

上一期笔记,忘记的小伙伴可以复习一下:
王源:【强化学习与最优控制】笔记(七) Rollout 与 Policy Improvement如需教材电子版的同学可以从如下链接获取,电子版是一个草稿版本内容不是很全:
Dimitri P. Bertsekas 强化学习2021版教材和视频课程推荐本笔记对应教材中2.5节的内容。如需购买教材的童鞋请点击:
1 模型预测控制的动机(Model Predictive Control)
一句话来概括 Model Predictive Control 就是 Rollout 算法的一种特殊情况,它也是 最优控制 (Optimal Control)的一种扩展。那么也就可以说 Model Predictive Control 实际上也是 强化学习的一个特殊情况。其实关于 Model Predictive Control 我之前做过一些介绍的文章,不熟悉的童鞋可以先看这篇:
王源:模型预测控制简介(model predictive control)那我们来看 Bertsekas 是怎么通过 Rollout 来引出 Model Predictive Control 的。回顾一下我们在 Rollout 算法里所面临的基本问题:
(1)
是 在 stage k 的 cost,
是用 base policy 来近似 Value function
我们做一个非常美好的假设:如果 和
有 close-form ,并且它们的 close-form 还是一个关于
可导的函数。
则我们可以直接写出式(1)所构成的优化问题的 close-form。在大多数情况下,式(1)所构成的优化问题可被转化为一个非线性规划问题。采用一些基于梯度的算法(例如 梯度法 共轭梯度法 牛顿法)等方法可以直接求解式(1)所构成优化问题即可。
其实上面这个假设是非常理想的,在实际问题中几乎很难找到 close-form,尤其是 的 close-form 几乎是不可能得到的。我这里说“几乎”,其实就是说还有一小撮问题是能得到 close-form。这一小撮问题其实就对应的是传统控制领域里 Optimal Control 的问题。正是因为 Optimal Control 在实际应用问题中假设过于强了,导致大多数问题都无法适用。自然人们就要问了如果说我得不到 close-form 应该怎么办?
那么经常被人们采用的一种方法是 使用多步预测的优化问题作为 base policy。具体操作如下所示:
我们给出 Model Predictive Control 优化问题的目标函数:
(2)
将这个目标函数,拆分为2项可得:
(3)
结合式(1)和 式(3)中可以看出,Model Predictive Control 实际上是用 当做 base policy 的目标函数。这其实就对应了我们上面所说“采用多步预测的优化问题作为 base policy“。一般来说 base policy 可能是一个启发式算法,或者一个贪婪算法什么的。Model Predictive Control 的妙处在于 我是用优化来做 base policy。
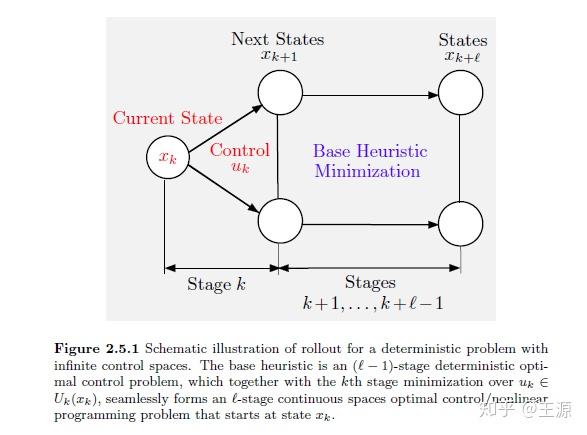
如上图所示我们是通过求解 stage 的 优化问题得到 base policy,所以也称之为 Base Heuristic Minimization。
2 Model Predictive Control 算法
目标函数:
(3)
系统方程:
(4)
约束条件:
(5)
(6)
是在stage k 得到的最优解序列,但在stage k 我们只拿第一个
真正做作用到动态系统。
Model Predictive Control 在 stage k 当前状态为
step 1: 求解(3)-(6)所构成的优化问题。
step 2: 令 step 1中得到的最优解,将
作用到动态系统,将
的解丢掉。
step 3: 然后进入到下一个stage,将 当做
重复 step 1和step 2。
至此 Model Predictive Control 的算法就已经给出了,那么紧接着有三个理论方面的问题需要回答:
(1) Model Predictive Control 是否是 Constrained Controllability Condition?Constrained Controllability Condition 定义如下:

