

上一期笔记,忘记的童鞋可以复习一下:
王源:【强化学习与最优控制】笔记(十二)无限时间值函数近似如需电子版教材可以从如下链接中获取:
Dimitri P. Bertsekas 强化学习2021版教材和视频课程推荐本笔记对应教材中第5章5.3的内容。由于电子版教材的内容不全,所以推荐大家购买纸质版,需购买教材的童鞋请点击
Actor-Critic 是强化学习中一个重要的算法。在教材5.3小节对 Actor-Critic 进行了一个基本介绍。
Actor(演员):可以理解为就是一个函数映射,输入state,输出action。自然也可以用神经网络来近似这个函数。这样actor的主要目的就是让整体的目标函数变小。
Critic(评委):为了训练actor,我们就需要知道actor的表现到底怎么样,根据表现来对actor进行调整。简单点说就是 (Approximate)Policy Evaluation。同样的 critic 也可以通过神经网络来近似。
1 Model-Based Variant of a Critic-Only Method
首先我这里先解释一下什么是Model-based和Model-free,这两个名词在强化学习中经常出现。事实上强化学习的算法目前就分为二大类,一个就是Model-based,另外一个就是 Model-free,这两类方法各有优缺点这里我们暂且不表,主要来说一下这两类方法的定义。这里的Model值得主要是两个:一个是系统的动态方程 也就是转移概率矩阵 ,一个就是reward function里的stage cost
。Model-based 的意思是我必须知道 系统动态
和 stage cost
的表达式才行。即使对于一些问题没法直接知道
和
