

上一期笔记,忘记的童鞋可以复习一下:
王源:【强化学习与最优控制】笔记(十一)无限时间动态规划分布式值迭代和策略迭代本笔记对应教材中第5章5.1-5.2的内容。如需购买教材的童鞋请点击:
在第四章我们已经介绍完了Infinite的动态规划算法。这一章我们将围绕Infinite的强化学习展开。首先先来复习一下动态规划的核心迭代公式:
(1.1)
(1.2)
在后边的推导过程中我们会用 和
来简化表达上面2个公式。
实际上是代表动态规划算子,
实际上代表Bellman算子。
1 Approximation in Valued Space 及其 Performance Bounds
同理完全精确的计算动态规划的迭代公式(1.1)是不现实的,因此我们需要引入一些近似的方法来降低计算量。主要的近似的思路如下所示:
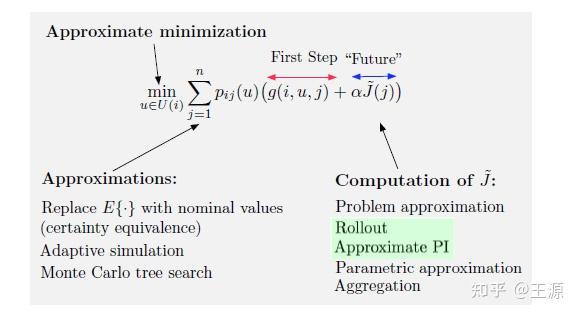
三大近似思路,和之前有限 stage 差不多。
(1)Approximate minimization: 近似求解优化问题即可。
(2)Approximate 期望:近似期望
(3)Approximate Value Function:近似 Value function
Lookahead minimization:
(1.3)
其中 表示 lookahead 的步数,
表示 discount 系数。
Limited Lookahead Performance Bounds:
表示
步 lookahead 的 Policy,
表示采用Lookahead的方式得到的 Value function,
表示一开始估计的 Value function。我们想知道是 采用 lookahead 的策略后 Value function 会有怎么样的改进?如下所示公式:
(1.4)
其中 表示 discount 系数,范数表示无穷范数。
分析上式左边是 Lookahead 的 Value function 和 最优 Value function 之间的距离,右边是其上界。其上界由系数 决定。
若 很接近1的话,则这个系数非常接近于无穷大。这时候就表明可能采用 Lookahead 的效果就不一定好。若
越大,则这个系数会变小,这时候就表明可能采用 Lookahead 的效果就会好。
需要注意的一点是 我上面的论断用了“可能”,主要是因为从式(1.4)来看 影响的是 Performance的上界,并不是代表真正的 Performance。因此从 式(1.4)不能得出
越大,强化学习算法效果越好的结论。这一点在我们之前的笔记中也有提到过。
2 Rollout with Multiple Heuristics
Rollout 算法我们在前面已经介绍过了。其主要思想是通过一个启发式的 base policy 来估计 Value function。忘记了 Rollout 算法的童鞋可以复习一下:
王源:【强化学习与最优控制】笔记(七) Rollout 与 Policy Improvement一个很重要的理论结果就是 如果将 base policy + Lookahead 得到的改进后的 Policy 是不是能比以前的 base policy 要好呢?有如下性质:
设 是 Base policy,
是通过 Base policy 得到的 Value function,那么通过如下 One step lookahead minimization:
(2.1)
得到新的改进后的 policy 为 ,有如下表达式成立:
(2.2)
那么这个性质就回应了我们前面的问题,确实如果基于 base policy + Lookahead 得到的改进后的 Policy 至少是不差于 原来的 base policy 的。我们把这个性质也称之为Cost improvement by rollout,下面的证明过程还会用到这个性质。