简单点说就是 (3)-(6)构成的优化问题有没有可行解?直观上来看如果控制变量约束集合 的范围非常小,那么很可能无法让整个系统得到一个满足所有约束的可行解。没有可行解的话我们来解 Model Predictive Control 的问题根本连解都没有的话就没有任何意义了。
(2) Model Predictive Control 得到的解 是否是 Stability ?如果有可行解,但是这个可行解会让目标函数趋于无穷大那么这样的解其实对于实际系统来说没有什么意义。即我们要保证系统的稳定性
(3) Model Predictive Control 得到的解是不是优的?我们在 Model Predictive Control 算法的 step2 中只采用当前的 ,将
剩余的解丢掉。这么一种做法是否能保证比不丢掉这些解来得好呢?要回答这个问题其实就对应我们上一节笔记里讲过的 Sequential Improvement,具体过程我们会在下面详细展开论述。
总结一下 Model Predictive Control 所面临的三个核心理论问题是依次递进的关系,从有没有可行解,到可行解是否Stability ,再到解是否是更优的。只要梳理清楚这三个问题那我们就已经初步把 Model Predictive Control 的理论基础梳理清楚了。
3 Model Predictive Control 三个核心理论问题
3.1 Sequential Improvement
式(3)中我们说了 Model Predictive Control 实际上是通过求解 stage 的 优化问题得到 base policy 的。那么我们需要证明的是 这个base policy是满足 Sequential Improvement 性质即可。
给出 Model Predictive Control 的迭代公式:
(7)
是通过求解
stage 的 优化问题得到 base policy 的 value function,从 state
到
,
是通过求解
stage 的 优化问题得到 base policy 的 value function,从 state
到
由此可知 和
都是经过了
stage,让最终的末状态等于0,但对于
来讲就多了一个stage,是经过了
stage,让最终的末状态等于0。经过越多的 stage 最终达到相同的末状态 所花费的cost就越小,由此可得:
(8)
结合式(7)和(8)可得:
(9)
上式就是 Sequential Improvement 的定义了。由此可知 Model Predictive Control 的算法是具备 Sequential Improvement 性质的,因此在每一步重新优化是对最优解有改进的。
3.2 Stability
见教材 page 113 页,证明过程比较简单,我就不抄写过来了。需要注意的一点是证明 Stability 隐含的假设前提是 已经满足 Sequential Improvement 和 Constrained Controllability Condition的条件了。
3.3 Constrained Controllability Condition
对应原书中 page 115 的 example 2.5.2
考虑如下单变量线性系统:
(10)
控制变量约束:
若令 ,由此可知
(11)
整理上式可得:
(12)
从上式看出 是一个等比数列,比值为2。我们可以得出等比数列的通项公式为:
(13)
若 ,则该数列为单调递减数列,结合上式则有
必然有
。必然存在一个
使得
(14)
那么一旦满足上式 就令 就可以让
原书中关于这块的证明感觉有点跳步,我重新整理了一下证明思路,后半截证明我也不再赘述了和前半部分类似。
从这个例子看出一个问题就是控制变量约束的范围很大程度上会影响是否能让最终状态到0,同时状态变量初始值的范围也会影响世人能让最终状态到0。控制变量约束越宽松代表着控制能力越强 越容易达到0,初始状态越接近0代表越容易达到0,也就越容易满足 Constrained Controllability Condition。
下一期笔记:
王源:【强化学习与最优控制】笔记(九)值函数,Q函数和策略空间的近似