

上一期笔记,忘记的童鞋可以复习一下:
王源:【强化学习与最优控制】笔记(十)无限时间动态规划和随机最短路问题如需教材的电子版可以从如下链接中获取:
Dimitri P. Bertsekas 强化学习2021版教材和视频课程推荐本笔记对应教材中第4章4.5-4.6的内容。由于电子版的内容不全,所以也推荐大家购买纸质版的,需购买教材的童鞋请点击:
这两个小节的内容主要有2个:1值迭代 这边会涉及一点点异步值迭代内容 事实上也可以看做是分布式系统的雏形;2策略迭代
1 分布式值迭代
先来复习一下 stochastic shortest path problem 的值迭代的公式如下所示:
(1.1)
加入discount的版本:
(1.2)
观察式(1.1)不难发现 这个迭代公式是对所有的状态都起作用的。每次在第 次迭代的时候 我们需要遍历所有的状态值 然后得到
的值函数。
我们自然而然会产生一个想法 能不能在每次迭代的时候 只更新一部分状态变量的值函数呢?答案自然是可以的。
考虑若有 个状态,将这
个状态构成一个划分
(任意2个集合相交为空集,并且任意一个集合非空,所有
个集合并起来等于全集)。然后将式(1.2)的值迭代公式可以等价的改写为如下式:
(1.3)
进一步改写上式可以得到分布式的值迭代公式如下所示:
(1.4)
其中 表示
需要迭代更新的时刻。
若 表明在各个子系统之间不存在由于通信所带来的延迟。若
则表明各个子系统之间存在通信延迟。
从式(1.4)中可知每次在时刻 到
的迭代过程中,由于有
的存在所以每次只有一部分状态的值函数在更新迭代,而不满足条件的状态的值函数依然会保持上一个时间步的值,即公式中的
下面我们考虑一种特殊情况:在每个时间步只更新一个状态的值函数(One state at a time iterations)。
为了方便起见我们假设在每个子系统里 都只包含唯一一个元素,由此即可用
表示值函数在stage
子系统
的值。由此易知 One state at a time iterations 的迭代公式如下所示:
(1.5)
其中我们用 算子来替代原来动态规划的递推公式。
从上式中我们可以看出 每次仅仅更新一个状态对应的值函数,而其它状态的值函数依旧保持上一个时刻的值不变。与(1.4)介绍的算法相比,(1.5)可以看做是(1.4)的一种特殊情况。(1.4)是选取一个子集在更新,而(1.5)每次只选一个元素更新。
要保证 分布式异步的值迭代算法的收敛性需要以下两个假设条件:
条件1:集合 要保证让所有的
被更新无穷次
条件2:
这2个条件从直观上还是比较好理解的。条件1保证了每个状态对应的值函数都要有充分的机会被更新。条件2实际上是保证了在更新迭代的过程中会将太久远的信息丢弃掉。最自然的理解方式就是 是随着
单调递增的(当然这个条件并不是收敛性所必须的条件)。有了这2个假设条件就可以证明 分布式异步值迭代算法能够保证让值函数收敛到最优。具体证明参考文献见教材 200页给出的参考文献。
分布式异步值迭代是非常有用的一个算法,首先它的计算量比完全进行值迭代要小,同时该算法天然就非常符合分布式的系统,例如无人机的集群。每个无人机之间都可以互相通信,但是通信是有代价的,同时通信可能会延迟。同时每个无人机都可以根据现有信息作出自己的决策。这个时候就非常适合采用分布式异步的值迭代算法来处理无人机集群的整体上的优化。在整个无人机集群中并没有一个上帝视角可以掌握所有无人机的状态信息,只是每个无人机根据自身掌握的部分信息单独决策。
2 策略迭代
策略迭代(Policy iteration)的基本思想是有一个初始的策略,然后通过对初始策略的评价来更新得到新的策略。其算法流程如下所示:
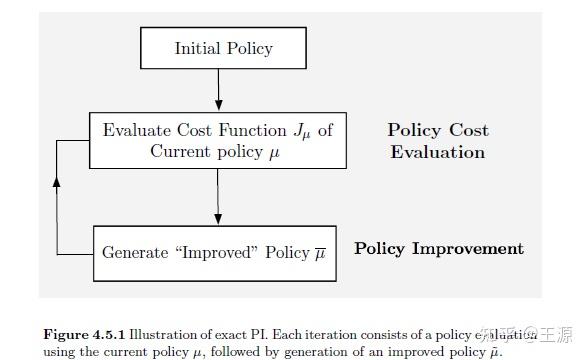
那么对于 stochastic shortest path problem,我们将上图所示的策略迭代过程写成公式有:
Step 1: 给定一个初始的Policy
Step 2: 通过如下式可以算出Value function来评价Policy
(2.1)
Step 3: 改进Policy 如下式所示:
(2.2)
Step 4: 返回到Step 2继续循环,除非满足以下条件可终止迭代
上面的算法流程是针对没有discount系数的,含有discount系数的话就将式(2.1)(2.2)替换成含有discount的迭代公式即可,其它流程保持不变。
如上所述的 策略迭代算法 具有如下性质:
并且最终可以收敛到最优的 Policy。
下面我们证明这个性质:
首先定义 是一个 policy,
是在
的基础上通过策略迭代算法得到新的 policy,所以我们只需证明
即可。
由 Bellman equations 可知:
(2.3)
根据式(2.2)可知 是最优的 policy 所以有
(2.4)
定义
(2.5)
由式(2.4)可知 ,结合上式可得:
(2.6)
进一步可得:
(2.7)
基于上式类似地递推下去可得:
(2.8)
由此可得 (2.9)
这个定理还证明了收敛性,但是我没完全看懂收敛性的证明。如果有小伙伴看懂了可以评论区提醒我一下。
策略迭代这一小节后边还介绍了2大块内容分别是Multistep Lookahead 和 Q function 的迭代,这块内容和前面基本大同小异 因此我们这里 也就不做过多的介绍了。
下一期笔记:
王源:【强化学习与最优控制】笔记(十二)无限时间值函数近似