

如需教材电子版的同学可以从如下链接中获取:
Dimitri P. Bertsekas 强化学习2021版教材和视频课程推荐上一期笔记,忘记的小伙伴可以复习一下:
王源:【强化学习与最优控制】笔记(六) 强化学习中的Decomposition1 Rollout
Rollout 算法的基本思想就是 在未来有限的k步之内采用直接优化的方法(lookahead minimization),而在k步之外采用 base policy 对 Value function 来进行近似。其基本思想如下图所示:
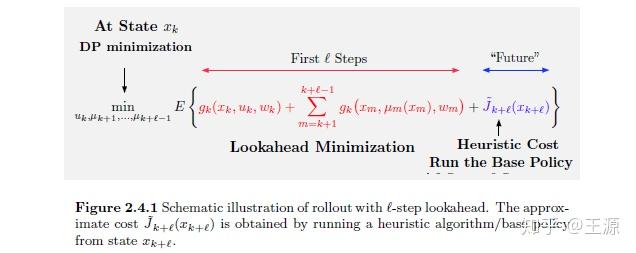
Rollout 的精妙之处在哪里呢?
个人认为主要有2个方面:1 Rollout 算法的框架 可以将传统数学优化/启发式算法 与 动态规划/强化学习相结合。整体上 Rollout 算法就是一个动态规划的架构,但是里边的 base policy 可以采用我们数学优化里边 常用的一些方法来得到,例如贪心算法,例如线性规划,例如次模优化等等,如果是面对整数规划的问题 还可以用到 Relaxation 和 decomposition 的方法。2 Rollout 算法具有 Policy improvement 的性质,简单来说就是采用了 Rollout 算法就会比以往单纯使用 base policy 要好。那么接下来我们详细来介绍 Policy improvement 的推导证明思路。
2 Policy Improvement
想要严谨的证明 Policy improvement 我们需要 base policy 满足两个条件(至少满足其一即可),即 sequential consistency 和 sequential improvement
2.1 sequential consistency
sequential consistency 定义: 若 base policy 在 处开始生成的序列为
则 base policy 在
处开始生成的序列必为
,则称 base policy 满足 sequential consistency 的性质。
怎么理解这个定义呢?简单来说 就是 base policy 只与当前状态有关的话 就一定满足 sequential consistency。例如在TSP问题中的贪婪算法就满足 base policy 的性质,因为每次 base policy 的决策就是和当前所在节点位置最近的节点作为下一个节点,很明显贪婪算法的决策只和当前节点(状态)有关。举个反例就是 如果每次都选取和已经经过的所有节点距离之和最近的节点的话 则就不满足 sequential consistency 的性质,因为在每步决策的时候 都需要考虑历史上所有经过的节点(即所有的历史状态)。
接下来开始论证我们的 Policy improvement 的性质:若 rollout 算法中 base policy 满足 sequential consistency 的性质,则采用 rollout 算法得到的解不会差于 单纯使用 base policy 得到的解。
设 rollout policy 为 ,
表示从状态
采用 rollout policy
的 cost function,
表示从状态
采用 base policy 的 cost function,
表示 base policy
我们要证明的是:
证明思路采用的是数学归纳法的思路,先假设对于 是成立的,然后推导出对于
也是成立,同时易知
我们有: (1)
(2)
(3)
(4)
(5)
从(1)到(2)是因为我们已经假设了对于 是成立的。
从(2)到(3)是 rollout 算法的定义
从(3)到(4)是因为式(3)是最优的值,而式(4)是 base policy 得到的值,所以 base policy 得到的值只能是大于等于最优的值。
从(4)到(5)就是 base policy 满足 sequential consistency 的性质。
2.2 sequential improvement
其实理解了 sequential consistency 的证明过程,sequential improvement 就很好理解了。sequential improvement 可以理解为从证明过程 式(3)到 式(5)反推得到的。
我们把 式(3)到 式(5)单独拎出来可得:
根据 Q funcition 的定义上式又可以写为:
容易理解 sequential improvement 比 sequential consistency 的条件要弱一些,从上面的论证就可以知道 sequential consistency 可以推出 sequential improvement,反之则不一定成立。所以大家只需要理解 sequential improvement 和 sequential consistency 相比 其实只是放宽了对 base policy 的条件而已。
总结:
Rollout 算法的理论保证 就在于确实可以起到提升优化得到的解的质量,这就是 Policy improvement 的核心思想。以上的内容主要都是针对 确定性问题而言的,对于带有随机性的问题 也有相似的结论 见教材 95页,我们这里就不再赘述了。
下一期笔记:
王源:【强化学习与最优控制】笔记(八) 模型预测控制(Model Predictive Control)