

本文算是对 Andy 这几篇文章的comment和衍生。
本文的目的,就是谈一谈「怎样检查自己是不是理解了」,旨在在阅读「知道」的基础上,进一步检查自己是否「理解」。
本文会先从信息的角度,讲清楚什么是理解,再演示一个思维工具「理解图」用来检查。具体对阅读理解的建模,会在。这个方法的建立架构最大的优点,是可以深刻地刻画理解的元过程。
1、引言:信息会改变什么?
Andy 在开发「助记又助理解」的软件中,深刻地讨论了「先理解、后记忆」这个重点。这让我想到,自己在制卡时遇到的第一个坑点就是「没看明白就制卡」。我的一个例子是,为了增强体质,我学习这篇文章以提升「最大摄氧量(vo2max)」,一个跟体质相关的指标。我通过渐进把细节都记熟了:前期如何慢跑增强肌肉毛细的氧扩散能力、后期如何 HIIT 增强心肺。但时隔一年看原文时,突然发现一个根本性的理解居然一直没注意到 ——「vo2max 反应了心肺和肌肉之间互相制约的关系」(如图),这让我挺沮丧的,我记住了很多细节,但其实没有真的明白其中的关系。
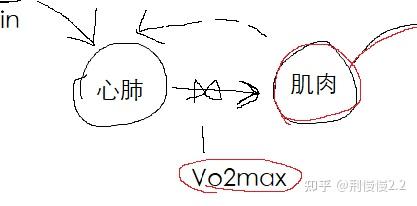
因此 Andy 在几篇文章中集中讨论「人不一定真的理解」的这个重大命题时,我深有感触。这里没理解的对象可以是主旨、作者的意思、一个强调的知识点,乃至作者视作理所应当的前置条件。
而我们常常把「理解信息」与「知道信息」搞混,如 Andy 在最近文章里所说,“只是在视觉层面解码了一遍”。那么我们 “知道信息” 时,什么发生了什么?都说信息会降低分布的熵,那么它降低了什么分布的熵?同样是降低熵,理解和知道又有什么不同?
依然用学做菜的例子来讨论。
红烧肉(菜谱):
...
第三步:加入八角、桂皮、香叶、白芷、陈皮
...
最后,炖到肉中心发白,就熟了,可以出餐了如果你学了这个红烧肉菜谱,能把它做出来,这就是「知道」—— 它改变了预期的结果。但前提是,什么叫「做出来」?
这是个很虚无的概念。现实中,我们再严谨地去做,结果也都呈现一定的随机性,所以「做出来」的结果,实际上是呈现一定随机分布的[1]。而知识的注入,改变的就是结果的分布,例如下图描绘了一个出餐时「红烧肉有多熟」的分布在注入知识前后的变化。先看左图,没看菜谱之前,做出来的菜,烧出来的结果可能过熟或者夹生,跟开盲盒一样;再看右图,看了菜谱以后,做出来的菜,集中在 “好(低夹生度)” 的一端。

这里就体现了信息的作用:增加信息,减少的是我们「推理到预期结果」时,某些输出 “参数” 的不确定度,也就是参数分布的熵。—— 注意这个所谓“参数”,它挺重要的,在阅读时请重点理解一下。
这里强调下,预期结果、场景,在本文中视作是“推理/ 推断”的结果。
上图的「理解」和「知道」之间完全可以互换,所以没有区别。但一旦引入「场景(domain)」,这两个词就截然不同。我们推断事物时,做的每一步都有自己独特的场景,可能家里缺八角、可能油温过高。知道 ,不等于知道
的分布。
思考一下,仅是「知道」菜谱告诉你的,还不够改变你真实的输出。
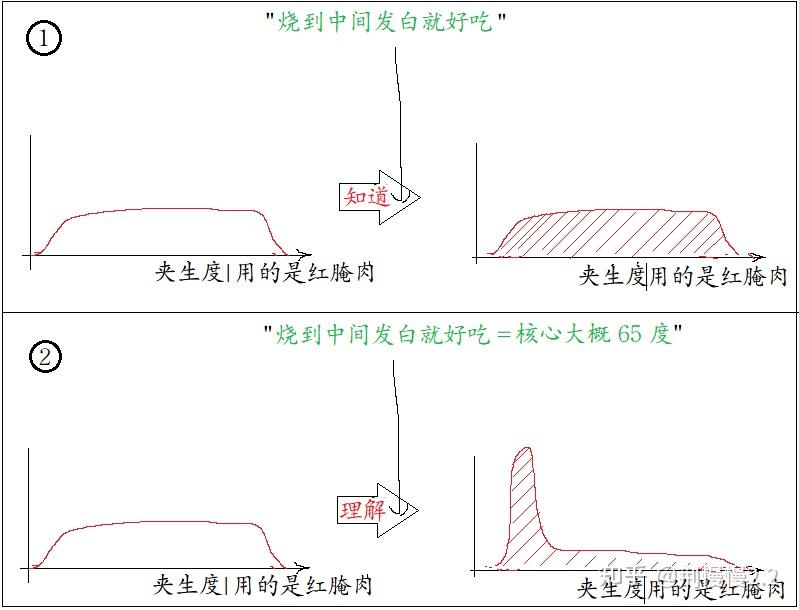
Q: 在本文中,会很强调「分布」这个概念,不如现在就问自己一下,用这个词,是作者希望影响你什么?
