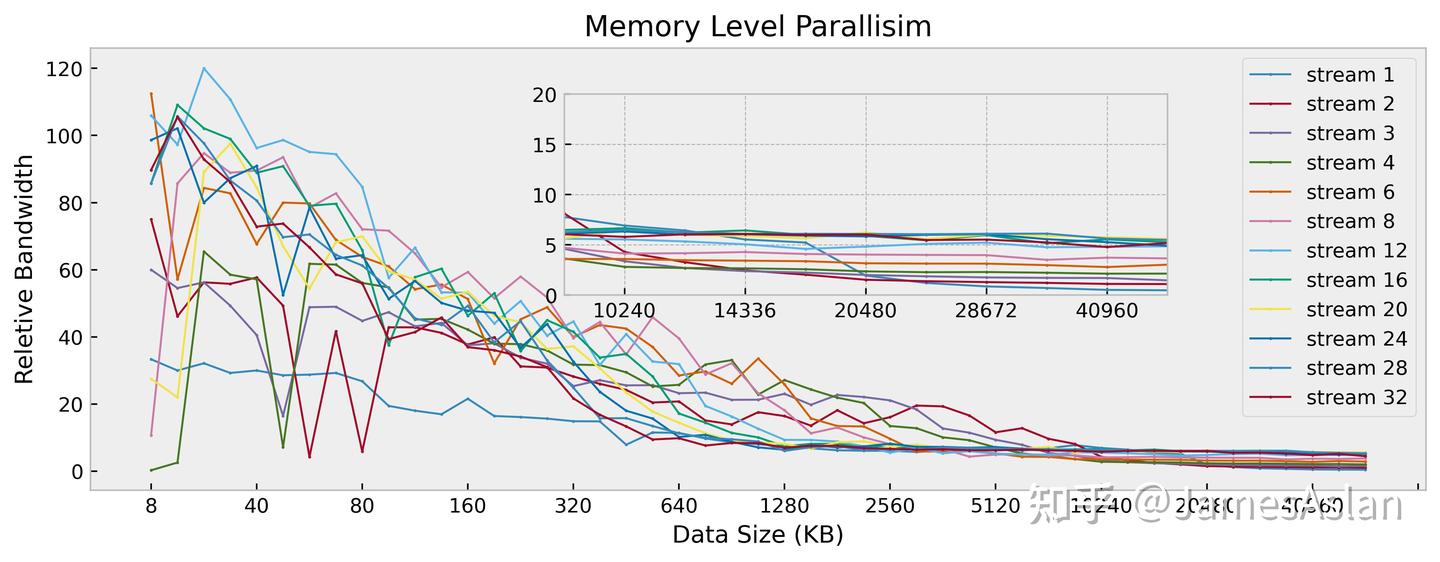
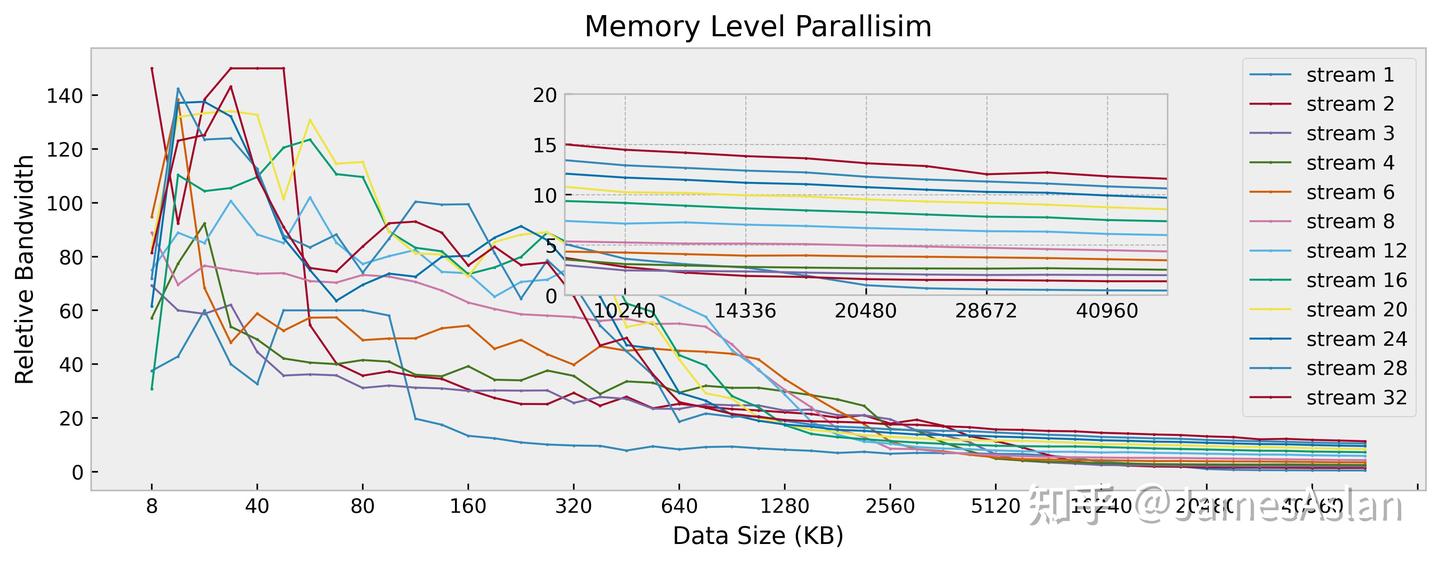
与前代X4相比时,X925在近核端的多流倍率收益显然更高,可能与AGU的load吞吐量由3/cycle增长到4/cycle有关。而下级内存端,X925最大的有收益流数量仍然远小于32流,表现较差;作为对比,Firestorm、Oryon等能均达到接近32流。
Pointer Chasing
Pointer chasing是现代高性能处理器中常见的访存优化,当一条load指令的结果用于下一条load指令的地址计算时,该结果会从快速通路进入AGU流水线,缩短这两条load指令的执行间隔。在配备了pointer chasing消除的处理器中,触发pointer chasing后load-to-use延迟会比正常情况减少1周期。
| Load-to-use latency | |
|---|---|
| Pointer-chasing Case | 4 |
| No-pointer-chasing Case | 4 |
X925没有配置pointer chasing优化,似乎是Arm的惯例了?
核外
随着摩尔定律的放缓,即便是消费级处理器也被迫向多核方向发展,核外组件发挥着越发重要的作用。核外系统是个纷繁复杂的世界,无论是总线结构、一致性协议、LLC设计还是内存控制器调度,每项都复杂到不是读完1本书就能入门。因此,我们只关注其中较为浅显、直观的部分。