我也要通过辨识的方法或者learning的方法去近似得到一个
和
,然后基于这个model再来做强化学习算法。Model-free就与之相对了,无需采用
和
的表达式即可。
如下图所示是 Model-Based Variant of a Critic-Only Method 的基本流程:
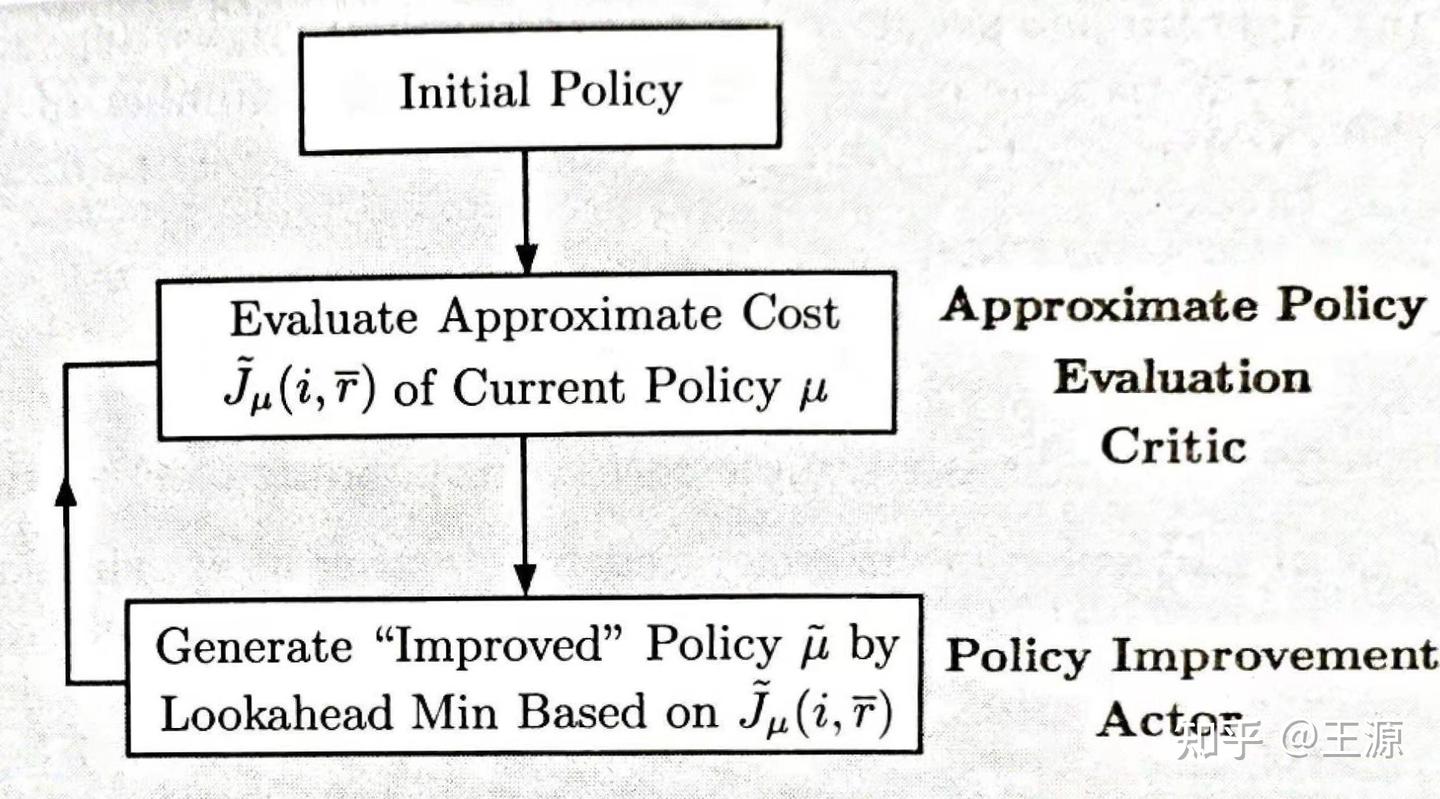
设 是对
的参数化的近似,
为训练集。
Critic step:实际上就是 Approximate Policy Evaluation,通过对 cost function 进行采样来近似的评价当前 Policy 的好坏。通过如下的回归问题来更新参数
(1.1)
可以是一个线性函数,也可以是一个神经网络或者任意一个机器学习的模型。若
是一个线性函数的话,那么上式中的优化问题实际上是一个线性最小二乘的问题。这个优化问题是可以得到解析解的。若
是一个非线性函数或者神经网络之类的比较复杂的形式,则上式中的优化问题一般来说会是一个非线性规划问题。那么这样的非线性规划问题想要精确求出最优解是比较困难的。
因此在很多时候我们并不一定需要完全精确的求解式(1.1)的优化问题。那我们也可以考虑采用Incremental method 来更新参数 :
(1.2)
其中 是更新步长。
Actor step:实际上就是基于 Lookahead minimizing 来更新得到下一步的 Policy,如下所示:
(1.3)
或者可以采样一部分状态来更新下一步的Policy,如下所示:
(1.4)
其中
从式(1.3)和(1.4)不难看出我们这里的方法确实是Model-based的方法,因此在更新Policy的时候我们需要知道 才能进行Policy的迭代更新。