假设是使用了中心永远炖不白的腌肉做红烧肉(很奇怪但不是不行),此时知道 “ 「熟」==「白」 ” 毫无意义(上图 ①),分布没有被改变,获得的信息量为 0;而如果「理解」成两个场景都共有的东西 “中心温度”,那么你依然可以获得信息(上图②)。
可以合理断言,如果你「理解」了一段信息,你应该在多个「场景」下会改变推理时的输出分布。我称之为「会用」。
检查自己是否「知道」的方法,就是问一问这个知识可以推理出什么;而「理解」,最好的方法是怀着初学者心态,去介绍这个知识的场景,然后用它打个比方,再问自己。
1.1 菜谱中的典型例子
现在,我们已经将理解的过程,建模为一个概率过程了,我们用一些示例描述,看看菜谱如何改变推断的分布:
c1:假设场景里听众是个熟悉知识的大佬,他觉得不需要解释过程和结果,只要告知,读者脑子里就能自动知道有什么结果:
c1 第三步:加入八角、桂皮、香叶、白芷、陈皮。c1.1:作者心怀仁慈,决定解释理想场景下,用「异味」「香味」建模的菜肴,这两个参数的分布会如何被影响; 但提到的的「风味」,结构上看起来很孤立,我不知道「用来增加风味」是什么意思,似乎在讲废话。因此信息量很低。
c1.1 第三步:加入八角、桂皮、香叶、白芷、陈皮。如果肉有异味,香料可以掩盖*异味*。
而且因为香料有香味,它们可以用来*增加风味*的。c1.2:作者心怀仁慈,在上一步的基础上强化为「红烧肉特有的风味」来增强了这一步和整体的联系。作者描述了输出的分布中,我们关心的「红烧肉风味」这个参数分布,会受到加香料的增强。如果在 c1.1 中你自动帮作者补全,也能获得同样的感受,即使信念没那么强烈。
c1.2 第三步:加入八角、桂皮、香叶、白芷、陈皮。如果肉有异味,香料可以掩盖异味。
而且因为香料有香味,它们可以用来增加*红烧肉特有的风味*。c1.3:在上一步的基础上增加了上下文之间的联系,这一步让我们对香料的理解产生了剧变。这一步指出了红烧肉的味基是酱香,而香料只是次要却不可或缺的。它重大地改变了我们对原文的理解。也改变了在缺少八角等场景下,你的输出分布。 另外,我还特别提一下,字面「红烧肉特有风味」相同,但实际象征已经与 c1.2 里不是同一个东西了,这其实隐含了一个重大的命题:语言只是搭架子,它的本体是克苏鲁。
c1.3
第二步:加入生抽、老抽。红烧肉的*基础味道是酱香味*
第三步:加入八角、桂皮、香叶、白芷、陈皮。如果肉有异味,香料可以掩盖异味。
红烧肉的基础味道是酱香味,在酱香的基础上增加不同香料的风味,形成*红烧肉特有的风味。*c2.1:描述了多个场景下,最终输出中「异味」「香味」「辣味」的分布如何被影响。这里比之前更能调整你的输出分布,因为他强调了八角的权重,以及增加了场景(不喜欢的场景)。但第二句一来,明显有做笔记的冲动,因为:1、和整体结合度不是很高,感觉不能记住 —— 陈皮能对冲辣度,那它是不是仅仅为了对冲辣度?我可不可以用糖替代?这反而可能让人困惑了。2、「甜味柔化辣味」看起来是一个能改变很多菜谱下分布的知识点。我知道回锅肉菜谱里需要撒白糖,如果仅是为了柔化豆瓣酱的辣味,那我能不能改用甜面酱、柠檬等替代,创造我自己的菜谱呢?我感到跃跃欲试了。总之,它提供了一个深入的接口,但增加了实际做红烧肉时的不确定性。
c2.1 第三步:加入八角、桂皮、香叶、白芷、陈皮,
*其中八角提供主要的风味*,其他香料提供复合型的风味,
