

需要电子版的同学可以从如下链接中获取,电子版的草稿版本:
Dimitri P. Bertsekas 强化学习2021版教材和视频课程推荐上一期笔记,忘记的童鞋可以复习一下:
王源:【强化学习与最优控制】笔记(八) 模型预测控制(Model Predictive Control)本笔记对应教材中第3章的内容。教材中第三章的内容主要是讲 如何采用线性回归或者是神经网络等经典的机器学习模型来学习 Value function (值函数),Q function (Q 函数) 和 Policy function。这块内容本质上属于机器学习的内容,我默认大家都比较熟悉机器学习的内容,所以仅通过一篇笔记简单过一遍即可。不熟悉机器学到的同学 你可能需要再补一点机器学习相关的内容。
1 机器学习简介
机器学习(监督学习):利用输入输出数据
在函数族
中寻找近似输入输出关系的映射
若函数族 选择如下一族函数:
,则可以写出
表达式为:
(1.1)
函数族选择的不同就代表了不同的机器学习模型,例如如果选择的是神经网络 表达式就比较复杂了,如果选择的是线性函数 那就是标准的线性回归问题。随着深度学习的发展,我们目前有了一些非常好的算法可以用来做帮助我们进行输入输出关系的拟合。
采用如下优化问题来得到参数
(1.2)
若函数族选择为一个单隐含层的神经网络,则可以写出
表达式为:
(1.3)
表示神经网络的激活函数,
矩阵表示输层权值的矩阵,
表示bias向量,
表示输出层权值,
表示隐含层节点数目。
求解如下优化问题得到神经网络权值参数
(1.4)
关于(1.2)和(1.4)式中优化问题的求解大致有2个思路。一个是如果模型像上式(1.2)这样是线性的话,那么直接可以采用最小二乘的方法就能得到最优解。如果模型比较复杂像神经网络式(1.4)这样的话,那么一般采用梯度类的算法来迭代求解优化问题。具体的求解算法在这里就不再赘述了,一般的机器学习的教材都会有讲,不熟悉的童鞋可以找一本机器学习的教材补一下相关知识。
2 Value Function Approximation
知道了深度学习/机器学习可以很好的帮助我们利用输入输出数据对函数输入输出关系进行拟合之后,我们还是回到强化学习/动态规划的核心问题上来:
(2.1)
如上式所示动态规划的难点在于 value function的计算 ,大多数时候我们无法去计算真正的 value function
,那我们选择退而求其次来近似 value function
。那进一步我们会相当把
参数化表示出来,即表示为类似于式(1.1)中那样一族函数之和的形式(我们这里为了简便起见统一都采用式(1.1)比较简单的方式来表达Value function,采用神经网络式(1.3)的模型也不影响我们下面的分析),进而通过求解参数的目的达到近似 求解 value function 的目的。令
,其中
为模型的参数。进一步写成:
(2.2)
当然同样的这只是一种写法,等式右边可以是一个多项式函数,也可以是一个神经网络的模型等等其它的函数族都是可以的。如果等式右边是一个神经网络,那自然我们可以用到最新的深度神经网络来帮助我们拟合逼近值函数了,这也就是深度强化学习的基本思想。到这里我们需要明白最最关键的一点在于我们将直接求解值函数的问题转化为了求解参数的问题。
