

上一期笔记,忘记的童鞋可以复习一下:
王源:【强化学习与最优控制】笔记(九)值函数,Q函数和策略空间的近似需要教材电子版的同学可以从如下链接中获取电子版的草稿版本:
Dimitri P. Bertsekas 强化学习2021版教材和视频课程推荐本笔记对应教材中第4章4.1-4.3的内容。由于电子版的内容不是很全,所以也推荐大家来购买纸质版,需购买教材的童鞋请点击:
从本章开始我们研究的问题从有限时间到无限时间问题。
1 Overview
无限时间问题(Infinite horizon)和有限时间问题(finite horizon)主要的区别有2点:
1 无限时间问题考虑的是 无穷多 stage 的问题。
2 无限时间问题里的系统是稳态的,也就是说动态系统方程,每个阶段的 cost 还有噪音的分布等并不会随着时间变化。
对 Infinite 问题的分析要比 finite 问题困难一点,因为涉及到无限就需要分析收敛性,需要极限等数学工具。另一方面 Infinite 问题很多时候会得到比 finite 问题更加漂亮的结论。需要注意的是 绝大多数书中内容是对有限数量state和有限数量action的分析。
Infinite 问题中的 cost function:
(1.1)
其中 表示初始状态,
表示 policy,
表示系数。
我们不妨对比一下 finite 问题中的 cost function 以便于我们更好的理解:
(1.2)
Infinite 问题 和 finite 问题的 cost function 的区别在于:1 infinite 是有极限运算的,而 finite 是有限项求和;2 infinite 问题中多了 系数 ,这个系数也被称之为 discount 系数。第一点很好理解,第二点 多了一个
系数,一般情况下我们会让
,它有两层含义:1是 对于距离我当前时间步
越远的时刻,那么其对整体 cost 的值的影响会减小,所以就通过这个系数来体现,因为随着
增大
会变小。2是 在收敛性证明方面 有了这个
系数 才会让整个 cost 的值不会趋于无穷,也就是无需额外条件就可以保证了收敛性。
在本章会研究两类问题:一类是 stochastic shortest path problem ,一类是 discounted problem。在理论上可以证明这两类问题实际上是等价的。
依据DP算法给出 Infinite 问题 不含 discount 系数的递推表达式为:
(1.3)
和 finite 问题不同在于 我们的 stage 有无穷多个,所以大致我们可以推测出如下的结论:
(a) (1.4)
其中 是最优的 Value function 的值
(b) (1.5)
对式(3)两边取极限,可以得到上式。上式是对任意状态都满足的,所以每有一个状态就有一个与之对应的方程。这个方程也被称之为 Bellman's equation
(c) 若 是式(5)的最优解,同时最优解的 policy
被称之为 stationary。值得注意的是 这里最优的policy和初始状态是没有任何关系的,这点直观上也很好去理解就是 对于 infinite 问题而言 极限的前有限项都不会影响最终极限收敛的值。这个性质实际上是 infinite比较好也比较重要的性质。
2 Stochastic shortest path problems
本小节我们先考虑没有discount系数的问题,下一小节再讨论含 discount 系数的问题。
如下图所示就是一个 Stochastic shortest path problem (SSP)
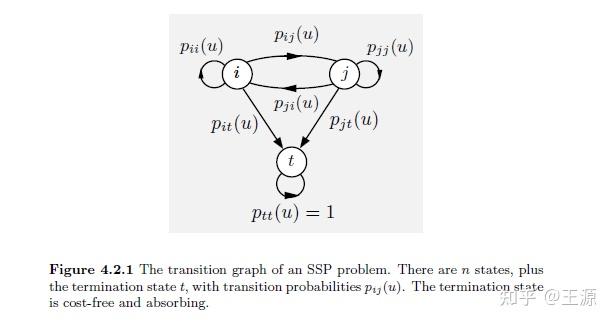
其中 表示从状态
转移到状态