整体上会掩盖异味。这些风味并不是必要的,*你要是不喜欢,可以换成别的*。陈皮提供的甜味会让辣味更加柔和。c2.2:在上一步的基础上主次分明,用一颗完整的理解树,去解释了多种场景下,这一步产生的影响。
c2.2 第三步:加入八角、桂皮、香叶、白芷、陈皮,其中八角提供主要的风味,其他香料提供复合型的风味,整体上会掩盖异味。
这些风味并不是必要的,你要不喜欢,可以换成别的。陈皮提供的甜味还*顺便*让辣味更加柔和。c2.3:在上一步的基础上,给出了一个可以应用到几乎所有做菜场景下的知识。这个知识不仅有泛化的陈述,而且有如何「映射」到实际的操作,可以帮你在更多场景下调整分布(但正如我刚才所述,语言是框架。光是陈述和被动接受知识,能做到的也仅此而已了。)
c2.3 第三步:加入八角、桂皮、香叶、白芷、陈皮,其中八角提供主要的风味,其他香料提供复合型的风味,整体上会掩盖异味。
这些风味并不是必要的,你要不喜欢,可以换成别的。陈皮提供的甜味还顺便让辣味更加柔和。*再强调一次,什么东西是香的,
你加进去大概率就是香的,要是不喜欢,就不加*(注:本句来自 BILIBILI 的 up 主 @鞑厨高寒)仔细感受这些例子,我们有三点发现:
1、文字不是越少越好理解,这需要脑补很强的作者想告诉你的 —— 10 张纸的高数书不是写不出来,但学生不可能读得懂。
2、概念如果无序存在,就不容易理解(c1.1中的风味);哪怕很有价值,但可能也让人会让困惑和分神(c2.3)。(除非你理解作者省略掉的部分,明白了它和主体的关系。)
3、信息量增大,文字会不可避免的增多。越需要好的结构降低文字解码时的认知负荷。
以上几个例子可以佐证,我在引言里对理解的断言是合理的。它基于两个无法反驳的假设:
1、「获取」信息会改变前后结果的「参数分布」,
2、「理解」获取的信息,大概率比「仅知道」更具适应性(这一点也不是不能商榷,比如九转大肠那位)。它也隐含一些很深刻的洞见,在此先按住。
为了校验这种合理性,我在游戏、python 教程等上做过一些简单的测试。我邀请你也和我一起校验和修补他,你可以提供一些例子给我看看能不能跑通。
这里我还想提的一点是被动学习,「知道」是非常重要的事情,它是万物的基础,你在「知道」很多知识的时候,依然能获得一些令人激动的东西。但理解一定是主动的,因为你必须要通过去调整自己的分布参数,它能提供更多更高维的见解。
1.2 共同创作、「理解图」
如果「理解」是对推断时「输出分布」的影响,那么被阅读的材料,可以理解为作者在演示知识对场景「输出分布」的影响。你要做的,是从这个演示中,获取关于知识如何解释其他场景的理解。
这有点像解方程组。从多种场景中推断出合适的、描述 “知识的参数”。

考虑到作者的演示永远不可能包罗万象,因此我们实质上在不断通过自问自答,帮他补全以获得我方的理解。这个过程中,你会从他的考虑中,脑补如何应用到自己感兴趣的场景,因此理解的过程,可以看做是和作者共同创作的过程。这个过程我称之为「共创」
用一个图来表示:
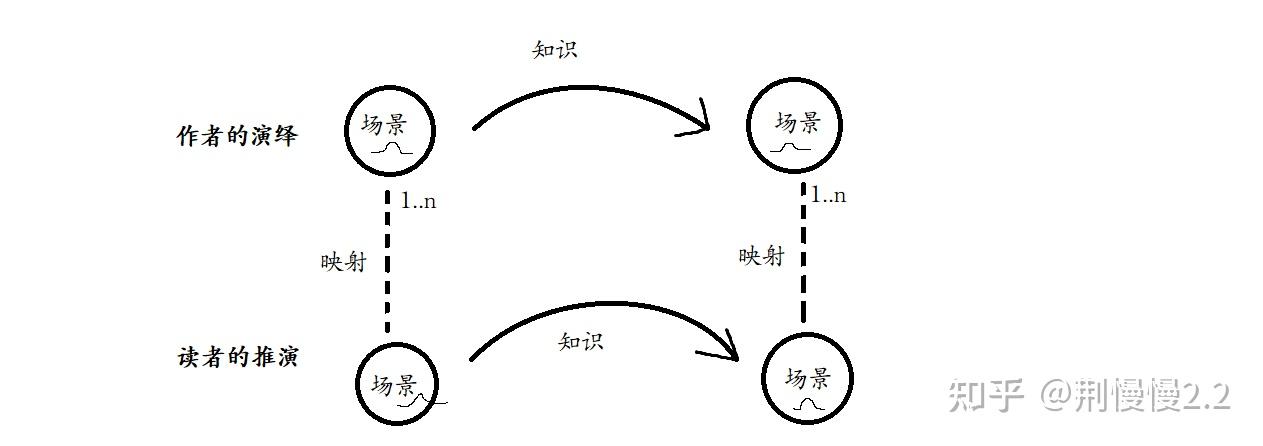
上方,是作者描述的知识,对推断输出的改变。
下方,是理解发生后,你的推断输出的改变
我们常用的一些启发式的检查理解的提问,用这张图可以得到形式化的描述。不过我在这里只是简单地用文字描述下,以后后专门讨论:
| 自我提问 | 理解图视角 |