通过求解以下优化问题可得参数 :
(2.3)
其中 表示样本个数,
表示在stage k 的一个采样样本。
从上式中我们发现对 Value function的近似实际上是 需要进行一系列的近似。要想求解 就需要先知道
。因此对Value function 的近似过程也是类似于之前我们求解动态规划的过程一样,先从stage N 开始,然后按照式(2.3)一个stage 一个stage向前推进。这么做的原因在于 每个stage 都有一个 Value function,从比较general的角度来看,每个stage 的 Value function 都是不同的也就需要不同的模型来近似来训练。我们可以看到整个计算量是非常大的,我们需要训练 N(stage总数)个模型来近似 Value function。对现在的深度学习而言 训练一个深度神经网络可能就需要大量的计算资源,在这里如果是需要训练N个深度神经网络其计算资源开销是非常大的了,所以在强化学习中一个关键问题是如果降低采样的成本 如何降低计算开销。如果说在一些静态问题中,每个 stage 的 Value function 是相同的话,那么我们就可以做很多的简化来降低计算量了。
3 Q function Approximation
Q function 的近似和 Value function 的近似基本一样,类似的可以将 Q function写成如下含有参数的形式:
(3.1)
类似的求解如下优化问题得到参数
(3.2)
Q function 近似需要注意的一点是 Advantage Updating,我们可以不直接对 Q function 进行近似,而是对其差值进行近似,如下所示:
(3.3)
从动态规划算法中我们有 。我们可以将上式中
函数理解为 在 Q function 减去一个数。很明显我们可以看出
函数的变化范围比原来的Q function要小。每次在
函数的值都要在 Q function的基础上减去一个
有点类似于归一化的作用一样。这样
函数的值对
的变化就没有那么敏感。在教材166 Figure 3.4.1给出了一个图 用来直观的解释这个问题。
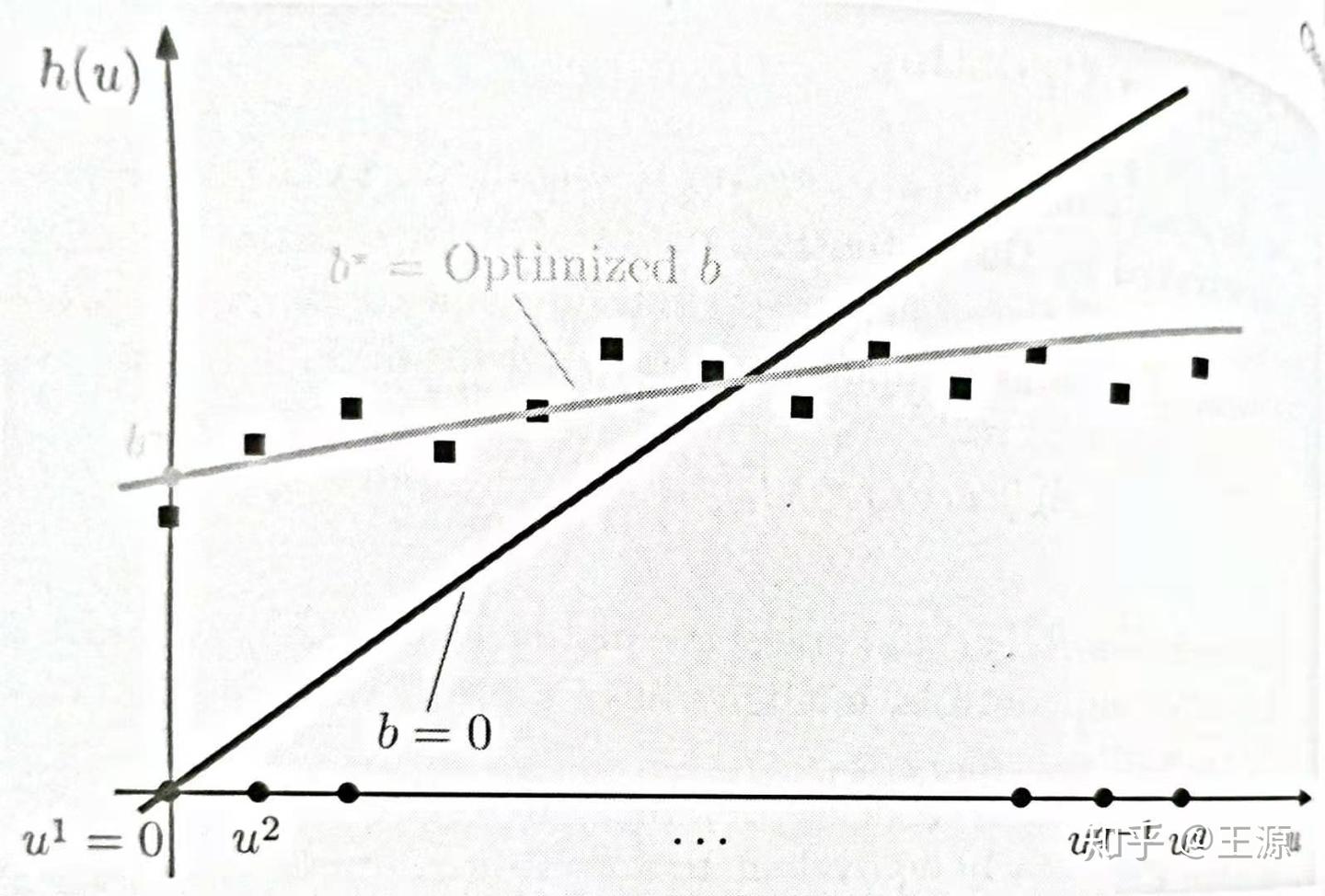
这里的目的是要拟合逼近函数 。在线性回归问题中相当于增加了一项b,也就是相当于令
。从上图中可以看出加了一项bias之后的拟合效果要比不加b的效果好很多。那么同理这里的
就相当于我们之前多加的
这一项。
4 Parametric Approximation in Policy Space
前面我们讲了 value function approximation 和 Q function approximation,严格来说它们两个都属于 value function approximation 这一个大类下面的内容。同样我们也可以做 Policy function approximation 对应教材3.5节。教材中是将 Policy function approximation 看成是一个分类问题,然后同样是采用机器学习的模型来进行训练。
下一期笔记:
王源:【强化学习与最优控制】笔记(十)无限时间动态规划和随机最短路问题