Rollout with Multiple Heuristics 顾名思义就是在 采用多个启发式的 Base policy 来估计 Value function, 最后在 Lookahead 的时候我们可以从这多个 Base policy 来估计得到的 Value function 中选取一个最好的来做 Lookahead minimization。这个从直观上并不难理解,所谓三个臭皮匠赛过诸葛亮,Multiple Heuristics 基本就是这个思想了。
下面开始证明 Multiple Heuristics 的 Improvement 的性质:
设有 个 base policy :
令 (2.3)
式(2.2)的意思就是 从 个 base policy 中选取一个最好的出来。
(2.4)
(2.5)
(2.6)
从式(2.4)到式(2.5)是因为 是最小的,所以肯定不会大于任取的一个 base policy 的 value function
式(2.5)到式(2.6)是因为 式(2.2)中的 Cost improvement by rollout
3 Truncated Rollout with Multistep Lookahead and Terminal Cost Function Approximation
Truncated Rollout 简单来说就是将三种策略组合在一起,Rollout+Lookahead+Cost Function Approximation 这三种方法组合在一起来用。如下图所示:
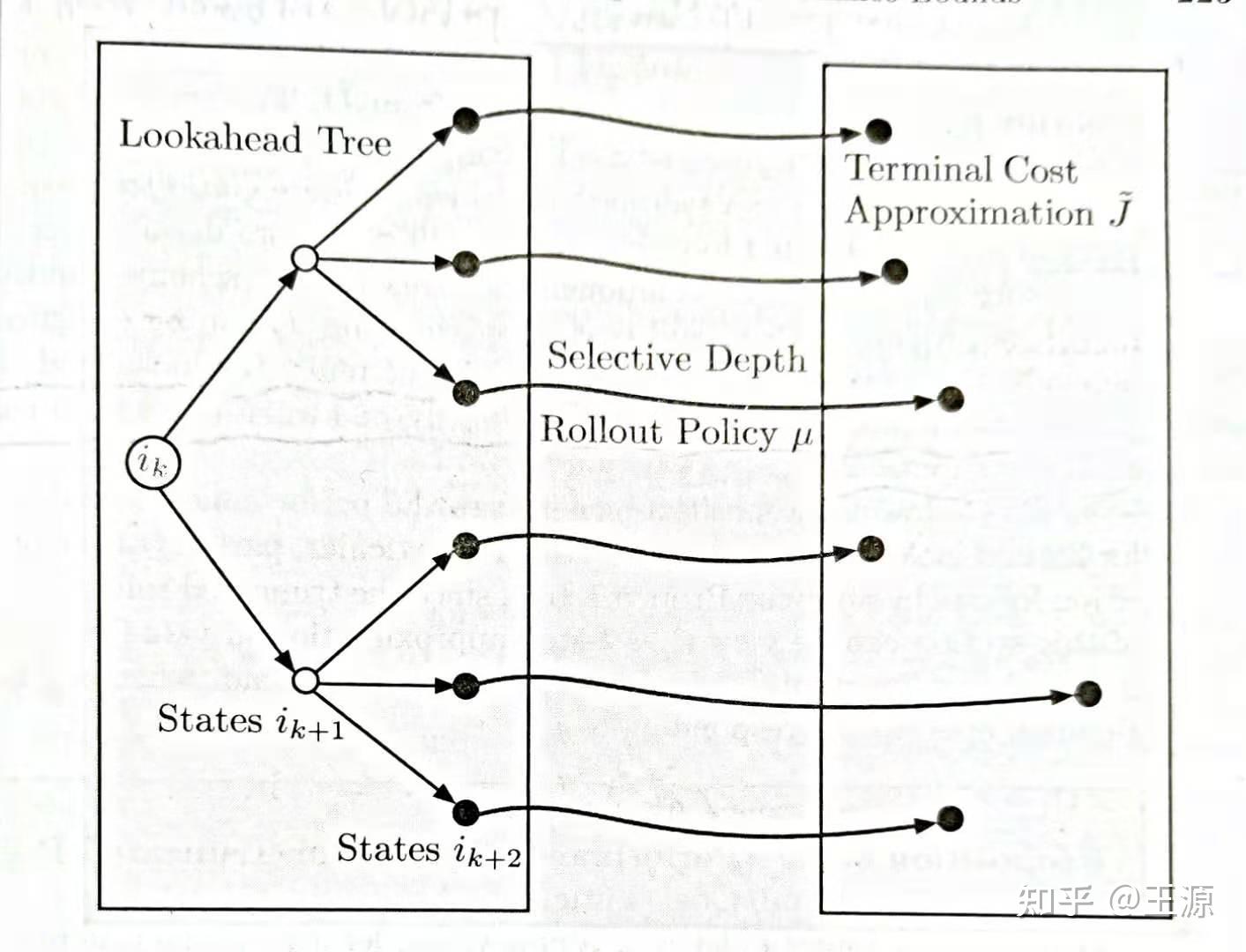
上图中先用 Lookahead 预测2步,然后用 rollout policy,但并不是用 rollout policy 一直运算到最后,而仅仅是运行几步,最后采用 Cost Function Approximation 来对终止的 Value function 做一个近似。Rollout+Lookahead+Cost Function Approximation 通过上图的方式结合在一起使用。这三种方法可以互相独立的选取,我们之前对 base (rollout) policy 和 value function 的选取和近似的方法在这里也都是可以继续用的。
定义 为lookahead的步数,定义
为 base policy,base policy 采用
步,
是对 Cost Function Approximation 的近似,
是通过Truncated Rollout 生成了 policy,那么对 Truncated Rollout 的 Performance bounds 有如下性质:
(3.1)
分析上式和式(1.4)非常类似,唯一不同点在于不等式右边的 从式(1.4)的 变成了
。这一点也比较好理解 主要是因为 Truncated Rollout 算法比之前的算法在 lookahead 之后又多了一个 rollout policy 迭代
步的过程。
如果说 rollout policy 比较接近最优的 policy,那么经过 步的 rollout policy 迭代之后使得
更加的接近于
。那么自然也使得等式右端的值更小,也就表明 Truncated Rollout 算法的性能越好。
值得注意的是 可以做成离线的,例如可以选取一部分状态变量对问题进行近似求解,然后采用 神经网络 离线地学习出一个粗略的
,然后在线的使用这个神经网络来近似
即可。
下一期笔记:
王源:【强化学习与最优控制】笔记(十三)Actor-Critic Methods