|---|---|
| 「这个知识意义是什么?」 | 「知识可以影响哪些场景?影响多大?」 |
| 「这个文章有什么用?」 | 「这个文章提供了哪些知识和场景?」,「这些知识可以让哪类场景的分布得到改变?「知识注入后,场景的特征参数变了吗?」 |
| 「这个知识能用到我们关心的 B 场景吗?」 | 它描述的场景有哪些参数,是不是太理想化了 |
| 「这个知识如何实用起来?」 | 「它要在实践域中增加哪些参数才能应用,增加这些参数现实吗?」 |
有一些检查可能比较复杂:
| 「看了这套王者荣耀的视频后,你对这个英雄的优缺点有了什么理解?」 | 「在组合不同的场景参数后,英雄对局面哪些参数影响很大」 |
|---|
有一些知识例如「它和上下文的联系」,主要还是属于知识的「表示」而非「推断」的建模范畴。因此不列入。
这张图,是我称为「理解图」的工具。它可以显示理解的过程,知识本身或者场景的复杂性,被表示为隐参数藏在节点里面了,因此只需关注推断过程。它的第一层目的,是引导你发现理解上的缺陷。
细说原理的话,你要找到一个共同的知识构成,既满足作者场景的推断,又满足其他场景的推断,又不违反明显的事实。它希望做的,是引导你关注知识注入后,结果呈现的分布的变化、映射到你关心场景时,层面要比知识本身更高一个级别。在任何时候,它都应能帮你发现理解上的问题,洞察你要关注哪些东西,发现知识的意义。如果你喜欢,可以去 2.1 节帮我检查它是如何定义的。
即使我不解释,你也能看出来它怎么用。
不过我还是不得不用一个实例来简单解释下,正好群友发来一篇文章,3.5万人研究发现:经常下馆子、吃外卖,死亡率增加49%,爱做饭的人更长寿
这一篇文章提到 Association Between Frequency of Eating Away-From-Home Meals and Risk of All-Cause and Cause-Specific Mortality 的这篇论文,调查了吃外卖、下馆子所产生的死亡风险。
它的结论很简单「经常食用(每天≥2次)餐馆的食物与全因死亡的风险增加显著相关,全因死亡率高49%。」,它的知识在横向上没有难度,很轻易地改变了我们对分布的估计,难点主要集中在纵向上。
我们用「理解图」来校验自己的理解是不是正确。首先画出作者在推断什么。

接着,假定你理解了,我们应该能把它外推到一个场景里。试图考虑能不能在新的场景中学到分布
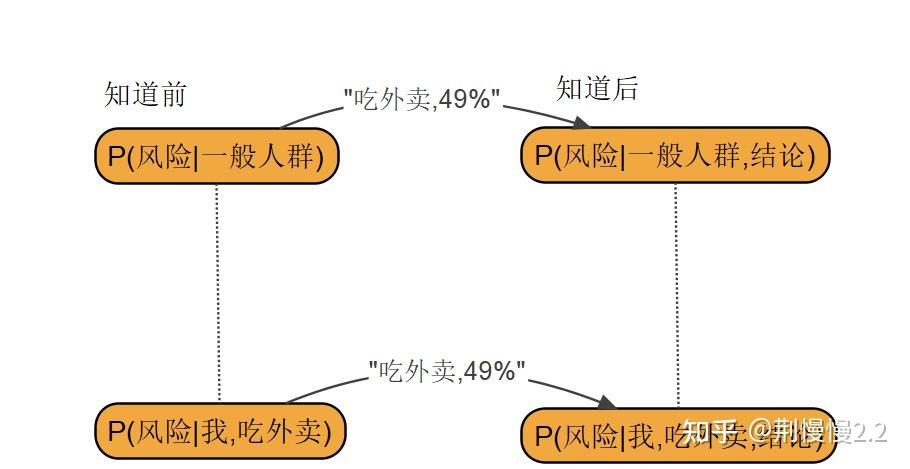
第一步,逐一拷问自己,知不知道图中每个节点是什么情况,有哪些参数。
第二步,回答下方新的场景里,知识如何影响我们的推断。
在这个辨识过程中,我们会不断调整大脑内对知识的理解,建立一个合乎逻辑的模型,从而同时满足这两个场景。注意,图中的元素原文可能省略,但一定存在,不可能没有,这便是要求你去和作者共创的部分。
开始先考虑左侧场景的映射。你一定会留意到文章的场景和自己预想的有不同,因此会提出一些问题:
- Q1:原文场景是什么? —— 论文如何评估场景(一般人群)的,这个评估方式应该在场景间一致,可以套到「我」头上。
- Q2:「我」的场景是什么?—— 我在论文的评估中会处于什么位置。
- Q3:「一般人群」场景要如何映射到「我」?—— 或者说,每个人的特征分布都不同,作者用什么方法保证了结论自信,认为对「我」有说服力?