访存带宽
我们通过Stream程序测试Soc中CPU单核的访存带宽,其反映了处理器核内的流水线设计、各级设计、总线设计、内存控制器设计等多个维度特性的交叠。
| Function | Best Rate (MB/s) for Cortex X925(D9400) | Best Rate (MB/s) for Cortex X4 (D9400) | Best Rate (MB/s) for Oryon(X Elite) | Best Rate (MB/s) for Cortex X3 (8Gen2) |
|---|---|---|---|---|
| Copy | 40705 | 40721 | 55817 | 39011 |
| Scale | 40782 | 40827 | 54521 | 35203 |
| Add | 35974 | 36293 | 59052 | 40518 |
| Triad | 35843 | 35733 | 58626 | 38500 |
旗舰级手机的单核访存带宽似乎来到了一个瓶颈,与PC端相比带宽的差距还是存在的;实际上64bit(16*4)的LPDDR也有些限制了Dimensity9400发挥其全部实力。前些年旗舰级手机的内存子系统进步神速,似乎缩小了与PC端的差距;但是近两年PC端也开始了新一轮的军备竞赛,差距似乎又被拉回了。同微架构在PC上表现相对手机优秀10%的现象可能仍将陪伴我们很久。
核间延迟
我们通过CAS测量Soc中两两核间的延迟(脏数据传递),其反映了处理器的一致性协议效率、LLC设计、总线设计等多个维度特性的交叠。
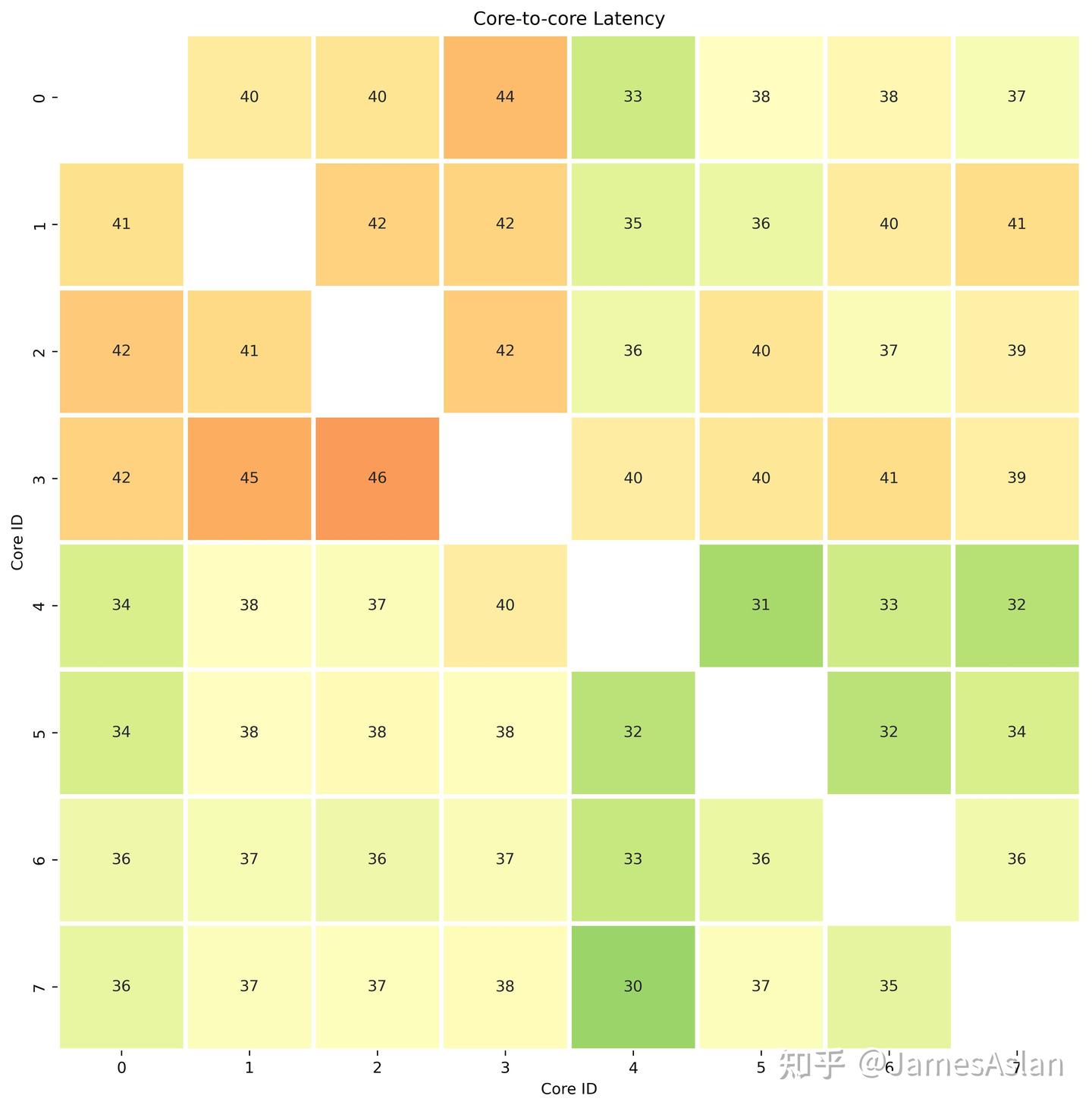
我们可以看到明显的簇状结构,显得Cortex X925与X4被放置在了一个簇中(核4-7);Cortex A720们被放置在了一个簇中(核0-3)。然而这大部分是由于核心频率的差异导致的通信延迟差异,剔除频率差异后这8个核心的通信延迟应该是较为均匀的。
总结
随着Cortex X4、Apple M4、Cortex X925的登场,我们可以直观感受到:微架构流水线宽度增长带来的感知越来越小,内部乱序队列规模的增长在传统benchmark中带来的性能提升也边际效应显著。prediction wall和memory wall这两堵高墙拦住了通往更高ILP的道路,12发射、14发射的微架构还有意义吗?CPU的未来到底路在何方?回到Cortex X925,手机严苛的散热、功耗限制以及内存规格配置等制约了其展现全部实力,不过幸好适逢新一轮WoA浪潮,在不久的将来搭载X925的PC-level SoC就要出现,让我们静待来日。
分析与测试:lyz、lxy
测试平台
十分感谢 @秋元明 提供的设备支持,抱抱\( ̄︶ ̄*\))。尽管X200的调度器给peak性能测试和微结构测试带来了困难,但是如果作为设备使用者我还是乐于见到这种调教的,毕竟对于手机这样的移动设备,续航在我心目中>>>>>>极限性能。