的概率。可以看到图中有一个 终止状态点,当系统进入这个状态之后 就会停止 其 stage cost 为 0,用公式表达为:
(2.1)
根据式(1.5)可以写出 SSP 的 Bellman's equation
(2.2)
上式实际上就是把式(1.5)中的期望值 按照定义写出来之后的得到的。
根据式(1.3)可以得到 Value function 的迭代公式
(2.3)
同理,上式实际上就是把式(1.3)中的期望值 按照定义写出来之后的得到的。
式(2.2)由三项构成:
(a) 从状态
到终止状态
的 cost的期望
(b) 从状态
到非终止状态
的 cost的期望
(c) 状态
的 cost to go 的期望
之前我们讨论过的确定性的最短路的问题可以看做是SSP问题的一种特殊情况,即令 那么 SSP 问题就等价为一个确定性的最短路问题了。
在SSP中一般会有如下假设:
存在一个整数 对于任意 policy 和 任意初始状态,使得经过
个stage到达终止状态
的概率严格大于0,用如下式表示:
(2.4)
对于所有初始状态和policy 不到达终止状态 的概率为:
(2.5)
基于以上假设我们得到一个重要的推论:随着stage的变大,不到达终止状态的概率将会收敛到 0。
证明:由定义易知:
(2.6)
等式右端第一项是等于0的,因为 表明在stage
的时候已经到达终止状态了,则在
以后的状态都停留在终止状态,因此是不会出现
的情况的。
式(2.6)去掉右边第一项 由此可得:
(2.7)
由式(2.5)和(2.7)易知:
(2.8)
由归纳法进一步可得:
(2.9)
所有随着 增大,不到达终止状态的概率将会收敛到 0。
QED.
基于以上条件,我们可以得到SSP问题的2个性质(教材上有4个性质,我这里只列出前2个,因为后2个很简单):
性质1: 设最优的cost为 对所有的状态
都是有界的。对于任意的初始值
,通过如下值迭代算法
(2.10)
产生的数列 收敛到
对于所有的
性质2:最优值函数 是 Bellman's equation
的唯一解。
关于上面两个性质的证明在教材212页有详细过程,我就不照抄过来了。在证明中最核心的思想就是 压缩映射,理解了这一点就非常容易理解上面2个性质了。如果我们把式(2.10)DP算法的迭代操作看做是一个映射 的话,每次从stage k到k+1的计算相当于是对 Value function 做映射
的操作。
(2.11)
而这个映射 实际上是一个压缩映射(压缩映射的概念来自泛函分析 在收敛性证明 解存在性证明中经常会用到),大家只需要知道 压缩映射有如下性质:
(2.12)
这里的 norm 是 infinity norm
由此可以推出:
(2.13)
就表示经过
次压缩映射
之后的 Value function
3 Discounted problem
相似的,可以写出带有discount系数的Bellman's equation:
(3.1)
相似的,可以写出带有discount系数的DP迭代公式:
(3.2)
对比一下没有discount系数的SSP问题式(2.2)(2.3)我们可以发现上式中除了在Value function 上多加了一个 discount 系数 之外还去掉了 终止状态那一项。
实际上通过如下图所示就可以得到 discount 问题和没有discount问题的等价转化
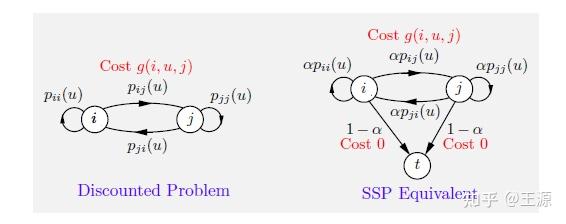
通过上图不难看出discount的意义相当于是加了一个cost为0的终止状态,并且其他状态到终止状态的概率为
那么有了这个等价转化,上面关于没有discount的性质和结论也都适用于带有discount的问题。在此就不再赘述了。
王源:【强化学习与最优控制】笔记(十一)无限时间动态规划分布式值迭代和策略迭代