其次考虑右侧场景:
- Q4:风险怎么评估的,参数有哪些?
- Q5:吃外卖如何影响风险的参数?
- Q6:这种影响,如何落到「我吃外卖」的场景上?
这些问题不一定有解,也不一定总是有意义[2]但它能从分布角度提供大量的元认知 —— 他的读者是谁,为什么关心,哪些参数我和他的共性,我要加入哪些东西才能外推他的结论,我要重点关注什么...
在这个过程中,我们会检查和校准自己的初始认知,意识到自己的认识是错了,没有和作者对齐。
如果是实践性的场景比如做菜,你有自己的做菜经验,还会想到做一些实验去确定其中的隐参数。例如对比加甜面酱和白砂糖对辣味的缓冲作用。
这里不得不提一下 Q3,这一条具有深刻洞见。它直接点出了各种 paper 中那么多统计指标、模型为什么而存在。
总得来说,有了这些问题,我对 paper 的关注点就出现了改变,仅就我们关心的这个结论而言,现在我最热切的全是和它最相关的东西。
现在,因为 Q1 和 Q2,我们立马直接就在开头注意到了我们所关心的内容,1、场景的参数包含年龄性别等,2、它为什么要调整「场景参数」的,如何调整的,调整之后是不是为了迁移到更多人身上?
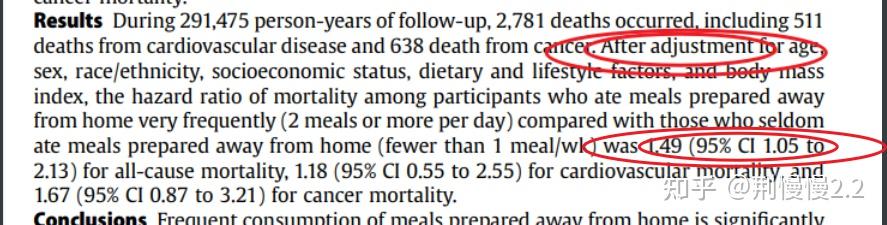
接下来,我们看到一些指标如统计相关性,“1.49倍 (95% CI 1.05 to 2.13)” 似乎是一个统计相关性的指标,它是不是为了解决结论如何进行外推的问题的?还是解决。
如果你没上过统计课,你可以带着这个猜测去学习统计知识,这大大降低学习难度。
如果你学过统计,但没有很深的理解,此时你在理解图的层面,会更容易观察到一些现象:相比做菜的知识,统计类的结论似乎直接影响后验分布分布参数,这中间出现的问题,是不是就是统计方法、指标存在的矛盾源头?你因此会加深对这些知识的理解。

为了方便,你可以直接把它提出来让 GPT 回答。经过回答之后我知道,对于一般人来说,外卖带来的的真实风险可能在 5%~113% 之间,具体看人的特征,我需要查看文章中它具体怎么描述场景的,以确定自己算哪种。
在另外一个世界线上,小白的我对这个点提出了一个问题:我一开始还想不通,后来突然明白了,不就是置信区间么。我意识到统计性的论文还是比较特殊的,它会直接用参数刻画这个场景的分布,但不会直接给出相关的隐参数,这是个重大的理解。我接下来要做的可能是考虑这种参数如何转移到其他场景上。
限于篇幅这里不做继续讨论。有空的时候我会以「供给决定需求」这个知识来举一下例。
整体而言,你此时做的,就是试图为论文增添信息,让它结合你的理解,解释你的需求。现在,你非常清楚解决自己的场景要利用哪些信息,才能将文章的结论迁移到更为通用的场景,因此你也能据此去评估论文、信息源的好坏。短时间内,你就比其他人更懂如何看一篇文章。这就是主动用合适的工具去「理解」所产生的伟力,而这一切是对统计一窍不通的我所能做到的。
