

上一期笔记,忘记的小伙伴可以复习一下:
王源:【强化学习与最优控制】笔记(四)强化学习与最优控制的关联与对比本笔记对应教材中2.1-2.2节的内容,由于原书中2.1-2.2的内容稍显混乱,我的笔记对这两小节的内容进行了重新梳理,顺序可能会和原书有点变化。需要教材电子版的同学可以从如下链接中获取电子版的草稿:
Dimitri P. Bertsekas 强化学习2021版教材和视频课程推荐因为电子版是一个草稿版本内容不是很全,推荐可以购买纸质版请点击:
前四期的回顾,没有看或者有点忘记的童鞋可以复习一下:
王源:【强化学习与最优控制】笔记(三)动态规划求解实际问题举例
王源:【强化学习与最优控制】笔记(四)强化学习与最优控制的关联与对比
1 强化学习中近似方法概述
在强化学习中核心的思想是怎么去近似求解图1.1中的优化问题。那为什么我们要想尽各种方法去近似呢?
从前几期的笔记中我们知道要想用动态规划的递推公式完全精确的求解下图中的优化问题依然面临维数灾难的问题。简单来说就是针对小规模问题我们可以用动态规划来解,而问题规模稍大之后动态规划的计算量/占用内存量就非常非常庞大,以至于我们现有的计算力和存储设备是无法接受的。所以我们通过对问题的近似可以达到降低计算量的目的,这也是强化学习,包括近似动态规划的一个基本出发点。
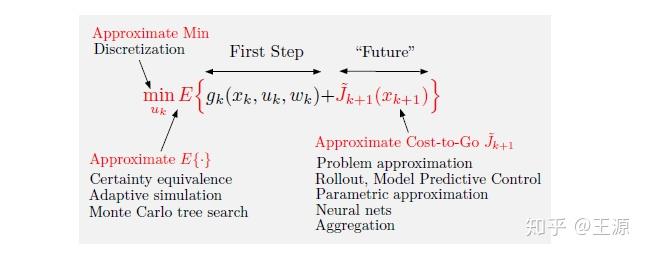
上图中红字标出了三种近似的思想:
1是Approximate Min:简单来说就是 我们在求解极小化问题的时候可以不用那么较真,能求到一个差不多的近似最优解就可以了。
2是Approximate 期望:这个也比较好理解了,很多时候我们并不知道随机变量的分布,也就很难计算出期望的close form,那我们只好采用估计的方法来近似期望,例如采用样本均值来估计期望就是一种方式 。
3是 Approximate cost-to-go function :动态规划的关键就在这个
上了,要想精确得到这个
需要再求解一个子优化问题,然后像剥洋葱一样层层递推到最后才能把
算出来,那么我可以通过近似未来的cost的方式来降低计算量,我只计算一个近似的cost-to-go function
。那么我们这一过程称为Approximation in value space (值空间近似),下面再详细展开Approximation in value space有哪些方法?
1.1 Approximation in Value Space (值空间近似)
(a)Problem approximation (优化问题近似)
计算 可以通过求解一个简化后的优化问题来得到,简单来说你可以把原始优化问题中一些约束松弛掉(例如采用拉格朗日松弛或者罚函数的方法去掉约束),还可以把随机优化问题简化为确定性优化问题,还可以通过问题分解的方法将优化问题拆分为若干小的子问题来求解 等等。
(b) On-line approximate optimization
采用一些简单的启发式算法或者比较简单的Policy计算出 ,比较有代表性的就是Rollout algorithms 和 Model predictive control。
Rollout algorithms的基本思想是采用一个粗略的Policy来估计出 ,Model predictive control就直接认为
。这里我用了
,其中
,这个实际上是 Multistep Lookahead,后面我会讲到。
(c) Parametric cost approximation
Parametric cost approximation的想法也非常直观,那就是我认为 是一个函数族,其参数是
,表示为
。如果我选
是一个线性函数的话,那就是一个线性回归的问题,
就是线性回归的系数。我也可以用一个神经网络来近似
,那
就表示一个神经网络,其中
就是神经网络的权值。
看到这里熟悉神经网络或者机器学习的童鞋已经看出来了,Parametric cost approximation无非就是用经典的机器学习模型去近似 ,线性回归也好,多项式函数也好,神经网络也好,支持向量机也好,还是深度神经网络也好,都可以用来近似
,不同模型近似效果有差异,但是基本原理是相同的。如果
是一个深度神经网络的话,那就是目前非常火的深度强化学习了。
(d) Aggregation
Aggregation其实可以看做是Problem approximation 的一种,但Aggregation稍微特殊了点,我们需要把它单独拎出来讲一下。Aggregation的基本思想是通过合并state,进而达到降低状态变量维度的目的,进而降低计算量。