需要注意的是教材5.3节目前只涉及 Value function的参数化近似,而在 Policy 这边先不考虑参数化近似的情况。本节我们是通过式(1.3)或者(1.4)来直接得到 Policy 。所以本节的内容可能和常见的强化学习的Actor-Critic有点区别。关于参数化 Policy的内容讲在教材5.7小节中补充介绍。
2 Model-Free Variant of a Critic-Only Method
如下图所示是 Model-Free Variant of a Critic-Only Method 的基本流程:
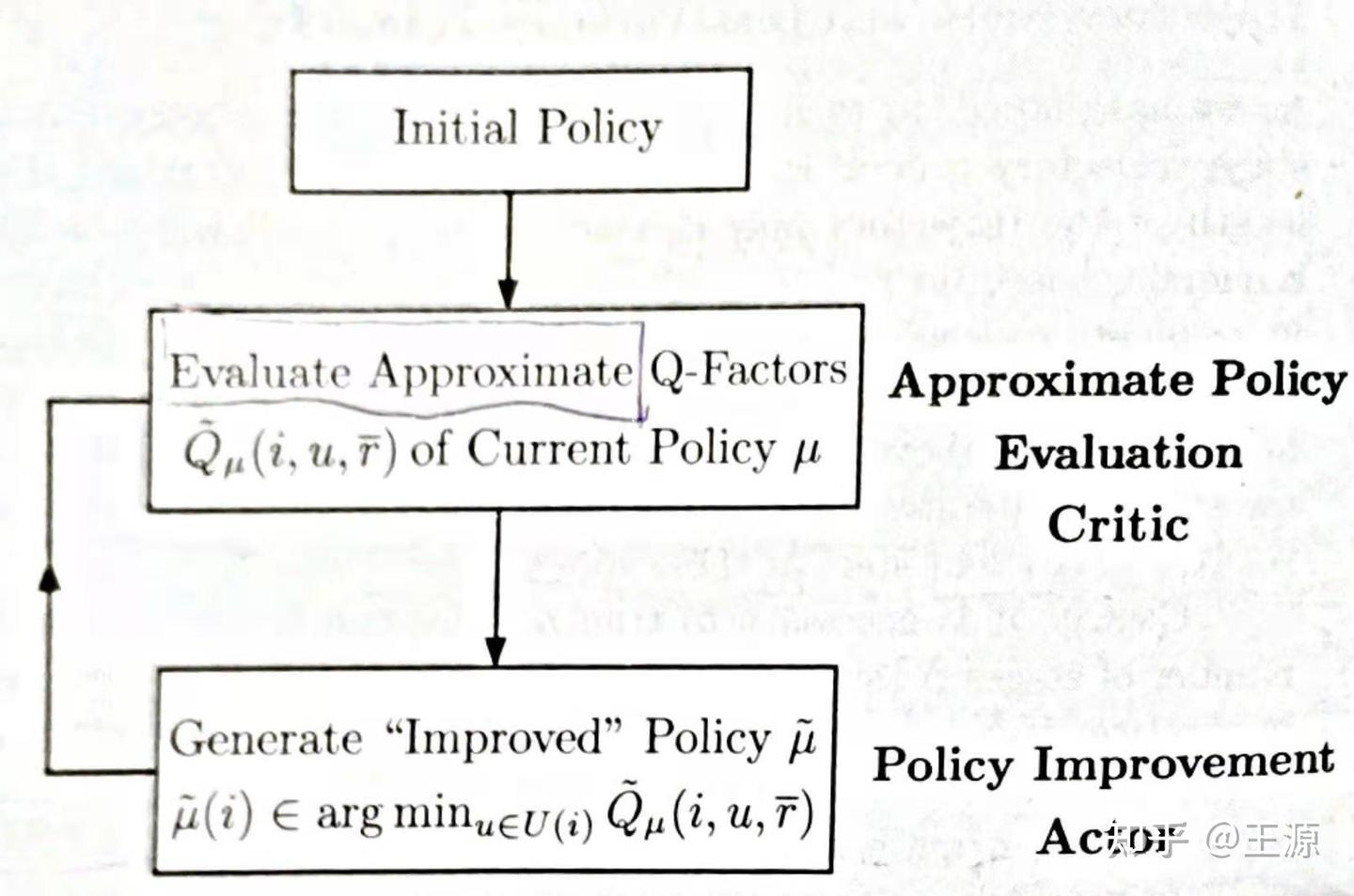
对比上一小节Model-Based的算法流程图我们不难发现,算法流程是一样的,都是有Critic和Actor两大步骤,然后循环迭代更新。主要不同点在于 Model-Free 采用的是 Q function 来做 Critic和Actor的,Model-Based 采用的是 Value function 来做 Critic和Actor的。
同样的把Q function 进行参数化近似可得 ,其中
是模型参数。训练集为
。
Critic step:实际上就是 Approximate Policy Evaluation
(2.1)
式(2.1)和式(1.1)类似,只需将原来的值函数替换为Q函数即可。
Actor step:如下所示
(2.2)
对比式(1.3)和(1.4)我们发现式(2.2)并不需要知道 就能进行Policy的迭代更新。这也是我们一开始所说的Model-Based和Model-Free的根本区别。
下一期笔记:
王源:【强化学习与最优控制】笔记(十四)Q-Learning,TD 与 近似线性规划