要注意的是:
1、这里为了显著,用了论文场景,但这个例子很可能给你带来「只能用在结论上」「不能用在写代码上」等错误结论,请仔细检查自己的分布。
2、但「理解图」本身是为了检验原子理解设计的模型,对太重的知识建模,搞不好瞬间用光你的情绪资源。你会发现自己原来有太多课要补,原本就不太理解置信区间,P值什么的,现在要一次性全部了解,那谁都受不住。
3、「理解图」比较重,应当和一些启发式问题配合,要知道语言就是最好的模型框架。这些问题是我们平时就会问自己,比如「意义是什么」、「和上一个概念之间有什么联系」,它们要么是对理解图的探索,要么是对参数本身的探索。
2. 建模、泛化、例子
2.1 场景是知识的结合处
即使我拿来举例的 c2.3 已经很详尽,学习后,我们依然可能被刁钻的测试人一句话问倒:
- Q1、「可以加纳豆吗?」
- Q2、「香料如果都不加会怎么样?」
- Q3、「我用咖啡机把香料萃取后再加进去可以吗?」
- Q4:「我如果超过你推荐的 50g 香料用量会怎样?」
... ... 如果问题可以视作构造场景,那么这些场景的构造比较灵性,甚至会让作者愤怒,如果是友善问答,身为作者最好先问一句「为什么这么想」。
Q3 咖啡机萃取那个问题,看起来是在试图考虑「香料是如何产生作用的」,提问人试图用「萃取」来理解「加香料」这个过程。如果你正好在研究咖啡机,想到它一点也不奇怪。
这个问题有趣之处在于,假设我是先研究完红烧肉,再去学习咖啡机教程的,我可能也会发出同样的提问。我们会发现,「场景」其实不是知识的附属品,两个知识之间,通过场景可以形成连接。从知识建模的角度看,它们在用一套相同的参数描述。
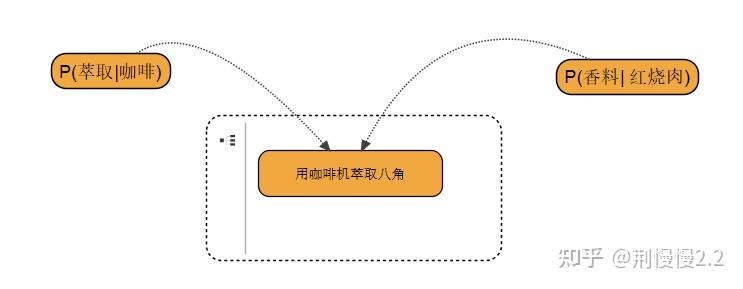
我最喜欢且畏惧的是一些打破边界的提问。它反应的是知识自个儿和自个儿的连接,你可能对知识产生更高层面的理解,当然这种问题情绪消耗很大,因为往往自己不能明确表达需要什么样的知识来回答。
「Q4:我如果超过你推荐的 50g 香料会怎样?」
×「A(你不希望的回答):看个人喜好」(没有信息量)
√「A(你可能希望的回答):你想问的其实是,为什么给了一个绝对的用量。实际上,这是对相对用量的近似。做菜跟配香水一样,味道的重点是主味和香料的一个比例,超过的话,你就改变了综合味道的 “相位”。尽管我可以回答「适量」,但没有一个基线作为参考,菜谱对新手没有意义」
顺便一提,理解中,常常涉及到 “不封闭” 的知识。也就是说依赖的一些新概念不在你和作者共同书写的文章之中。这是比较危险的,存在无限延伸下去的危险,这就是另外一个新话题了。