这么讲还是有点抽象,我这边举一个直观点的例子帮助理解:例如我是滴滴公司,我要负责给北京市的每辆车派发订单。现在设想一下,我掌握着整个北京市所有出租车和快车的实时的位置信息,这个就是我的状态变量了,可以想象一下这个状态变量维数是非常大的,至少上百万的规模是没问题吧。那对车辆派单的问题我怎么能够做到压缩state的维数呢?也就是所谓的Aggregation呢?我可以把方圆一平方公里内的所有车视为一个状态变量,我只需掌握在方圆一平方公里内的车辆总数即可,无需知道每个车精确的位置信息。之所有能这么压缩的原因在于对于派单问题而言,方圆一平方公里的车彼此之间距离比较近,把同一个订单排给同一个区域内任意1辆车的cost差别不会大。
上面(a)-(d)的内容在这里只是做一个简单的介绍,其详细内容会在后续章节中一一展开去讲,这里只需要建立一个基本的概念就行。
1.2 Multistep Lookahead and Rolling Horizon (多步超前和滚动优化)
在图1.1中的我们只做了One step ahead,那么更加一般的情况是Multistep Lookahead,其公式如下图所示:
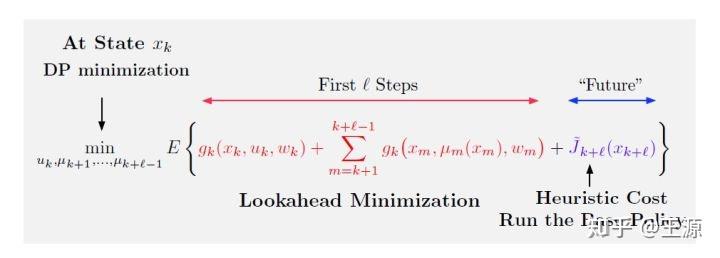
主要和图1.1的One step ahead的区别在于,我们加了一项 ,这样的话就可以让原来的
往后推
步变为
。从这里就不难看出Multistep Lookahead 的目的是什么了,其目的就是说在第k步做决策的时候,如果
这个估计值不准确的话可能对我第k步的影响就比较大,因为
从时间上来说和第k步是紧挨着的,那现在有了Multistep Lookahead ,我们采用的是
,无形当中就推后了
步,那
即使估计不是那么准确也对我当前第k步的决策影响没有那么大了。
那么 这个参数的设定就是一个比较关键的问题了,在实际问题中这也是一个比较玄学的问题,也没有太好的方法去确定出
,只能是根据实验和经验去给出一个看起来还不错的
的值。
的太小显然达不到我们刚才说的Multistep Lookahead 的目的,同时
的值也并非越大就一定越好,Bertsekas在Example2.2.1(纸质书66页)上给出了一个例子就是
取的大了反倒优化的效果没有小的时候好的例子,感兴趣同学可以看一下也是比较简单的内容,我们就不再赘述了。
最后还要说一下 Rolling Horizon,中文叫做滚动时域,为什么这么叫呢?是因为在当前时刻k,我会求解一次优化问题得出未来 个时刻的控制决策,而我真正给系统用的控制决策仅仅是当前时刻的控制决策也就是
,当
作用去动态系统上之后,系统从时刻k到k+1,然后在k+1时刻我再求解一次新的优化问题得出未来
个时刻的控制决策(此时的起点是k+1而不是k了,所以看起来像是滚动着前进了一格的感觉)
1.3 Approximation in Policy Space(策略空间近似)
前面讲了Parametric cost approximation,那同样的对于 我们可以用
来进行近似。
可以是一个线性函数,也可以是一个多项式函数,也可以是一个神经网络,其中
是模型的参数。
通过如下的最小二乘/回归问题 即可求得参数
(1.1)
其中 指的是在状态
之下一个相对不错的控制量,这样我通过上面的最小二乘/回归问题来近似这个不错的
也应该能得到一个不错的效果。上面的最小二乘/回归问题就是一个机器学习中的监督学习的问题。
那么 的获得是一个比较关键的问题,因为我们最终的Policy是通过学习
得到的,
本身就很差那我再学习一个很差的Policy就失去了意义了。
的获得一种是通过一些经验的方式获得,还有一种方式是通过value space来获得,如下所示:
(1.2)
从上式中可以看出只要我有了 value space approximation ,那我总可以通过上面极小化的方式来获得一个
。这一点非常的关键它讲value space approximation 和 Policy Space approximation 有机的联系了起来。当然在很多场合之下有的人喜欢用Q function来表达式(1.2),那意思完全都是一个意思,只是符号不同罢了,大家在看文献的时候稍加注意即可。
那最后还要回答一个问题就是我既然能计算出 来,我干嘛还要搞一个近似的替身
出来,这不是脱了裤子放屁吗?
的主要意义是在online的场景下,可以很快计算出控制量。
仅仅是一个神经网络输入得到输出的过程。而
是需要求解一个式(1.2)那样的优化问题才能得到的。哪个计算量大一目了然啊。
下一期笔记:
王源:【强化学习与最优控制】笔记(六) 强化学习中的Decomposition