后面谈到泛化和建模的时候会指出,场景和知识都可以视作一组参数的分布。在推理这些问题的过程中,我们会不断调整知识的参数,让它活起来,成为变得更正确、更能用到更多场景
2.2 概率图建模,但魔改
2.2.1 参数意识和知识的模型
我们阅读的时候,常常感知到知识的模型的存在,一篇文章可能在描述一个流程、机制、关系、状态机,或者它的一部分。这是一种知识的「表示(representation)」。
例如,电路中的逻辑「与门」就可以用真值表、命题、等多种方式表示。一个英语单词,可以是语义网络的一个节点。
这种表示可以用一组参数去描述,每个参数都视作随机变量,只要参数够多,你模型再复杂都可以表示起来。例如流程图可以视作是一组节点和边的组合,理论上你可以用一组参数分别描述它们的节点、节点和节点之间的联系。
但一般的建模方法,表示能力有限,也不符合实际。1、你无法洞悉全部变量。2、敏脆(i.e. 模型对参数敏感)。最重要的是,你很难在刻画机制的同时,又谈模型的使用(也叫「推理(inference))。
例如,你理解了一个单词和未理解它之前,它对应的模型的表示截然不同,所以你一开始没有办法洞悉这个模型里全部的东西,也无法用一次搞定的模型去描述它。也就是说,模型本身是理解的结果,而非过程。
只有找到理解的过程,才能检查我们的思考。
概率图模型(如贝叶斯网络或马尔可夫模型)也是一种建模。但它提供了一种方式,将知识的表示和推理过程分开。它的基本思想是,既然难以表示,那我就不表示了。而是,管你是什么精巧结构,含有多么复杂的因子,一律拍平。替代地,用一组参数 来描述 —— 这个其实在 ai 里很常见,比如损失函数的
的下标就代表了所有参数。这个参数就像 DNA,它描述了知识的“本体”,大模型里,GPT 3.5 “参数量 175B”,也是用的这种方式。
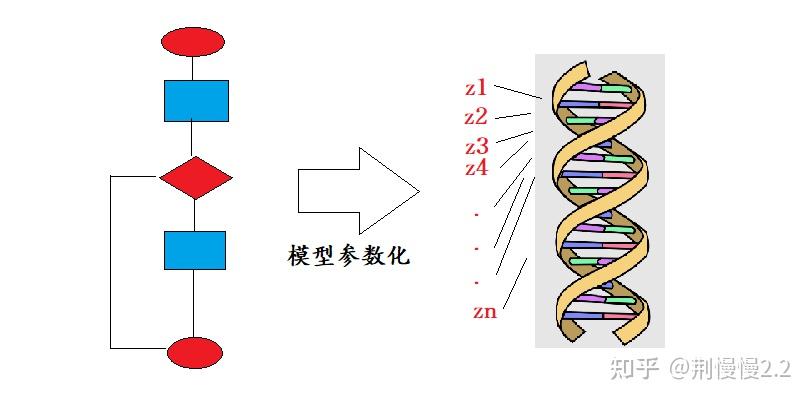
基于此,就诞生了贝叶斯网络等建模方法,并得到了广泛的应用。贝叶斯网络中,将相关因子(影响结果的参数)用有向图连接。当推理时,就是给 z 取各种值或者分布,然后转移到下一个节点。
2.2.1 建模
这种模型有帮助、但对理解过程来说,不是特别有帮助。但它提供了一个很强的启发性 —— 我们可以用一个参数组,来表示一个知识的模型。
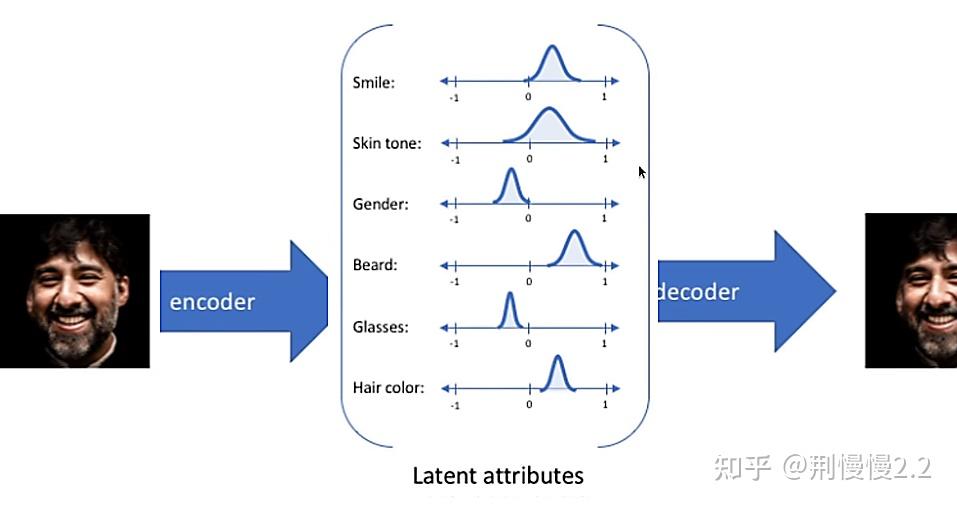
例如,VAE 模型(一种生图模型)中,可以学会用一组笑容、肤色、性别、头发等属性去描述脸部。那么令参数 ,
,
... 分别代表笑容、肤色,性别... 等,就可以用来描述这个人的脸部
。注意,这些都是隐式参数(latent variables),这意味着它一开始没有观测到,而是随着学习获得的。
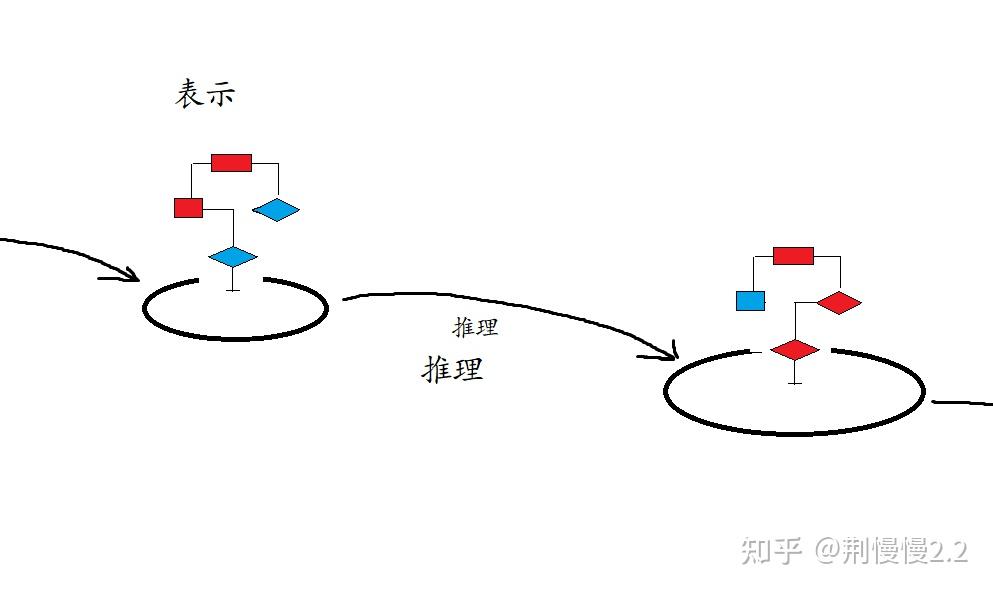
回想我们的理解过程,它也是知识表示和推理过程分离的(下示意图):我们根据材料,在脑海里确定出一个模糊知识的模型,然后围绕它不断加入现有知识、场景、问题进行推理,推理出一个又一个证据,反过来确定了模型。

这个示意图是随便画的,但假设是明确的 —— 理解之后,知识的模型就会清晰。
现在,思路一旦打开,仔细想想,就会发现学习中的各个元素都是殊途同归,我们可以用这个思路表达场景、知识、理解。
知识本身视作一种模型,所以可以用分布 描述;输入场景考虑的是对知识模型参数输入后的结果,是一个状态,也能用参数描述,所以场景和知识都能进行概率建模。
人是朝着信息最大化追逐的生物。我们的思考、提问,也一定是在朝着信息量梯度最大的方向前进。也就是说,理解过程的建模,一定有两个状态,“颅内模型” 从模糊到清晰描绘出来。再考虑清楚其中的依赖、基本任务,就可以把理解图的基本架构画出来了。
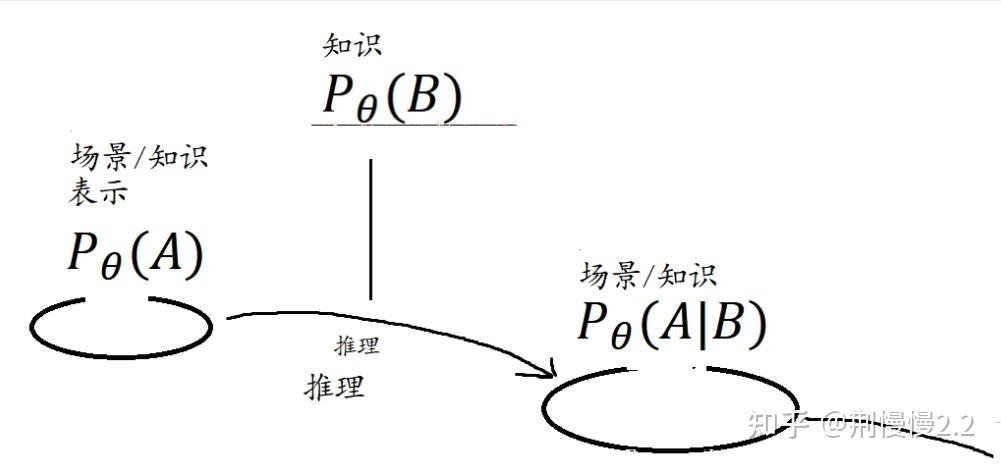
与概率图模型不同的是,1、理解图是彻头彻尾的推理。它只表示新知识加入前、加入后,场景分布的变化 2、「理解图」中有自己特有的结构「域映射」,域是一个场景的特征、参数的集合。我相信,如果两个场景都能共同使用某个知识,那它一定有相似的参数分布(域适应)—— 举个例子,你是金融专业的,然后 985 的 CS 大佬跟你分享校招经验,那他传授的经验里,应用的场景就和你截然不同。这些表现为隐参数分布上的区别。而如果他的知识能应用到你身上,那他一定给出了一些对这些场景共同特征的观察。
非常多的东西发生在域映射的过程中,例如王刚做菜的域里有行星发动机,而你家只有电磁炉不能爆炒。那么为了迁就你会如何做?例如实践中的新知...
(待续)
2.2 泛化、迁就和参数
这一节想将一些东西讲清楚,但我觉得累了,所以就写一点笔记,避免忘记以后再说。
理解需要泛化。泛化是适用的场景增加,而知识的隐参数量不变。在红烧肉的例子里,一开始用的是肉的颜色参数去指示熟度。那么,同一个知识需要有更多维度的参数,才能泛化到不同场景里(这意味着隐参数更加接近主要特征,参数空间秩更低)。
理解前: 理解后:
但在域映射的时候,往往域中不会提供一些东西。那么你就必须迁就它。假设你家没有温度计,那大概会替换成别的参数。比如看时间。
迁就前: 理解后:
这个事情经常发生在写代码的时候。
(待续)
参考
- 2.1 节中会说明,准确的说是一组参数的分布。
- (比如你会发现文章结论不能迁移到个人身上,只能迁移到以我为代表的人群)